Clear Sky Science · nl
Constructie van een automatisch model voor de plaatsing van luchtmeetpunten op basis van convolutionele neurale netwerken en K-means clustering
Waarom slimme luchtmeters belangrijk zijn voor het stadsleven
Stadsbewoners ademen lucht die wordt gevormd door verkeer, fabrieken en het weer, maar de meeste steden kunnen zich slechts een klein aantal meetstations veroorloven om het in de gaten te houden. Dit artikel presenteert een nieuwe manier om precies te bepalen waar die stations moeten komen, zodat een beperkt aantal sensoren toch een helder beeld van de vervuiling over een hele stedelijke omgeving kan geven. Door moderne patroonherkenningsalgoritmen te combineren met slimme clustering van vergelijkbare locaties, streven de auteurs ernaar de luchtkwaliteit in de hele stad met hoge nauwkeurigheid in kaart te brengen, terwijl kosten en rekentijd beheersbaar blijven.
Van onsamenhangende metingen naar een volledig beeld
Traditionele luchtmeetnetwerken laten grote lege ruimtes tussen stations, waardoor de luchtkwaliteit in veel wijken feitelijk onbekend is. Tegelijkertijd is het toevoegen van veel meer stations te duur en vaak onpraktisch. De studie richt zich op het plaatsingsprobleem: gegeven een stad opgedeeld in kleine rastercellen en een beperkt budget voor sensoren, welke locaties moeten worden gemonitord zodat de meetwaarden de vervuilingspatronen overal weerspiegelen, niet alleen in de buurt van bestaande meetpunten? De auteurs betogen dat goede keuzes rekening moeten houden met hoe vervuiling verandert in ruimte en tijd en hoe deze wordt beïnvloed door het weer, verkeer en grondgebruik, en niet alleen door gemiddelden op een paar punten.
