Clear Sky Science · pt
Aprendizado não supervisionado revela novas proteínas associadas a doenças em dados proteômicos humanos de alta dimensionalidade
Pistas no Sangue Ocultas à Vista
Nosso sangue está repleto de proteínas que refletem discretamente o que acontece dentro de nossos corpos muito antes de sentirmos os sintomas. Médicos já usam um pequeno conjunto dessas proteínas como exames, mas a tecnologia moderna permite medir milhares de uma só vez. Este estudo faz uma pergunta simples com grandes implicações: se deixarmos um computador explorar livremente esses enormes mapas de proteínas sanguíneas sem dizer o que procurar, ele pode descobrir novas ligações com doenças que nem sequer imaginávamos testar?
Deixando os Dados Falarem por Si
A maioria dos algoritmos médicos é treinada com rótulos claros como “saudável” ou “tem hipertensão”. Essa abordagem é poderosa, mas pode perder padrões inesperados, especialmente quando confrontada com milhares de medidas por pessoa. Aqui, os pesquisadores seguem o caminho oposto: usam aprendizado “não supervisionado”, que agrupa pessoas puramente pela similaridade em seus perfis proteicos sanguíneos, sem saber quem tem quais doenças. A equipe trabalhou com um recurso enorme, o UK Biobank, focando em quase 53.000 participantes cujos sangues foram testados para 2.923 proteínas diferentes. O objetivo foi verificar se agrupamentos naturais nesse oceano de números se alinhariam com doenças reais e revelariam novos suspeitos entre as proteínas.
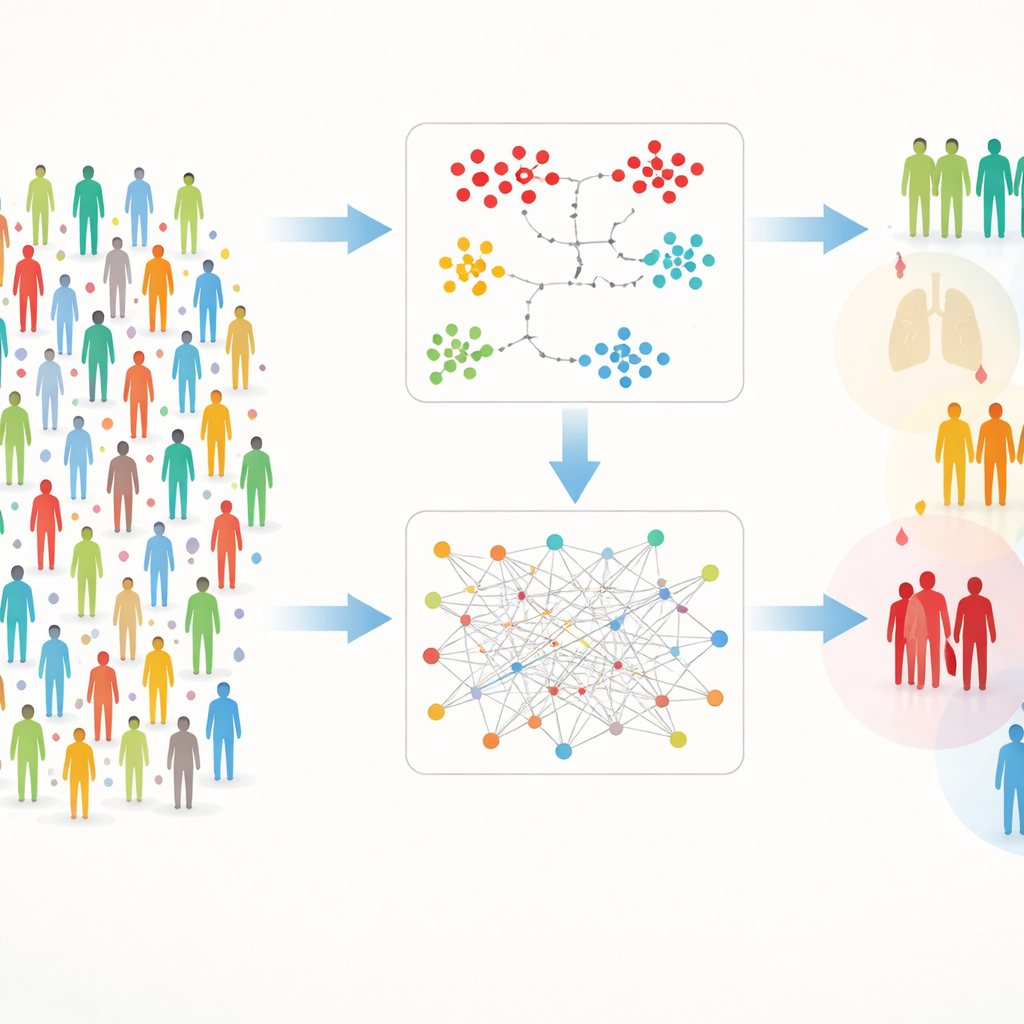
Dois Caminhos para Encontrar Grupos Ocultos
Trabalhar com dados tão ricos traz desafios práticos: às vezes faltam medições, e o simples número de proteínas pode ofuscar sinais. Para lidar com isso, os autores construíram uma estrutura de dupla via que chamam de DIRAM/COD. Uma via (DIRAM) fatia os dados para evitar valores faltantes, reduz a complexidade para duas dimensões e então procura “ilhas” densas de pessoas semelhantes. A outra via (DIRCOD) primeiro