Clear Sky Science · fr
L’apprentissage non supervisé révèle de nouvelles protéines associées à la maladie dans des données protéomiques humaines de haute dimension
Indices sanguins cachés en évidence
Notre sang regorge de protéines qui reflètent discrètement ce qui se passe dans notre organisme bien avant que nous ne ressentions des symptômes. Les médecins utilisent déjà une poignée de ces protéines comme tests, mais la technologie moderne peut désormais en mesurer des milliers simultanément. Cette étude pose une question simple aux implications importantes : si l’on laisse un ordinateur explorer librement ces vastes cartographies protéiques sanguines sans lui indiquer quoi rechercher, peut-il découvrir de nouveaux liens avec des maladies que nous n’avions pas envisagé de tester ?
Laisser parler les données
La plupart des algorithmes médicaux sont entraînés avec des étiquettes claires telles que « en bonne santé » ou « souffre d’hypertension ». Cette approche est puissante mais peut manquer des motifs inattendus, notamment lorsqu’on dispose de milliers de mesures par personne. Ici, les chercheurs empruntent la voie inverse : ils utilisent l’apprentissage « non supervisé », qui regroupe les personnes uniquement selon la similarité de leurs profils protéiques sanguins, sans connaître leurs diagnostics. L’équipe a travaillé avec une ressource immense, l’UK Biobank, en se concentrant sur près de 53 000 participants dont le sang avait été testé pour 2 923 protéines différentes. Leur objectif était de vérifier si des regroupements naturels dans cet océan de chiffres correspondent à des maladies réelles et révéler de nouveaux suspects parmi les protéines.
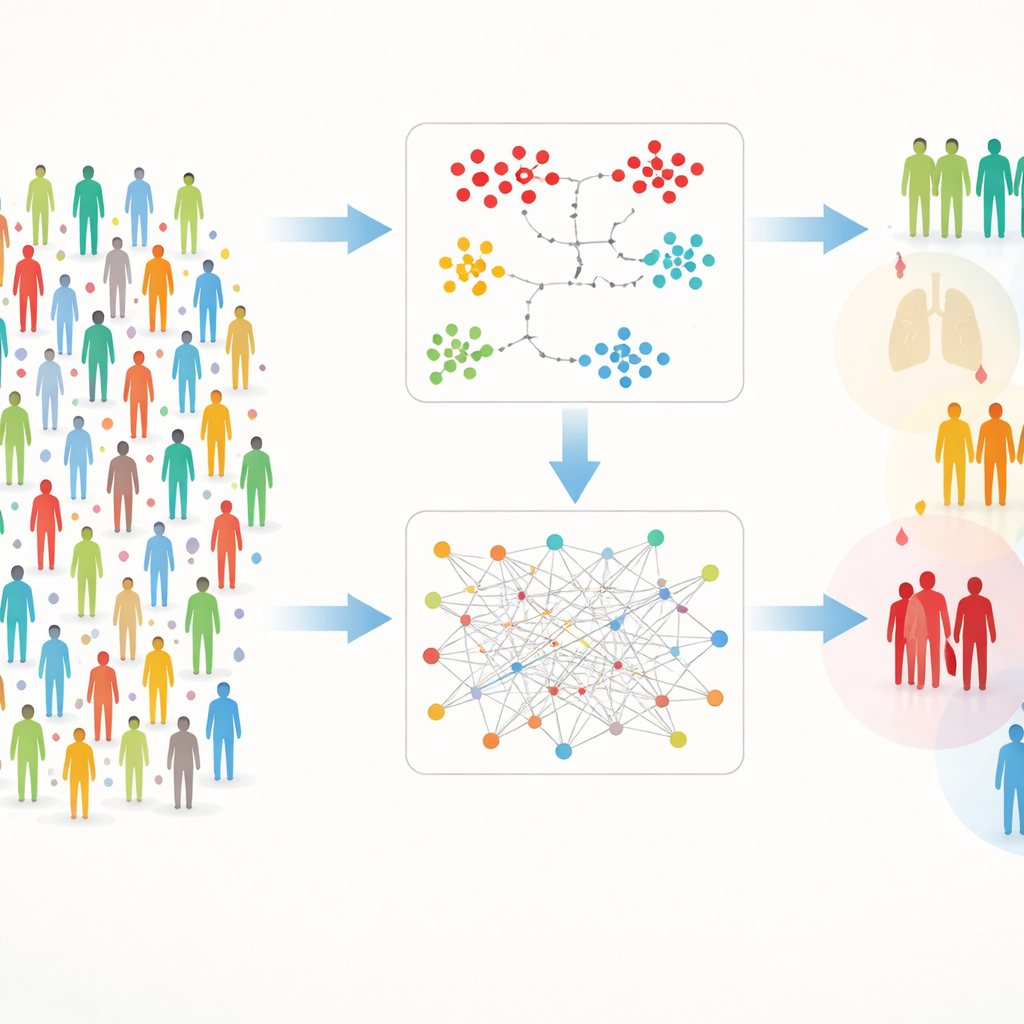
Deux voies pour trouver des groupes cachés
Travailler avec des données aussi riches implique des difficultés pratiques : certaines mesures sont parfois manquantes, et le nombre élevé de protéines peut noyer les signaux. Pour y remédier, les auteurs ont construit un cadre à double voie qu’ils appellent DIRAM/COD. Une voie (DIRAM) découpe les données pour éviter les valeurs manquantes, réduit la complexité à deux dimensions puis cherche des « îlots » denses de personnes similaires. L’autre voie (DIRCOD) comble d’abord les valeurs manquantes par des estimations soignées, puis utilise une méthode de détection de communautés empruntée aux sciences des réseaux pour identifier des groupes. Les deux voies sont affinées de manière itérative, conduisant finalement à 55 clusters distincts de participants dont les empreintes protéiques sanguines diffèrent de façon significative.
