Clear Sky Science · zh
基于卷积神经网络与K-means聚类的自动空气监测点选址模型构建
更智能的空气监测为何与城市生活息息相关
城市居民呼吸的空气受交通、工厂和天气等多重因素影响,但大多数城市只能维持少量监测站进行监测。本文提出了一种新的方法,确定这些监测站的最佳位置,使有限数量的传感器仍能勾勒出整个城市的污染全貌。通过将现代的模式识别算法与对相似区域的巧妙聚类相结合,作者旨在在控制成本与计算时间的前提下,高精度地绘制城市范围内的空气质量分布。
从零散观测到完整图景
传统的空气监测网络在站点之间留下很大空白,许多街区的空气质量实际上未知。同时,增加大量站点既昂贵又往往不可行。该研究聚焦于选址问题:在城市被划分为若干小网格且传感器预算有限的条件下,应当监测哪些位置,才能使观测反映出整个城市的污染格局,而不仅仅是靠近已有站点的区域?作者认为,好的选址决策必须考虑污染在时空上的变化,以及天气、交通和土地利用等因素的影响,而不能只依赖少数点位的均值。
让神经网络学习这些模式
为发现这些模式,研究人员使用了卷积神经网络(CNN),这是一类通常用于图像识别的深度学习模型。在此情境中,“图像”是结构化的空气质量记录,包含细颗粒物、粗颗粒物、臭氧、一氧化碳等污染物浓度,以及温度、湿度、风速等因素。CNN学习到紧凑的特征向量——对污染在时空中表现的压缩数值摘要。团队发现使用256个隐藏节点在准确性与速度之间取得了良好平衡,生成的输出稳定且在重构观测数据时预测误差非常小。
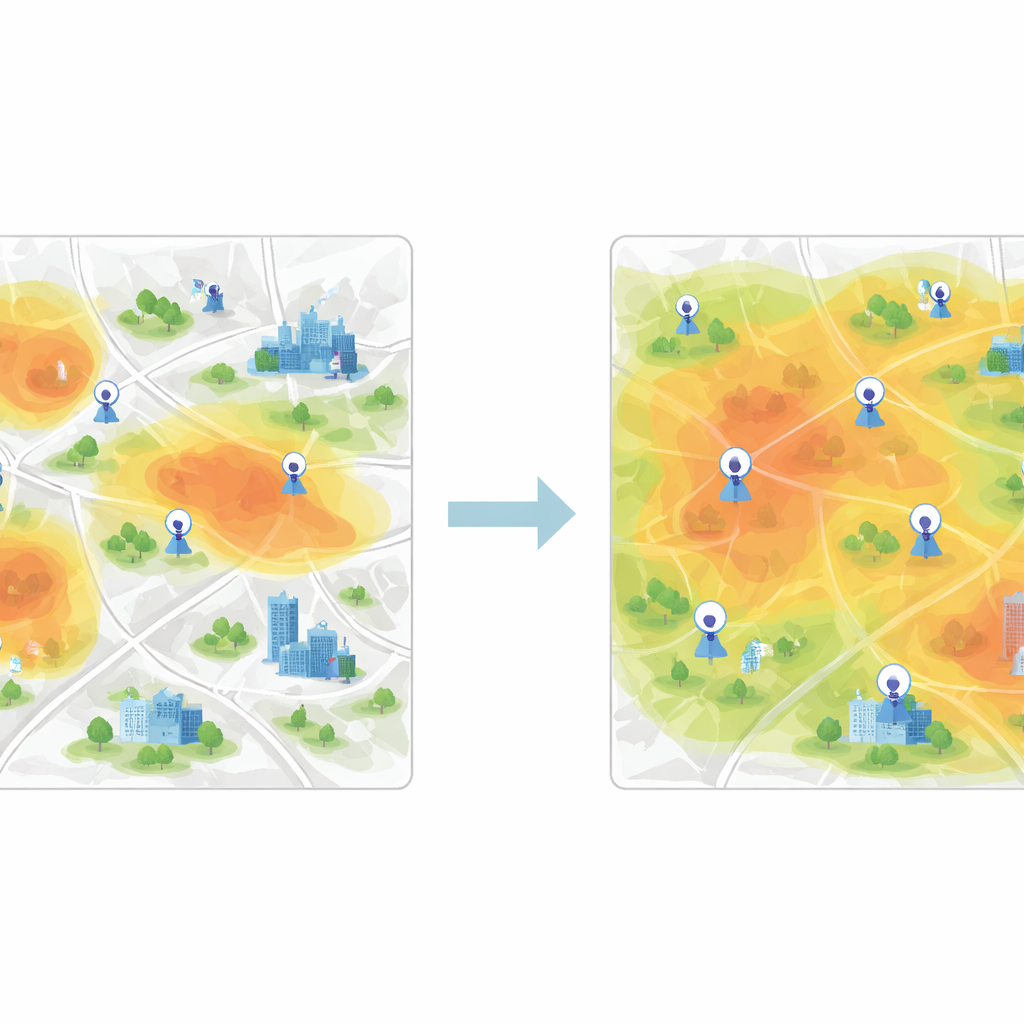
将相似区域分组以公平覆盖城市
在得到这些特征向量后,下一步是对具有相似空气质量行为的网格单元进行分组。为此,研究使用了K-means聚类算法,该算法将数据划分为预设数量的簇。若直接对原始测量值进行聚类,组间边界往往模糊且算法收敛缓慢。然而,在CNN提取特征后,簇结构变得清晰许多,算法能快速找到代表典型污染模式的稳定中心。每个簇代表城市中一个空气行为相似的区域,即便该簇内的街区在地图上看起来差异很大。
用信息增益挑选最佳新增点位
