Clear Sky Science · sv
Oövervakad inlärning avslöjar nya sjukdomsassocierade proteiner i högdimensionella mänskliga proteomdata
Blodets ledtrådar dolda i fullt ljus
Vårt blod är fullt av proteiner som tyst speglar vad som händer i kroppen långt innan vi känner oss sjuka. Läkare använder redan ett fåtal av dessa proteiner som tester, men modern teknik kan nu mäta tusentals samtidigt. Denna studie ställer en enkel fråga med stora följder: om vi låter en dator fritt utforska dessa massiva kartor över blodproteiner utan att tala om vad den ska leta efter, kan den då upptäcka nya kopplingar till sjukdomar som vi inte ens tänkte testa?
Låta data tala för sig själva
De flesta medicinska algoritmer tränas med tydliga etiketter som ”frisk” eller ”har högt blodtryck”. Den metoden är kraftfull men kan missa oväntade mönster, särskilt när den ställs inför tusentals mätningar per person. Här tar forskarna motsatt väg: de använder oövervakad inlärning, som grupperar människor enbart efter likhet i deras blodproteinsmönster, utan att veta vem som har vilken sjukdom. Teamet arbetade med en enorm resurs, UK Biobank, och fokuserade på nästan 53 000 deltagare vars blod hade testats för 2 923 olika proteiner. Målet var att se om naturliga grupperingarna i detta hav av siffror skulle stämma överens med verkliga sjukdomar och avslöja nya misstänkta proteiner.
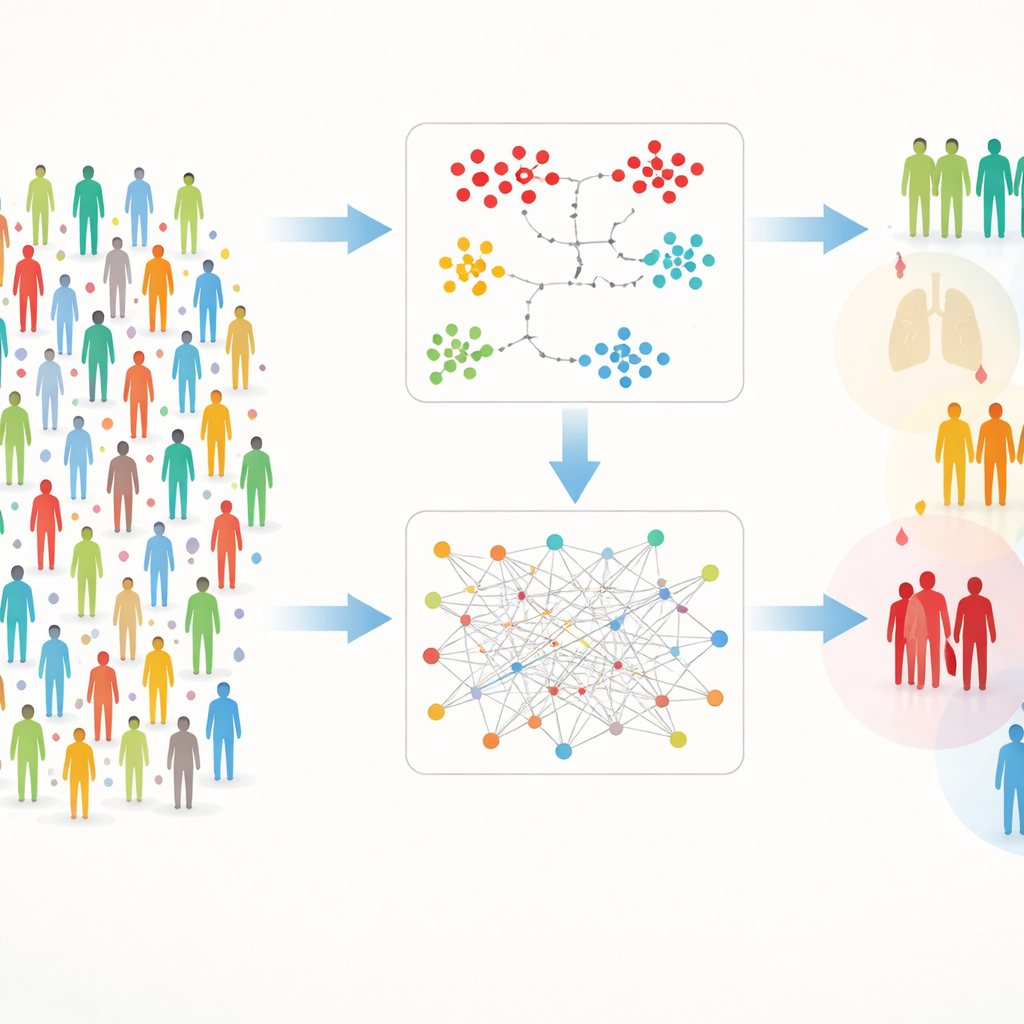
Två vägar för att hitta dolda grupper
Att arbeta med så rik data medför praktiska hinder: mätvärden saknas ibland och det stora antalet proteiner kan dränka signaler. För att hantera detta byggde författarna en tvåspårsram som de kallar DIRAM/COD. Ett spår (DIRAM) skivar upp data för att undvika saknade värden, reducerar komplexiteten till två dimensioner och letar sedan efter täta ”öar” av liknande individer. Det andra spåret (DIRCOD) fyller först i saknade värden