Clear Sky Science · es
El aprendizaje no supervisado revela nuevas proteínas asociadas a enfermedades en datos proteómicos humanos de alta dimensión
Pistas en la sangre ocultas a simple vista
Nuestra sangre contiene multitud de proteínas que reflejan silenciosamente lo que ocurre dentro de nuestros cuerpos mucho antes de que nos encontremos enfermos. Los médicos ya usan un puñado de estas proteínas como pruebas, pero la tecnología moderna puede medir miles a la vez. Este estudio plantea una pregunta sencilla con implicaciones importantes: si dejamos que un ordenador explore libremente estos enormes mapas de proteínas sanguíneas sin decirle qué buscar, ¿puede descubrir nuevas relaciones con enfermedades que ni siquiera se nos ocurrió testar?
Dejar que los datos hablen por sí mismos
La mayoría de los algoritmos médicos se entrenan con etiquetas claras como “sano” o “tiene hipertensión”. Ese enfoque es potente, pero puede pasar por alto patrones inesperados, especialmente cuando hay miles de medidas por persona. Aquí, los investigadores toman la ruta opuesta: usan aprendizaje “no supervisado”, que agrupa a las personas exclusivamente por similitud en sus patrones proteicos sanguíneos, sin saber quién tiene qué enfermedad. El equipo trabajó con un recurso enorme, el UK Biobank, centrado en casi 53 000 participantes cuya sangre se analizó para 2 923 proteínas distintas. Su objetivo fue ver si las agrupaciones naturales en este océano de números se alineaban con enfermedades reales y revelaban nuevos candidatos entre las proteínas.
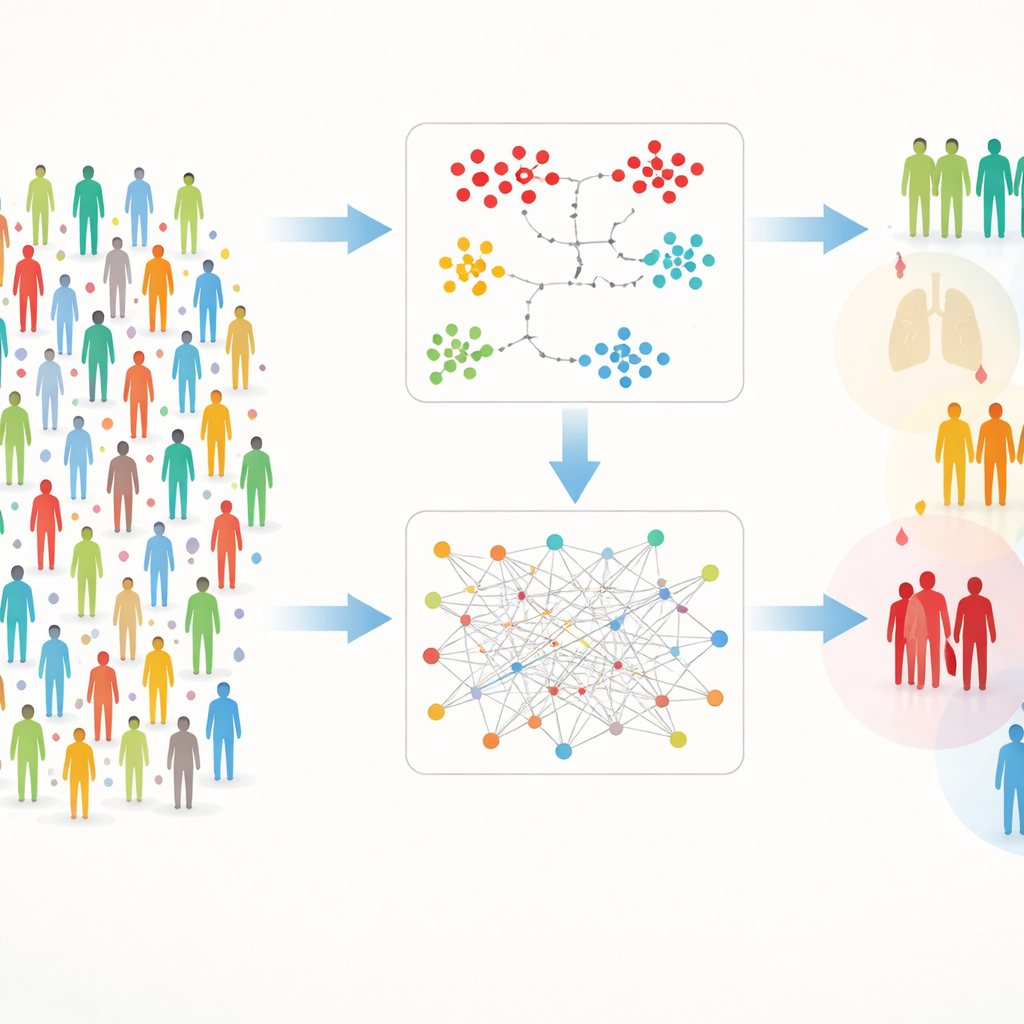
Dos vías para encontrar grupos ocultos
Trabajar con datos tan ricos conlleva obstáculos prácticos: a veces faltan medidas y el simple número de proteínas puede ahogar las señales. Para abordar esto, los autores construyeron un marco de doble vía al que llaman DIRAM/COD. Una vía (DIRAM) recorta los datos para evitar valores faltantes, reduce la complejidad a dos dimensiones y luego busca “islas” densas de personas similares. La otra vía (DIRCOD) primero rellena