Een neuraal netwerk patronen laten leren
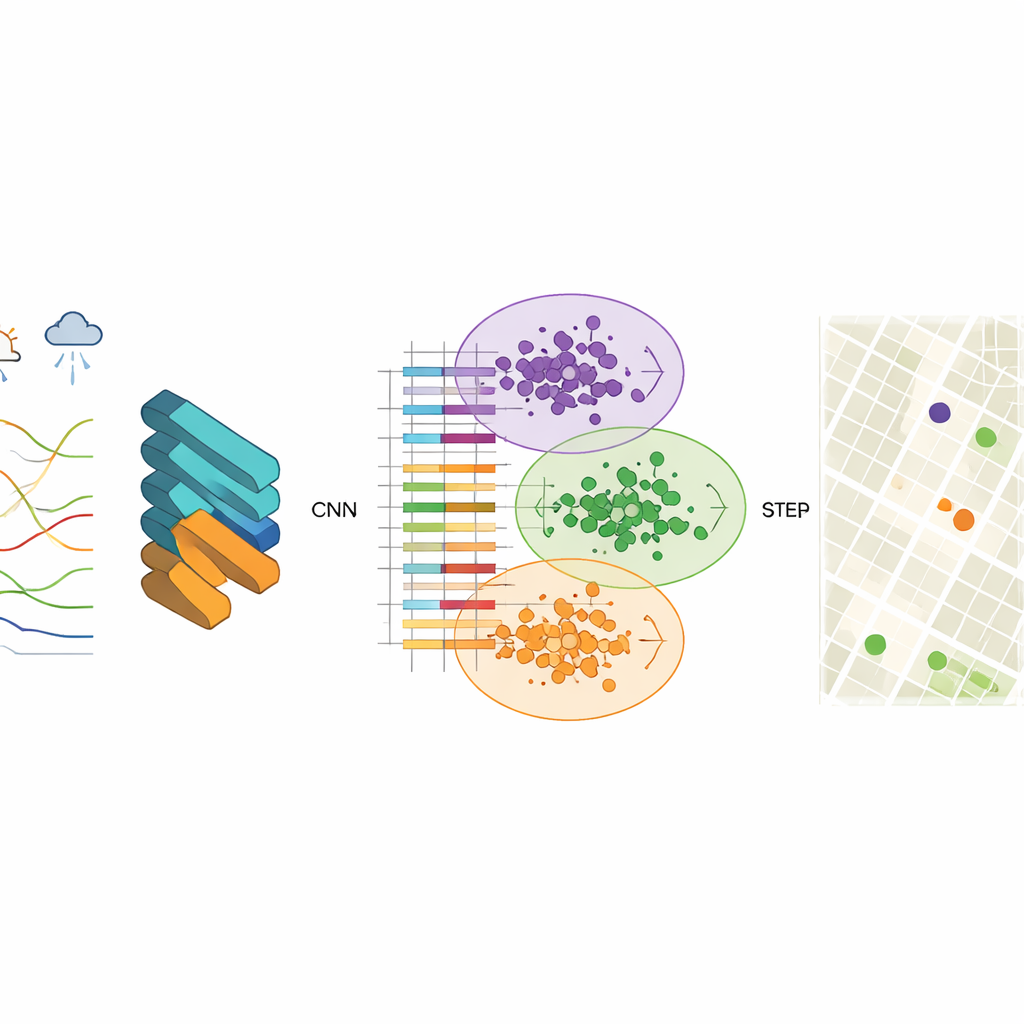
Om die patronen te ontdekken gebruiken de onderzoekers een convolutioneel neuraal netwerk (CNN), een type deep-learningmodel dat normaal gesproken voor beeldherkenning wordt gebruikt. Hier zijn de "afbeeldingen" gestructureerde luchtkwaliteitsregistraties die de concentraties van verontreinigende stoffen zoals fijne deeltjes, grove deeltjes, ozon en koolmonoxide bevatten, samen met temperatuur, luchtvochtigheid, wind en andere factoren. De CNN leert compacte featurevectoren—gecondenseerde numerieke samenvattingen—die vastleggen hoe vervuiling zich ruimtelijk en temporeel gedraagt. Het team constateert dat het gebruik van 256 verborgen neuronen een goede balans biedt tussen nauwkeurigheid en snelheid, met stabiele uitvoer en zeer kleine voorspellingsfouten bij het reconstrueren van de waargenomen data.
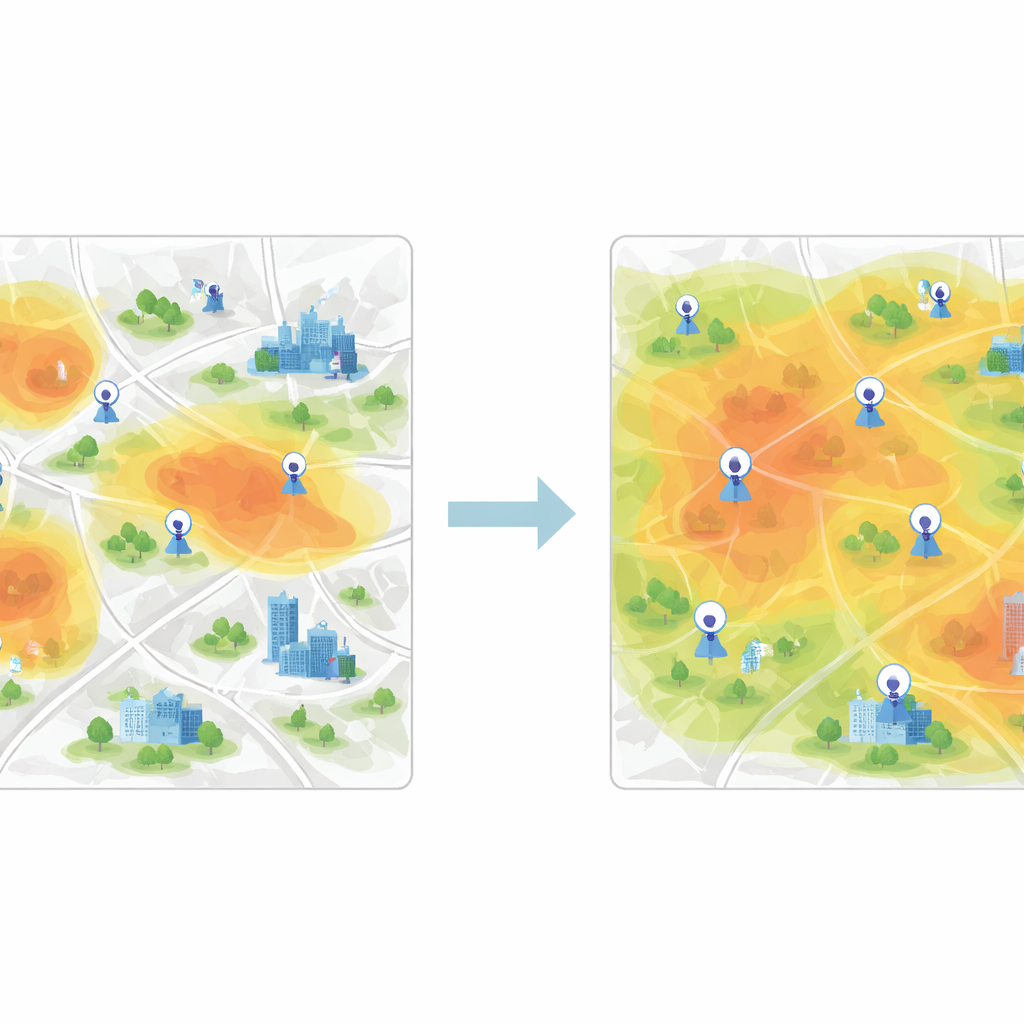
Vergelijkbare gebieden groeperen om de stad eerlijk te dekken
Zodra deze featurevectoren zijn geleerd, is de volgende stap het groeperen van rastercellen met vergelijkbaar luchtkwaliteitsgedrag. Hiervoor gebruikt de studie K-means clustering, een algoritme dat gegevens in een vooraf ingesteld aantal clusters verdeelt. Wanneer clustering rechtstreeks op ruwe metingen wordt toegepast, zijn de scheidslijnen tussen groepen vaag en convergeert het algoritme traag. Na CNN-gebaseerde feature-extractie worden de clusters veel helderder en vindt het algoritme snel stabiele centra die typische vervuilingspatronen vertegenwoordigen. Elke cluster staat voor een zone in de stad waar de lucht vergelijkbaar reageert, ook al zien de buurten binnen die zone er op de kaart erg verschillend uit.
