Clear Sky Science · sv
Konstruktion av automatisk modell för placering av luftövervakningspunkter baserad på konvolutionsneuronätverk och K-means-klustring
Varför smartare luftmätare är viktiga för stadslivet
Stadsbor andas luft formad av trafik, industrier och väder, men de flesta städer har råd med endast ett begränsat antal mätstationer för att hålla uppsikt. Denna artikel presenterar ett nytt sätt att avgöra exakt var dessa stationer bör placeras så att ett begränsat antal sensorer ändå kan ge en tydlig bild av föroreningssituationen över ett helt stadsområde. Genom att kombinera moderna mönsterigenkänningsalgoritmer med smart klustring av likartade platser syftar författarna till att kartlägga luftkvaliteten i staden med hög noggrannhet samtidigt som kostnader och beräkningstid hålls under kontroll.
Från fläckvisa mätningar till en helhetsbild
Traditionella luftövervakningsnät lämnar stora luckor mellan stationerna, så luftkvaliteten i många kvarter blir i praktiken okänd. Samtidigt är det för dyrt och ofta opraktiskt att lägga till många fler stationer. Studien fokuserar på placeringsproblemet: givet en stad indelad i små rutnätsceller och en begränsad budget för sensorer, vilka platser bör övervakas så att mätningarna speglar föroreningsmönstren överallt, inte bara i närheten av befintliga punkter? Författarna menar att bra val måste ta hänsyn till hur föroreningar förändras över både rum och tid och hur de formas av väder, trafik och markanvändning — inte bara av medelvärden vid några få punkter.
Låta ett neuralt nät lära sig mönstren
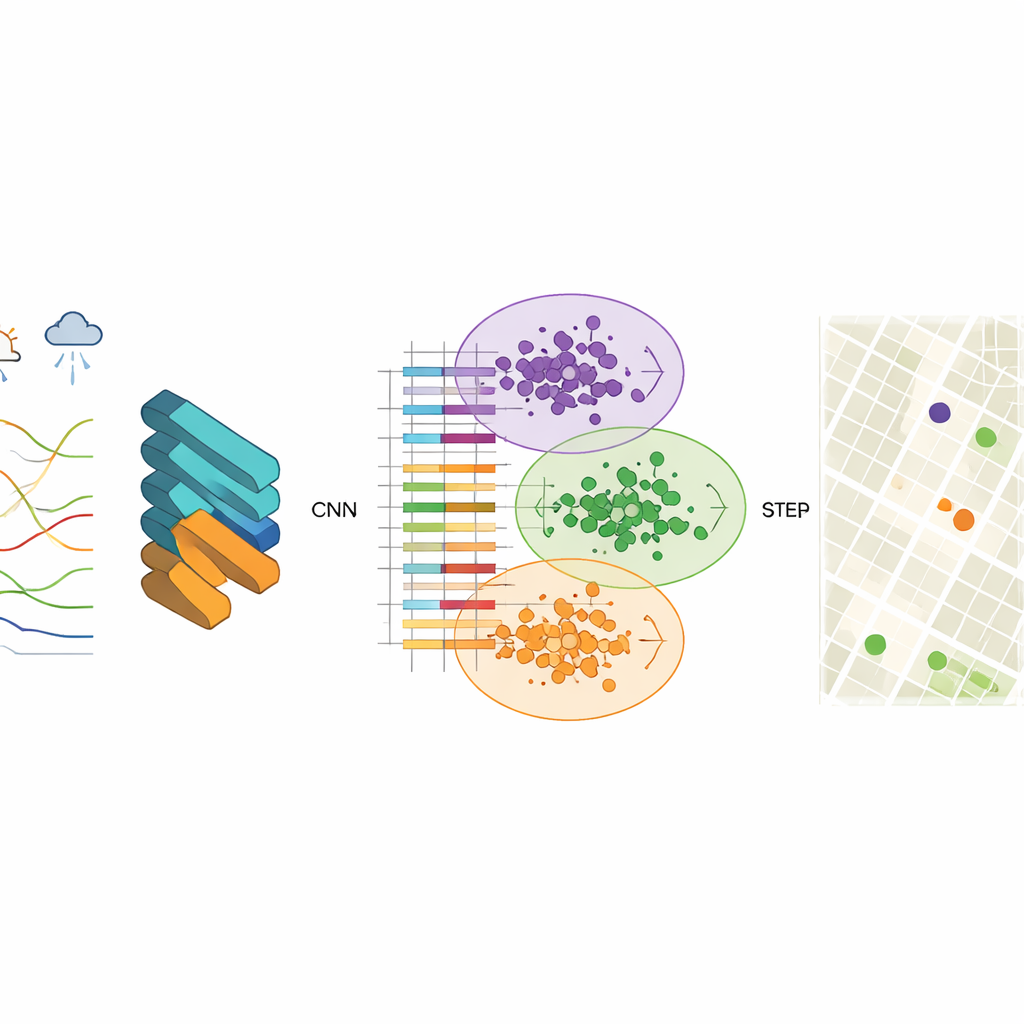
För att upptäcka dessa mönster använder forskarna ett konvolutionsneuronätverk (CNN), en typ av djuplärande modell som vanligtvis används för bildigenkänning. Här är ”bilderna” strukturerade luftkvalitetsregister som inkluderar halter av föroreningar som fina partiklar, grova partiklar, ozon och