los valores ausentes con estimaciones cuidadosas y luego utiliza un método de detección de comunidades tomado de la ciencia de redes para detectar grupos. Ambas vías se refinan repetidamente, dando finalmente 55 clústeres distintos de participantes cuyos perfiles proteicos sanguíneos difieren de manera significativa.
Clústeres que reflejan enfermedades reales
Una vez definidos los clústeres, el equipo comprobó cómo se distribuían la edad, el sexo y, crucialmente, los diagnósticos médicos entre ellos. Ciertos clústeres estaban enriquecidos en condiciones graves como insuficiencia orgánica, trasplantes y cáncer, lo que sugiere que sus firmas proteicas capturaban la biología de pacientes muy enfermos. Los autores se centraron después en tres patologías: enfermedad celíaca, hipertensión y leucemia. Preguntaron qué proteínas tendían a estar inusualmente altas o bajas en los clústeres donde estas enfermedades eran más comunes. Al “recrear” grupos ricos en enfermedad usando solo esas proteínas y umbrales simples, demostraron que esos patrones proteicos seguían de forma consistente las probabilidades de enfermedad, incluso al mezclar participantes de todo el estudio.
Nuevos sospechosos proteicos y relaciones cambiantes
Este enfoque hizo más que confirmar actores conocidos; puso de relieve nuevos candidatos. Para la hipertensión, destacaron proteínas como UBE2L6, HNRNPUL1 y BECN1, todas previamente vinculadas a problemas vasculares o cardiacos en otros trabajos. Para la enfermedad celíaca, IGF2BP3 surgió como especialmente importante, encajando con indicios previos de que ayuda a mantener la barrera intestinal, junto con otras proteínas prometedoras como NRXN3 y CACNB1. En los clústeres relacionados con la leucemia, varias proteínas, incluidas LRCH4, WDR46, SERPINB1 y NUB1, mostraron un comportamiento alterado. No solo variaron sus niveles, sino que cambió la forma en que subían y bajaban conjuntamente, lo que sugiere una reconfiguración de los sistemas de control internos del cuerpo en el cáncer y las enfermedades autoinmunes.