med noggranna uppskattningar och använder därefter en gemenskapsidentifieringsmetod lånad från nätverksvetenskap för att upptäcka grupper. Båda spåren finslipas upprepade gånger och resulterade slutligen i 55 distinkta kluster av deltagare vars blodproteinavtryck skiljde sig på meningsfulla sätt.
Kluster som speglar verkliga sjukdomar
När klustren hade definierats undersökte teamet hur ålder, kön och, avgörande, medicinska diagnoser var fördelade mellan dem. Vissa kluster var berikade för allvarliga tillstånd såsom organsvikt, transplanterade patienter och cancer, vilket tyder på att deras proteinsignaturer fångade biologin hos mycket sjuka patienter. Författarna zoomade sedan in på tre tillstånd: celiaki, hypertoni och leukemi. De undersökte vilka proteiner som tenderade att vara ovanligt höga eller låga i kluster där dessa sjukdomar var vanligare. Genom att ”återskapa” sjukdomsrika grupper med enbart dessa proteiner och enkla trösklar visade de att dessa proteinmönster starkt följde sjukdomssannolikheten — även när deltagare blandades över hela studien.
Nya proteinmisstänkta och förskjutna relationer
Dessa metoder gjorde mer än att bekräfta bekanta aktörer; de lyfte fram nya kandidater. För hypertoni stack proteiner som UBE2L6, HNRNPUL1 och BECN1 ut, alla tidigare kopplade till blodkärls- eller hjärtproblem i annan forskning. För celiaki framträdde IGF2BP3 som särskilt viktig, vilket stämmer med tidigare antydningar om att det hjälper till att bevara tarmens barriär, tillsammans med andra lovande proteiner som NRXN3 och CACNB1. I leukemirelaterade kluster visade flera proteiner, inklusive LRCH4, WDR46, SERPINB1 och NUB1, förändrat beteende. Inte bara var deras nivåer annorlunda, utan även sättet de ökade och minskade tillsammans förändrades, vilket antyder en omkoppling av kroppens interna styrsystem vid cancer och autoimmuna sjukdomar.