为决定应新增哪些站点,作者引入了一种基于信息熵的贪心过程。他们将城市视为一个节点网络,其中一些节点已有真实传感器数据(已标注),其他为未标注节点。基于已标注与未标注节点之间的特征相似性,计算每个未标注节点在空气质量角色上的不确定性。那些与现有节点差异最大或位于污染格局边界附近的节点具有更高的信息价值。算法迭代地按该度量对节点排序,并将信息量最大的节点“升级”为已标注节点,每次都重新训练模型。最终推荐的监测点是跨多个时间段平均优先级最高的那些位置。
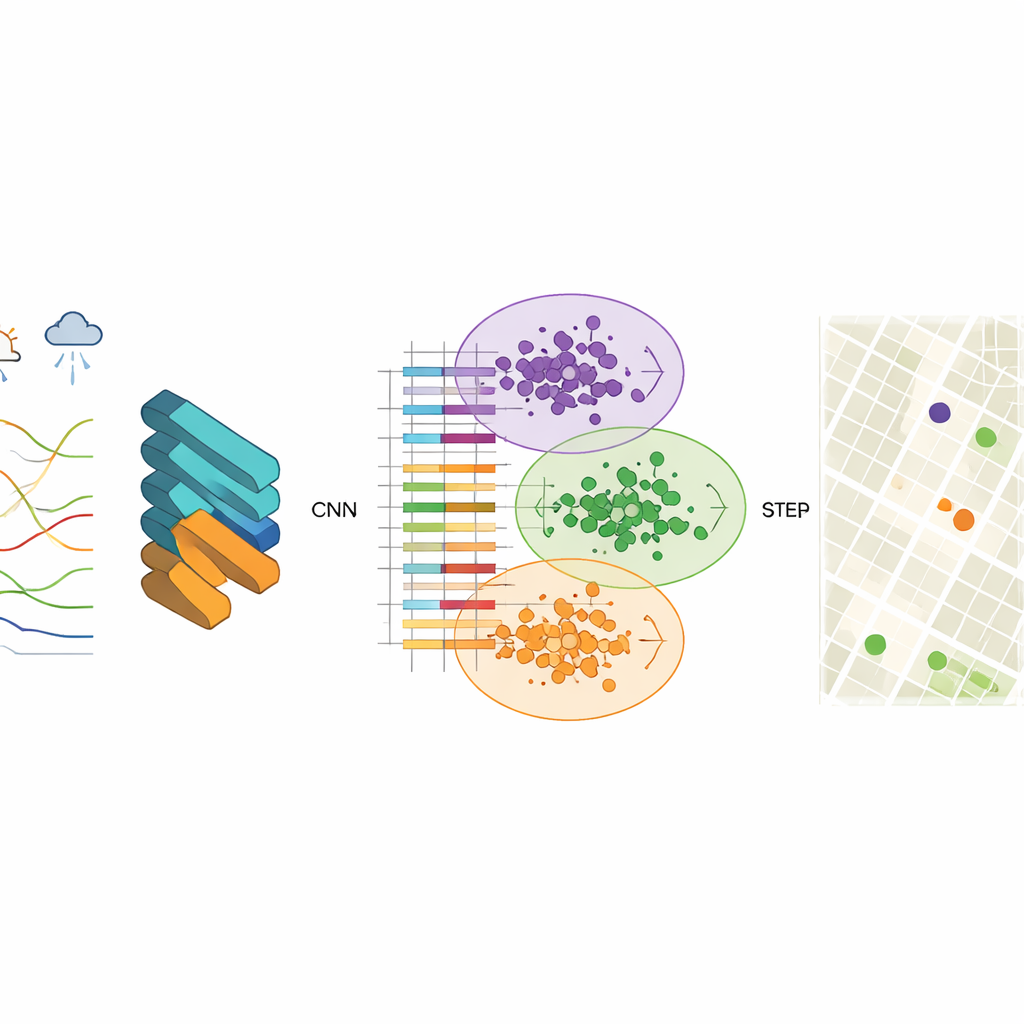
在真实城市中效果如何?
该模型在三个污染水平迥异的中国城市上进行了测试:一个重工业城市、一个混合用途城市和一个较清洁的旅游城市,使用了超过40万条小时级污染物与气象记录。与两种早期选址方法相比,新方法在预测值与观测值之间达到了0.96的相关系数,平均误差低于1%,对一次污染物(如粗颗粒物与二氧化硫)和二次污染物(如臭氧与二氧化氮)均表现出高度一致性。它的数据处理速度大约是对比方法的两倍,平均延迟低于一秒,并能在不同城市类型上高效运行,表明该方法可支持对监测建议的每日更新。
这对呼吸空气的人意味着什么
简单来说,研究表明城市并不需要在每个街区都布置传感器就能掌握空气的清洁或污染状况。通过让神经网络学习污染的流动规律并审慎地挑选信息量最大的地点,管理者可以设计出更精简、更智能的监测网络,以极小的误差追踪城市范围内的情况。对居民而言,这类系统可提供更可靠的空气质量地图、更好的户外活动指引,并为在关键区域制定减排政策提供更坚实的科学依据。
引用: Liu, S., Peng, J. & He, X. Construction of automatic air monitoring point siting model based on convolutional neural network and K-means clustering. Sci Rep 16, 11940 (2026). https://doi.org/10.1038/s41598-026-41078-1
关键词: 城市空气质量, 传感器部署, 深度学习, 环境监测, 污染制图