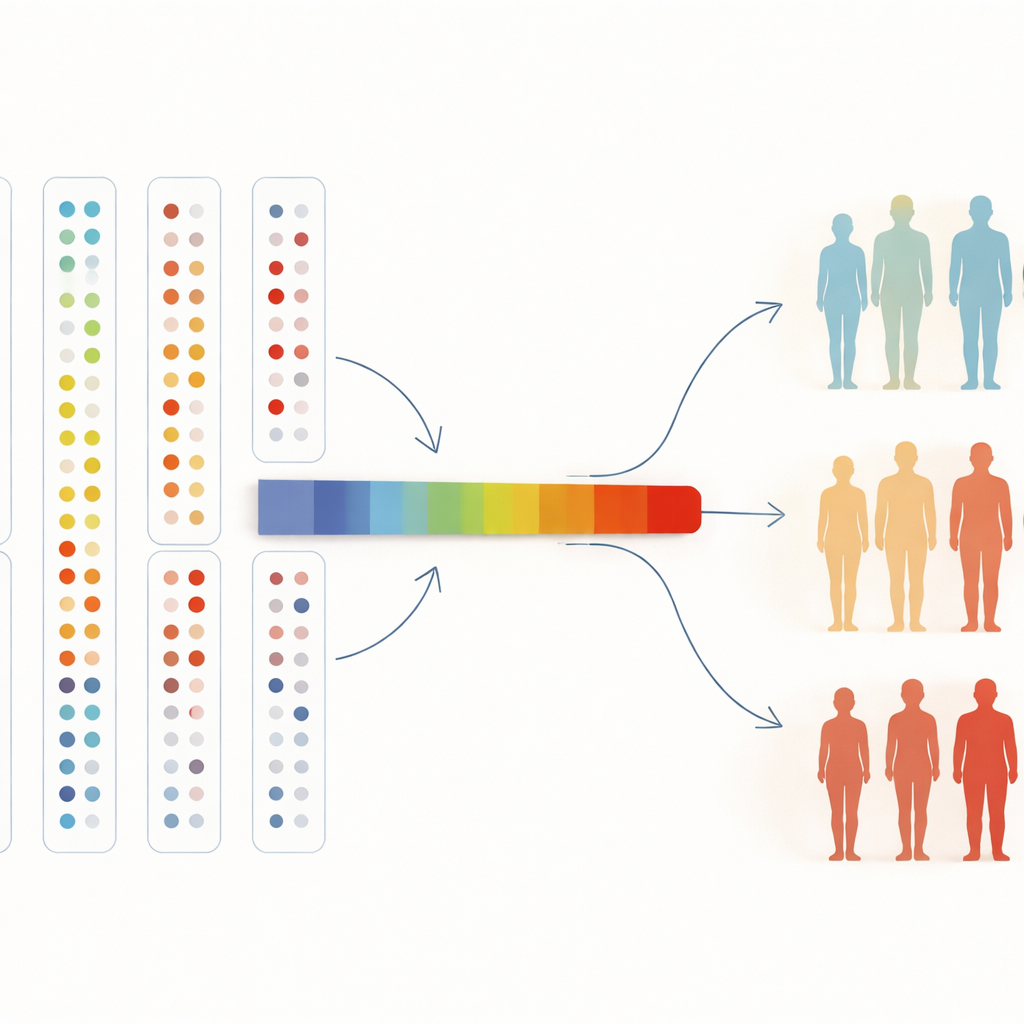
De los mapas sanguíneos a la medicina del futuro
Para dar sentido a muchas proteínas a la vez, los investigadores también las condensaron en un único “eje” que resume los cambios de patrón globales. A lo largo de este eje, las probabilidades de tener hipertensión o enfermedad celíaca aumentaron de forma constante, y esta tendencia se mantuvo incluso cuando extendieron el análisis a todos los participantes del estudio. Para un público no especializado, la conclusión es clara: dejando que los algoritmos ordenen libremente a las personas según miles de proteínas sanguíneas, podemos encontrar grupos naturales relacionados con la salud, confirmar marcadores conocidos de enfermedad y descubrir otros nuevos. A medida que los biobancos crezcan hasta cientos de miles de personas y aún más proteínas, este tipo de exploración no supervisada podría ayudar a los médicos a detectar la enfermedad antes, entender por qué algunas personas enferman y otras no, y señalar nuevos objetivos para futuros tratamientos.
Cita: Bernard, E., Wang, Y., Chen, M. et al. Unsupervised learning reveals novel disease-associated proteins in high-dimensional human proteomic data. Sci Rep 16, 10185 (2026). https://doi.org/10.1038/s41598-026-41385-7
Palabras clave: proteínas sanguíneas, aprendizaje no supervisado, biomarcadores, medicina de precisión, riesgo de enfermedad