Clear Sky Science · nl
Ongecontroleerd leren onthult nieuwe ziektegerelateerde eiwitten in hoog-dimensionele menselijke proteomische data
Bloedsignalen die in het volle zicht verborgen liggen
Ons bloed bevat talloze eiwitten die stilletjes weergeven wat er in ons lichaam gebeurt, vaak lang voordat we ons ziek voelen. Artsen gebruiken al een handvol van deze eiwitten als tests, maar moderne technologie kan nu duizenden tegelijk meten. Deze studie stelt een eenvoudige vraag met grote implicaties: als we een computer vrij laten onderzoeken deze enorme kaarten van bloedeiwitten zonder te zeggen waarnaar gezocht moet worden, kan die dan nieuwe verbanden met ziektes ontdekken die we zelf niet eens getest zouden hebben?
De data voor zichzelf laten spreken
De meeste medische algoritmen worden getraind met duidelijke labels zoals “gezond” of “heeft hypertensie.” Die aanpak is krachtig maar kan onverwachte patronen missen, vooral wanneer er duizenden metingen per persoon zijn. Hier slaan de onderzoekers de omgekeerde weg in: ze gebruiken “ongecontroleerd” leren, dat mensen puur groepeert op basis van gelijkenis in hun bloedproteïnepatronen, zonder te weten wie welke ziekte heeft. Het team werkte met een enorme bron, de UK Biobank, en richtte zich op bijna 53.000 deelnemers van wie het bloed op 2.923 verschillende eiwitten was getest. Hun doel was te zien of natuurlijke groeperingen in deze oceaan van cijfers zouden samenvallen met echte ziekten en nieuwe verdachte eiwitten zouden onthullen.
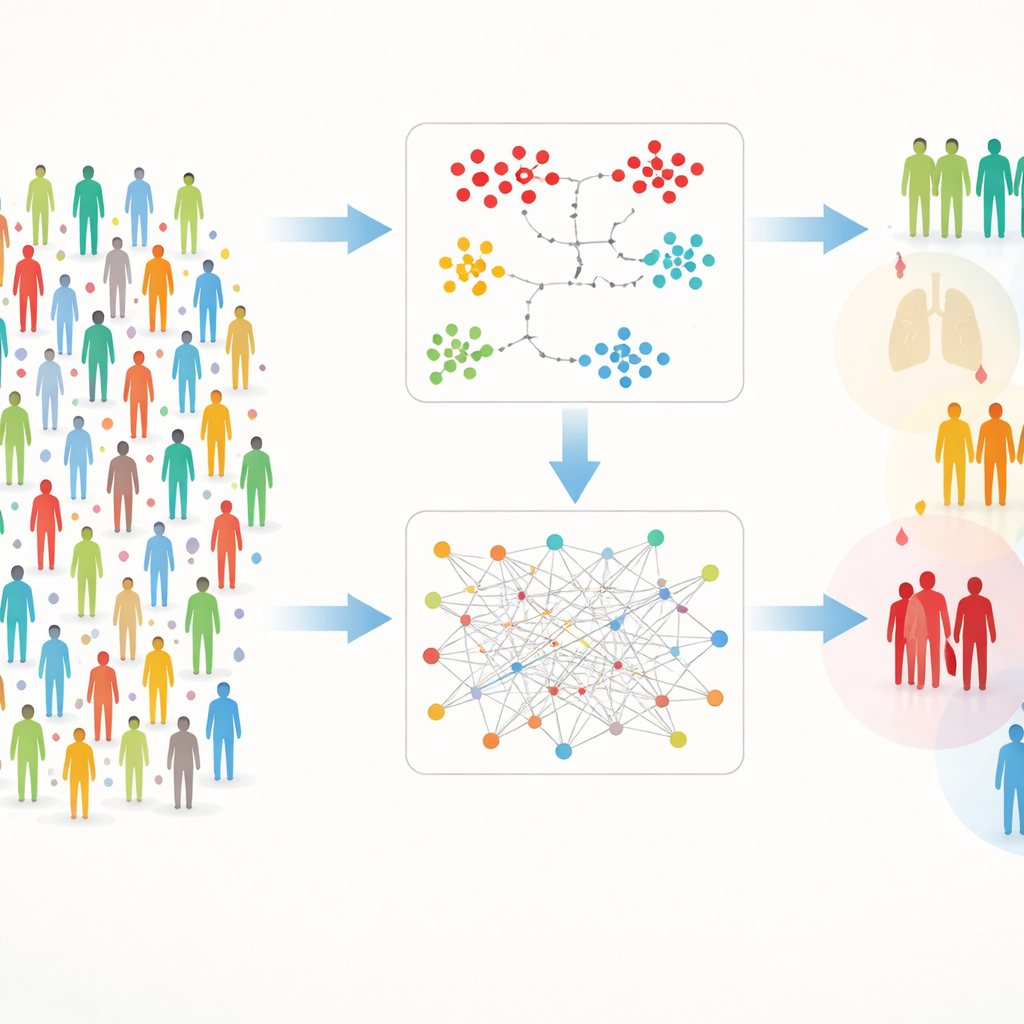
Twee wegen naar het vinden van verborgen groepen
Werken met zulke rijke data brengt praktische obstakels met zich mee: metingen ontbreken soms, en het enorme aantal eiwitten kan signalen overstemmen. Om dit aan te pakken bouwden de auteurs een tweesporig kader dat ze DIRAM/COD noemen. Het ene spoor (DIRAM) snijdt de data om ontbrekende waarden te vermijden, reduceert de complexiteit tot twee dimensies en zoekt vervolgens naar dichte “eilanden” van soortgelijke