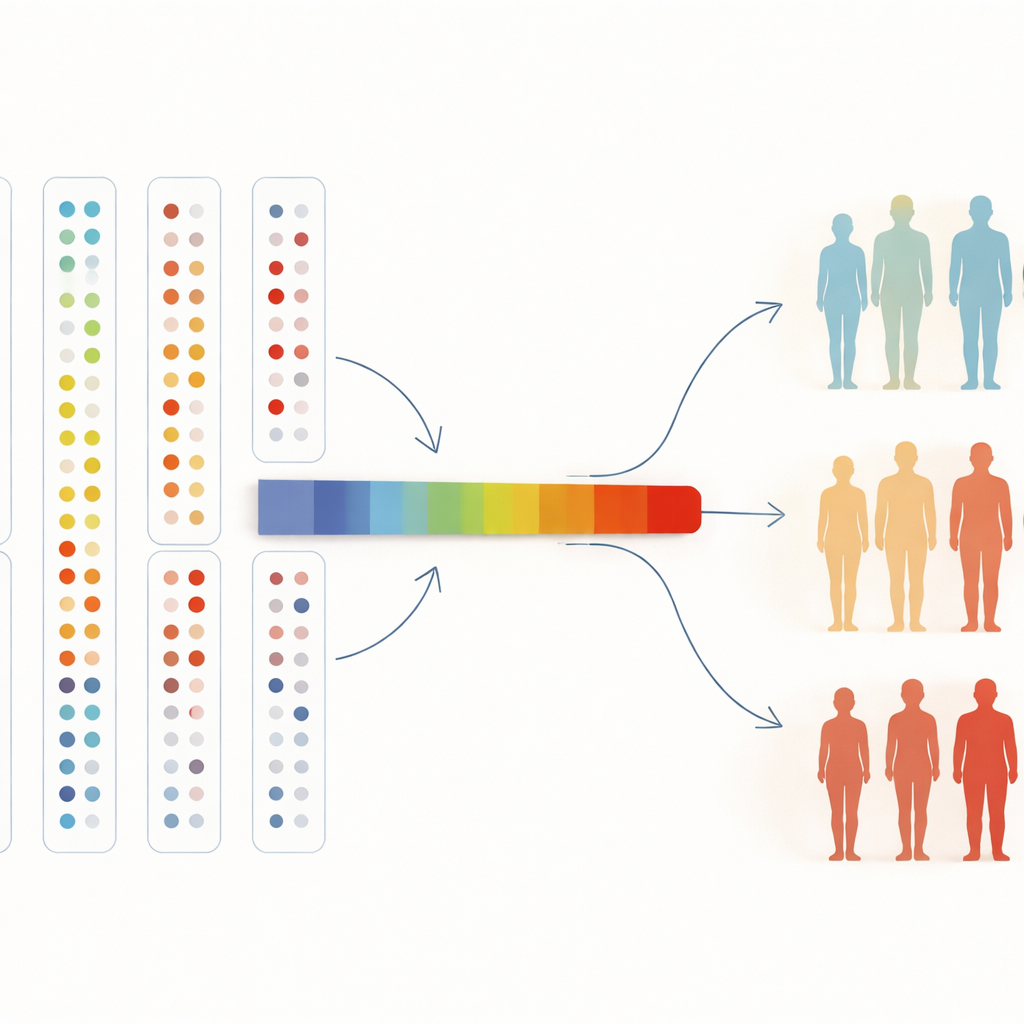
Från blodkartor till framtidens medicin
För att förstå många proteiner samtidigt komprimerade forskarna dem också till en enda ”axel” som summerar övergripande mönsterförändringar. Längs denna axel ökade sannolikheten att ha hypertoni eller celiaki stadigt, och denna trend höll i sig även när de utvidgade analysen till alla i studien. För en icke-specialist är slutsatsen enkel: genom att låta algoritmer fritt sortera människor baserat på tusentals blodproteiner kan vi hitta naturliga hälsorelaterade grupper, bekräfta kända sjukdomsmarkörer och upptäcka nya. När biobanker växer till hundratusentals deltagare och ännu fler proteiner kan denna typ av oövervakad utforskning hjälpa läkare upptäcka sjukdom tidigare, förstå varför vissa blir sjuka medan andra inte gör det och peka ut nya mål för framtida behandlingar.
Citering: Bernard, E., Wang, Y., Chen, M. et al. Unsupervised learning reveals novel disease-associated proteins in high-dimensional human proteomic data. Sci Rep 16, 10185 (2026). https://doi.org/10.1038/s41598-026-41385-7
Nyckelord: blodproteiner, oövervakad inlärning, biomarkörer, precisionmedicin, sjukdomsrisk