De beste nieuwe locaties kiezen met informatiewinst
Om te beslissen welke nieuwe locaties moeten worden toegevoegd, introduceren de auteurs een greedymethode op basis van informatie-entropie. Ze beschouwen de stad als een netwerk van knooppunten, waarvan sommige al zijn gelabeld met echte sensorgegevens en andere niet. Met behulp van feature-overeenkomsten tussen gelabelde en ongelabelde knooppunten berekenen ze hoe onzeker elk ongelabeld knooppunt is in termen van zijn rol voor de luchtkwaliteit. Knooppunten die het minst op de bestaande lijken—of die zich dicht bij grenzen tussen vervuilingsregimes bevinden—hebben een hogere informatiewaarde. Iteratief rangschikt het algoritme knooppunten op basis van deze maat en "promoveert" het de meest informatieve naar de gelabelde set, waarbij het model telkens opnieuw wordt getraind. De uiteindelijk aanbevolen meetstations zijn die met de hoogste gemiddelde prioriteit over meerdere tijdsperioden.
Hoe goed werkt het in echte steden?
Het model is getest in drie Chinese steden met sterk verschillende vervuilingsniveaus: een sterk geïndustrialiseerde stad, een gemengd gebruikte stad en een schonere toeristenstad, met meer dan 400.000 uurlijkse registraties van verontreinigende stoffen en weersgegevens. Vergeleken met twee eerdere plaatsingsmethoden bereikt de nieuwe methode een correlatie van 0,96 tussen voorspelde en waargenomen luchtkwaliteitswaarden, met gemiddelde fouten onder 1% en sterke overeenstemming voor zowel primaire verontreinigende stoffen zoals grove deeltjes en zwaveldioxide als secundaire stoffen zoals ozon en stikstofdioxide. Het verwerkt data ook ongeveer twee keer sneller dan concurrerende methoden, met subsecondes gemiddelde latentie, en werkt efficiënt voor verschillende stadstypen, wat erop wijst dat het dagelijkse updates van aanbevelingen voor monitoring kan ondersteunen.
Wat dit betekent voor mensen die de lucht inademen
In eenvoudige bewoordingen laat de studie zien dat een stad niet op elke straathoek sensoren nodig heeft om te weten hoe schoon of vervuild de lucht is. Door een neuraal netwerk te laten leren hoe vervuiling zich voortbeweegt en vervolgens zorgvuldig de meest informatieve locaties te selecteren, kunnen beleidsmakers slankere, slimmer ontworpen meetnetwerken ontwerpen die de stadsbrede omstandigheden met zeer kleine fouten volgen. Voor bewoners belooft dit soort systeem betrouwbaardere luchtkwaliteitskaarten, betere aanwijzingen voor buitenactiviteiten en een sterkere wetenschappelijke basis voor beleidsmaatregelen die gericht zijn op het verminderen van vervuiling waar dat het meest nodig is.
Bronvermelding: Liu, S., Peng, J. & He, X. Construction of automatic air monitoring point siting model based on convolutional neural network and K-means clustering. Sci Rep 16, 11940 (2026). https://doi.org/10.1038/s41598-026-41078-1
Trefwoorden: stedelijke luchtkwaliteit, plaatsing van sensoren, diep leren, milieubewaking, vervuilingskaarten