mensen. Het andere spoor (DIRCOD) vult eerst ontbrekende waarden aan met zorgvuldige schattingen en gebruikt daarna een gemeenschapsvindende methode uit de netwerkscience om groepen te detecteren. Beide sporen worden herhaaldelijk verfijnd, wat uiteindelijk 55 onderscheiden clusters van deelnemers opleverde met betekenisvol verschillende bloedeiwitvingerafdrukken.
Clusters die echte ziektes weerspiegelen
Zodra de clusters waren gedefinieerd, controleerde het team hoe leeftijd, geslacht en, cruciaal, medische diagnoses over hen waren verdeeld. Bepaalde clusters waren verrijkt voor ernstige aandoeningen zoals orgaanfalen, transplantaties en kanker, wat suggereert dat hun eiwitsignaturen de biologie van zeer zieke patiënten vastlegden. De auteurs zoomden vervolgens in op drie aandoeningen: coeliakie, hypertensie en leukemie. Ze onderzochten welke eiwitten de neiging hadden abnormaal hoog of laag te zijn in clusters waar deze ziekten vaker voorkwamen. Door ziekterijke groepen te “hercreëren” met alleen die eiwitten en eenvoudige drempels, lieten ze zien dat deze eiwitpatronen sterk samenhingen met ziektetekenkans — zelfs wanneer deelnemers uit de hele studie werden gemixt.
Nieuwe eiwitverdachten en verschuivende relaties
Deze benadering deed meer dan bekende actoren bevestigen; ze zette nieuwe kandidaten in de schijnwerpers. Voor hypertensie vielen eiwitten zoals UBE2L6, HNRNPUL1 en BECN1 op, die in eerdere studies al met vaat- of hartproblemen waren verbonden. Voor coeliakie kwam IGF2BP3 naar voren als bijzonder belangrijk, wat past bij eerdere aanwijzingen dat het helpt de darmbarrière te behouden, naast andere veelbelovende eiwitten zoals NRXN3 en CACNB1. In leukemie-gerelateerde clusters vertoonden meerdere eiwitten, waaronder LRCH4, WDR46, SERPINB1 en NUB1, veranderde gedragingen. Niet alleen waren hun niveaus anders, ook de manier waarop ze samen stegen en daalden veranderde, wat wijst op een herschakeling van de interne controlesystemen van het lichaam bij kanker en auto-immuunziekten.