kolmonoxid, tillsammans med temperatur, luftfuktighet, vind och andra faktorer. CNN lär sig kompakta feature-vektorer — kondenserade numeriska sammanfattningar — som fångar hur föroreningen beter sig över rum och tid. Teamet finner att användning av 256 dolda noder ger en bra balans mellan noggrannhet och hastighet, vilket ger stabila resultat och mycket små prediktionsfel vid rekonstruktion av observerade data.
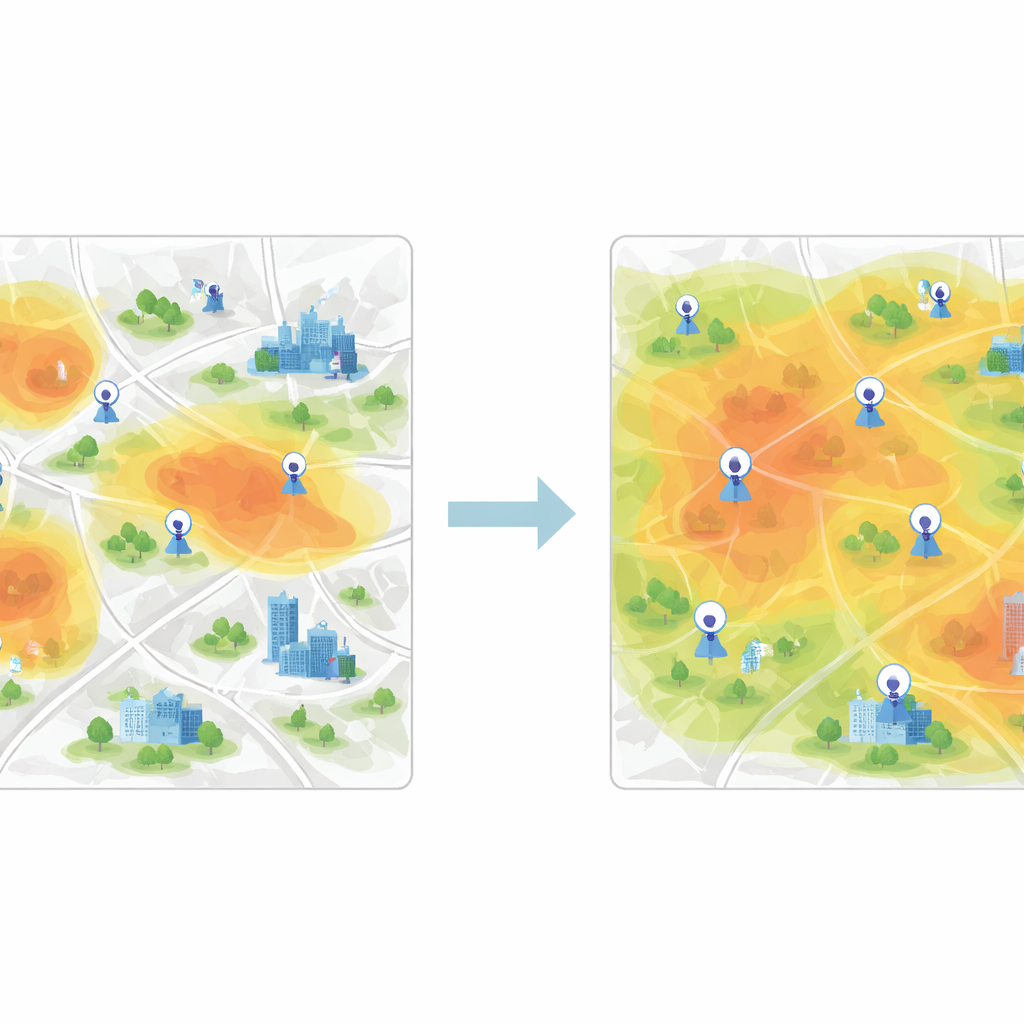
Gruppera liknande områden för att täcka staden rättvist
När dessa feature-vektorer väl är inlärda är nästa steg att gruppera rutnätsceller med likartat luftbeteende. För detta använder studien K-means-klustring, en algoritm som delar upp data i ett förinställt antal kluster. När klustring appliceras direkt på råa mätningar blir gränserna mellan grupperna suddiga och algoritmen konvergerar långsamt. Efter CNN-baserad feature-extraktion blir klustren däremot mycket tydligare, och algoritmen hittar snabbt stabila centra som representerar typiska föroreningsmönster. Varje kluster står för en zon i staden där luften beter sig likartat, även om kvarteren inom zonen ser mycket olika ut på en karta.
Välja de bästa nya platserna med informationsvinster
För att avgöra vilka nya platser som ska läggas till introducerar författarna en girig procedur baserad på informationsentropi. De betraktar staden som ett nätverk av noder, varav några redan är etiketterade med verkliga sensordata och andra är oetiketterade. Genom att använda featuresimilaritet mellan etiketterade och oetiketterade noder beräknar de hur osäker varje oetiketterad nod är vad gäller dess roll i luftkvaliteten. Noder som är minst lika de befintliga — eller som ligger nära gränser mellan föroreningsregimer — har högre informationsvärde. Iterativt rankar algoritmen noderna efter denna måttstock och ”befordrar” de mest informativa in i den etiketterade mängden, och modellen tränas om varje gång. De slutliga rekommenderade stationerna är de med högst genomsnittlig prioritet över flera tidsperioder.