Des clusters qui reflètent de vraies maladies
Une fois les clusters définis, l’équipe a examiné la répartition de l’âge, du sexe et, surtout, des diagnostics médicaux à travers eux. Certains clusters étaient enrichis en affections graves comme l’insuffisance d’organe, les greffes et le cancer, ce qui suggère que leurs signatures protéiques captent la biologie de patients très malades. Les auteurs se sont ensuite concentrés sur trois conditions : la maladie cœliaque, l’hypertension et la leucémie. Ils ont cherché quelles protéines avaient tendance à être anormalement élevées ou basses dans les clusters où ces maladies étaient plus fréquentes. En « reconstituant » des groupes riches en maladies à partir de ces seules protéines et de seuils simples, ils ont montré que ces motifs protéiques suivaient fortement les chances d’avoir la maladie — y compris lorsque l’on mélangeait des participants provenant de l’ensemble de l’étude.
Nouveaux candidats protéiques et relations changeantes
Cette approche n’a pas seulement confirmé des acteurs connus ; elle a mis en lumière de nouveaux candidats. Pour l’hypertension, des protéines telles que UBE2L6, HNRNPUL1 et BECN1 se sont démarquées, toutes auparavant liées à des problèmes vasculaires ou cardiaques dans d’autres travaux. Pour la maladie cœliaque, IGF2BP3 est apparue comme particulièrement importante, en accord avec des indications antérieures selon lesquelles elle participe au maintien de la barrière intestinale, aux côtés d’autres protéines prometteuses comme NRXN3 et CACNB1. Dans les clusters associés à la leucémie, plusieurs protéines — notamment LRCH4, WDR46, SERPINB1 et NUB1 — présentaient des comportements altérés. Non seulement leurs niveaux étaient différents, mais la manière dont elles variaient ensemble avait changé, suggérant une reconfiguration des systèmes de contrôle internes de l’organisme dans le cancer et les maladies auto-immunes.
Des cartes sanguines à la médecine de demain
Pour rendre compte de nombreux changements protéiques simultanément, les chercheurs les ont aussi compressés en un « axe » unique résumant les variations globales de profils. Le long de cet axe, la probabilité d’avoir de l’hypertension ou la maladie cœliaque augmentait régulièrement, et cette tendance se maintenait même lorsque l’analyse était étendue à l’ensemble des participants. Pour un non-spécialiste, la conclusion est simple : en laissant les algorithmes trier librement les personnes sur la base de milliers de protéines sanguines, on peut identifier des groupes naturels liés à la santé, confirmer des marqueurs de maladie connus et en découvrir de nouveaux. À mesure que les biobanques atteindront des centaines de milliers de personnes et mesureront encore plus de protéines, ce type d’exploration non supervisée pourrait aider les médecins à détecter les maladies plus tôt, comprendre pourquoi certaines personnes tombent malades et d’autres non, et pointer de nouvelles cibles pour des traitements futurs.
Citation: Bernard, E., Wang, Y., Chen, M. et al. Unsupervised learning reveals novel disease-associated proteins in high-dimensional human proteomic data. Sci Rep 16, 10185 (2026). https://doi.org/10.1038/s41598-026-41385-7
Mots-clés: protéines sanguines, apprentissage non supervisé, biomarqueurs, médecine de précision, risque de maladie