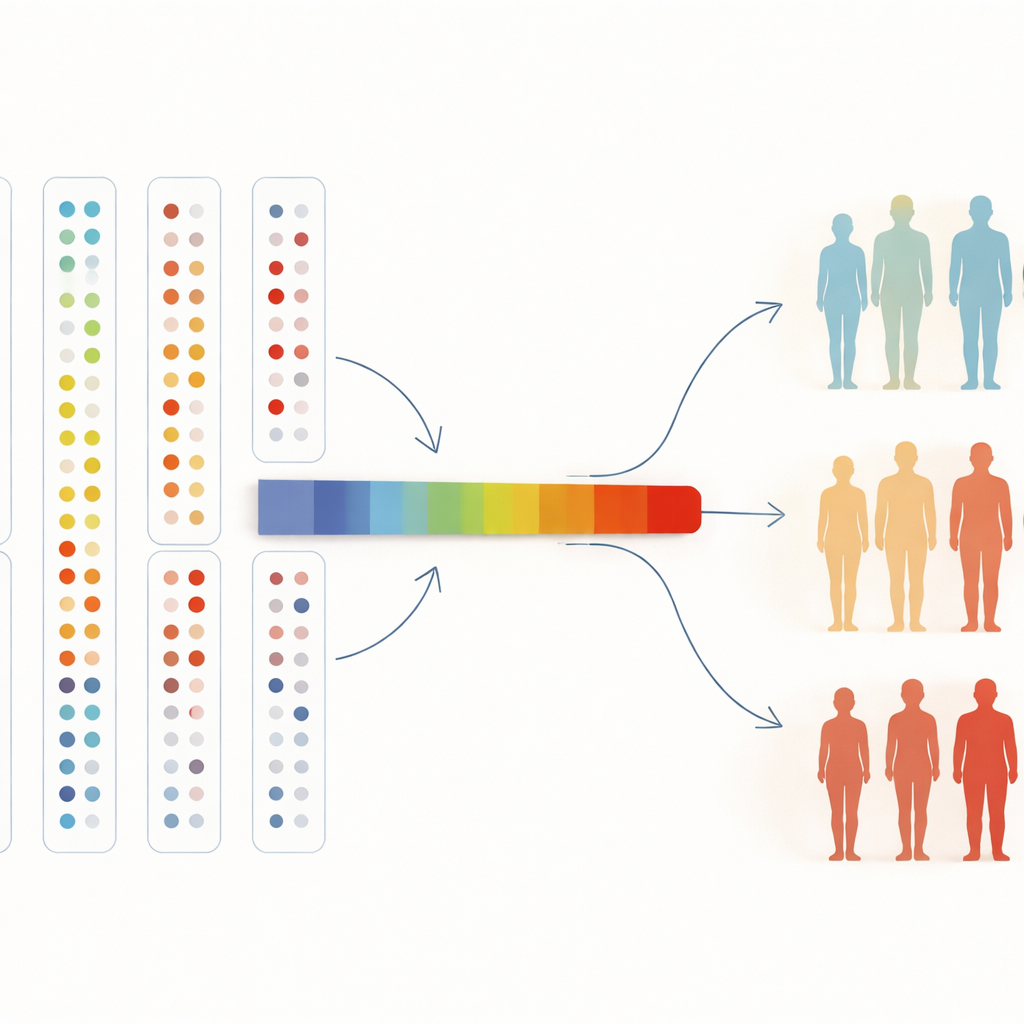
Van bloedkaarten naar toekomstige geneeskunde
Om veel eiwitten tegelijk te begrijpen, comprimeerden de onderzoekers ze ook tot een enkele “as” die de algemene patroonveranderingen samenvatte. Langs deze as stegen de kansen op hypertensie of coeliakie gestaag, en deze trend hield stand toen ze de analyse uitbreidden naar alle deelnemers in de studie. Voor een niet-specialist is de conclusie eenvoudig: door algoritmen mensen vrij te laten sorteren op basis van duizenden bloedeiwitten, kunnen we natuurlijke gezondheidsgerelateerde groepen vinden, bekende ziektekenmerken bevestigen en nieuwe opsporen. Naarmate biobanken groeien naar honderden duizenden mensen en nog meer eiwitten, kan dit soort ongecontroleerde verkenning artsen helpen ziekte eerder te detecteren, begrijpen waarom sommige mensen ziek worden terwijl anderen dat niet doen, en wijzen op nieuwe doelen voor toekomstige behandelingen.
Bronvermelding: Bernard, E., Wang, Y., Chen, M. et al. Unsupervised learning reveals novel disease-associated proteins in high-dimensional human proteomic data. Sci Rep 16, 10185 (2026). https://doi.org/10.1038/s41598-026-41385-7
Trefwoorden: bloedeiwitten, ongecontroleerd leren, biomarkers, precisiegeneeskunde, ziekterisico