preenche valores ausentes com estimativas cuidadosas e, em seguida, usa um método de detecção de comunidades emprestado da ciência de redes para identificar grupos. Ambas as vias são refinadas repetidamente, produzindo ao final 55 agrupamentos distintos de participantes cujas impressões digitais proteicas sanguíneas diferem de maneiras significativas.
Agrupamentos que Espelham Doenças Reais
Uma vez definidos os agrupamentos, a equipe examinou como idade, sexo e, crucialmente, diagnósticos médicos se distribuíam por eles. Certos clusters mostraram enriquecimento por condições graves, como insuficiência de órgãos, transplantes e câncer, sugerindo que suas assinaturas proteicas capturavam a biologia de pacientes muito doentes. Os autores então focaram em três condições: doença celíaca, hipertensão e leucemia. Perguntaram quais proteínas tendiam a ser incomumente altas ou baixas em clusters onde essas doenças eram mais frequentes. Ao “recriar” grupos ricos em doença usando apenas essas proteínas e limites simples, mostraram que esses padrões proteicos acompanhavam fortemente as chances de doença — mesmo ao misturar participantes de todo o estudo.
Novos Suspeitos Proteicos e Relações que Mudam
Essa abordagem fez mais do que confirmar atores já conhecidos; ela destacou novos candidatos. Para hipertensão, proteínas como UBE2L6, HNRNPUL1 e BECN1 se destacaram, todas previamente relacionadas a problemas vasculares ou cardíacos em outros trabalhos. Para a doença celíaca, IGF2BP3 surgiu como especialmente relevante, compatível com indícios anteriores de que ajuda a manter a barreira intestinal, ao lado de outras proteínas promissoras como NRXN3 e CACNB1. Em clusters relacionados à leucemia, várias proteínas, incluindo LRCH4, WDR46, SERPINB1 e NUB1, apresentaram comportamento alterado. Não só seus níveis diferiram, mas também a forma como variavam em conjunto mudou, sugerindo uma reconfiguração dos sistemas de controle internos do corpo em câncer e doenças autoimunes.