Hur väl fungerar det i verkliga städer?
Modellen testas i tre kinesiska städer med mycket olika föroreningsnivåer: en tungt industrialiserad stad, en stad med blandad användning och en renare turiststad, med mer än 400 000 timvisa register av föroreningar och väder. Jämfört med två tidigare placeringsmetoder uppnår den nya metoden en korrelation på 0,96 mellan predicerade och observerade luftvärden, med medelfel under 1 % och starkt överensstämmande resultat både för primära föroreningar som grova partiklar och svaveldioxid och för sekundära föroreningar som ozon och kvävedioxid. Den bearbetar också data ungefär dubbelt så snabbt som konkurrerande metoder, med subsekunders genomsnittlig latens, och kör effektivt över olika stadstyper, vilket tyder på att den kan stödja dagliga uppdateringar av övervakningsrekommendationer.
Vad detta betyder för dem som andas luften
Enkelt uttryckt visar studien att en stad inte behöver sensorer på varje kvarter för att veta hur ren eller smutsig luften är. Genom att låta ett neuralt nät lära sig hur föroreningar rör sig och sedan noggrant välja de mest informativa platserna kan myndigheter designa slankare, smartare övervakningsnät som följer stadens förhållanden med mycket små fel. För invånarna lovar ett sådant system mer tillförlitliga luftkvalitetskartor, bättre vägledning för utomhusaktiviteter och en starkare vetenskaplig grund för beslut som syftar till att minska föroreningar där det gör mest nytta.
Citering: Liu, S., Peng, J. & He, X. Construction of automatic air monitoring point siting model based on convolutional neural network and K-means clustering. Sci Rep 16, 11940 (2026). https://doi.org/10.1038/s41598-026-41078-1
Nyckelord: urbana luftkvalitet, sensorplacering, djuplärande, miljöövervakning, föroreningskartläggning