Dos Mapas Sanguíneos à Medicina do Futuro
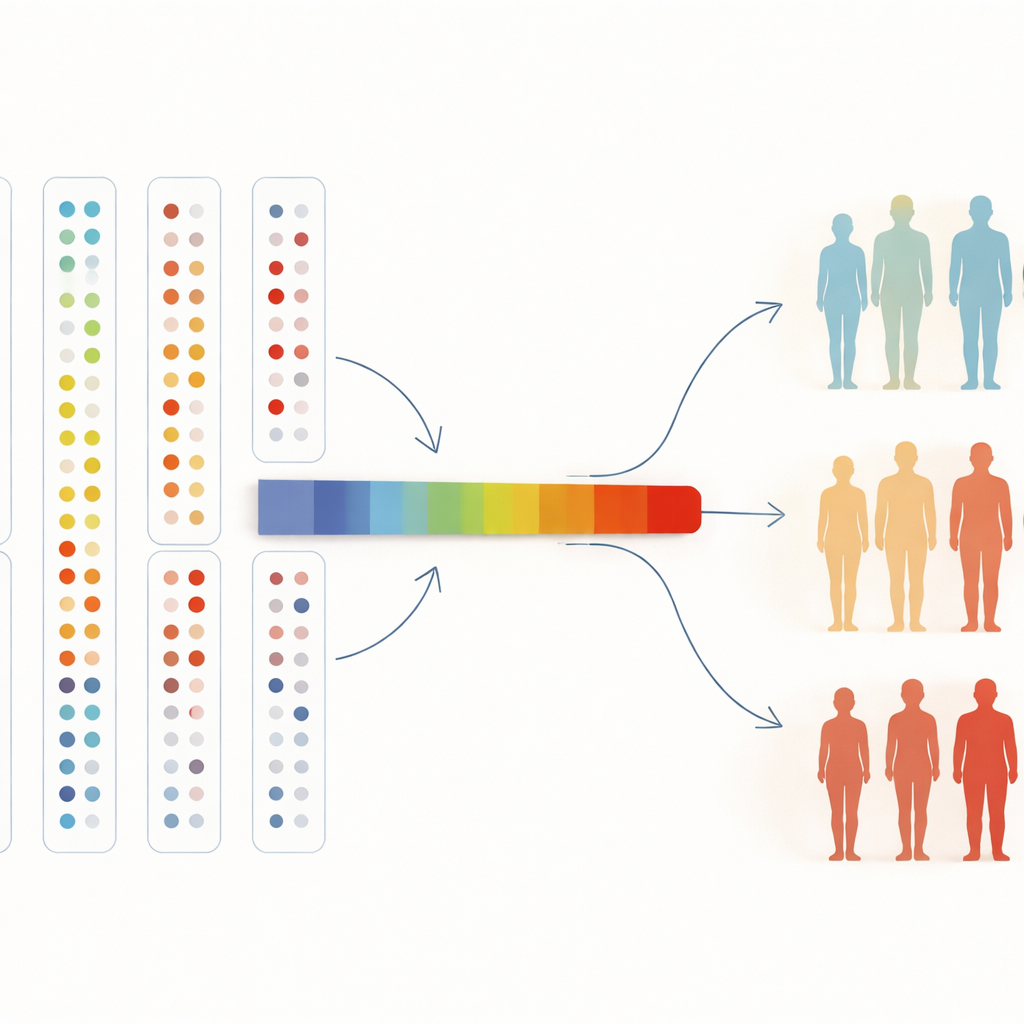
Para interpretar muitas proteínas de uma só vez, os pesquisadores também as comprimiram em um único “eixo” que resume mudanças de padrão gerais. Ao longo desse eixo, as chances de ter hipertensão ou doença celíaca aumentaram de forma constante, e essa tendência se manteve mesmo quando estenderam a análise a todos os participantes do estudo. Para um leitor não especializado, a conclusão é direta: ao permitir que algoritmos organizem livremente pessoas com base em milhares de proteínas sanguíneas, podemos encontrar agrupamentos naturais relacionados à saúde, confirmar marcadores de doenças conhecidos e descobrir novos. À medida que biobancos crescerem para centenas de milhares de pessoas e ainda mais proteínas, esse tipo de exploração não supervisionada pode ajudar médicos a detectar doenças mais cedo, entender por que alguns adoecem enquanto outros não e apontar alvos novos para tratamentos futuros.
Citação: Bernard, E., Wang, Y., Chen, M. et al. Unsupervised learning reveals novel disease-associated proteins in high-dimensional human proteomic data. Sci Rep 16, 10185 (2026). https://doi.org/10.1038/s41598-026-41385-7
Palavras-chave: proteínas sanguíneas, aprendizado não supervisionado, biomarcadores, medicina de precisão, risco de doença