Clear Sky Science · ru
Построение модели размещения автоматических пунктов мониторинга воздуха на основе сверточной нейронной сети и кластеризации K-means
Почему более умные приборы контроля воздуха важны для городской жизни
Горожане дышат воздухом, формируемым движением, фабриками и погодой, но большинство городов может позволить себе лишь небольшое число стационаров для слежения. В этой работе предложен новый способ выбора точного расположения таких станций, чтобы ограниченный набор датчиков всё же давал ясную картину загрязнения по всей городской территории. Сочетая современные алгоритмы распознавания шаблонов с разумной группировкой похожих участков, авторы стремятся с высокой точностью картировать качество воздуха в городе, сохраняя при этом контроль над затратами и временем вычислений.
От фрагментарных замеров к полной картине
Традиционные сети мониторинга оставляют большие пробелы между станциями, поэтому качество воздуха во многих районах фактически неизвестно. Вместе с тем добавлять множество новых точек слишком дорого и часто непрактично. Исследование сосредоточено на проблеме размещения: если город разделён на мелкие ячейки сетки и бюджет на датчики ограничен, какие места следует контролировать, чтобы показания отражали схемы загрязнения повсюду, а не только вблизи существующих станций? Авторы утверждают, что хорошие решения должны учитывать, как загрязнение меняется во времени и пространстве и как на него влияют погода, трафик и использование земли, а не полагаться лишь на средние значения в нескольких точках.
Пусть нейронная сеть изучит закономерности
Чтобы выявить эти закономерности, исследователи используют сверточную нейронную сеть (CNN), тип модели глубокого обучения, обычно применяемый для распознавания изображений. Здесь «изображениями» служат структурированные записи качества воздуха, включающие уровни загрязнителей — тонких и крупных частиц, озона и оксида углерода — а также температуру, влажность, ветер и другие факторы. CNN обучается компактным векторным представлениям — сжатым числовым резюме — которые фиксируют, как загрязнение ведёт себя в пространстве и времени. Команда выяснила, что использование 256 скрытых узлов обеспечивает хороший баланс между точностью и скоростью, выдавая стабильные результаты и очень небольшие ошибки при восстановлении наблюдаемых данных.
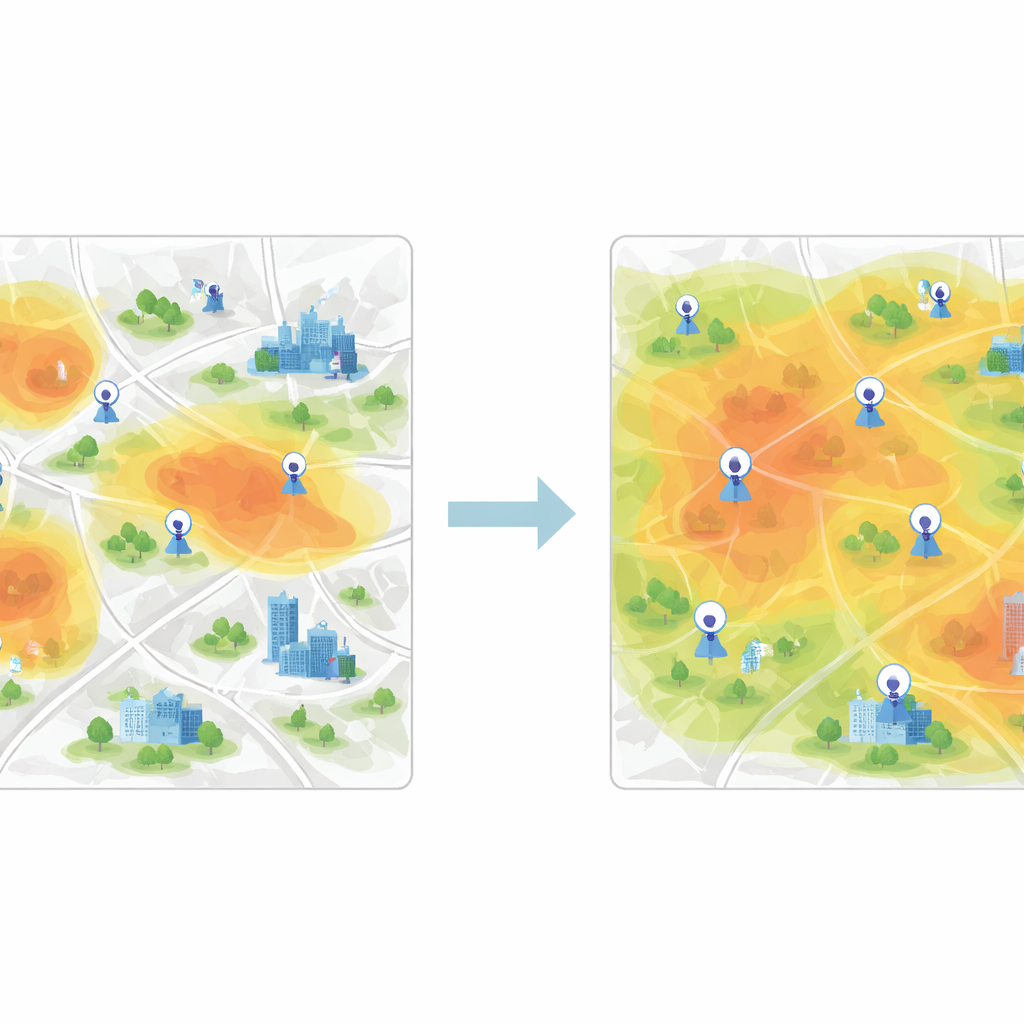
Группировка похожих районов для равномерного покрытия города
После обучения этих векторных признаков следующий шаг — сгруппировать ячейки сетки с похожим поведением качества воздуха. Для этого в исследовании используется кластеризация K-means — алгоритм, разделяющий данные на заранее заданное число кластеров. Когда кластеризация применяется напрямую к необработанным измерениям, границы между группами размыты, и алгоритм сходится медленно. После извлечения признаков на основе CNN кластеры становятся значительно чище, и алгоритм быстро находит стабильные центры, представляющие типичные схемы загрязнения. Каждый кластер обозначает зону в городе, где воздух ведёт себя схожим образом, даже если районы внутри неё на карте выглядят очень по-разному.
Выбор лучших новых точек на основе прироста информации
Чтобы решить, какие новые точки добавить, авторы вводят жадную процедуру на основе информационной энтропии. Они рассматривают город как сеть узлов: некоторые уже помечены реальными данными с датчиков, другие — нет. Используя похожесть признаков между помеченными и немаркированными узлами, они вычисляют, насколько неопределён каждый немаркированный узел в его роли качества воздуха. Узлы, наименее похожие на существующие — или находящиеся возле границ между режимами загрязнения — имеют большую информационную ценность. Итеративно алгоритм ранжирует узлы по этой мере и «продвигает» наиболее информативные в помеченный набор, переобучая модель каждый раз. В финале рекомендуемые станции — это те, у которых наивысший средний приоритет за несколько периодов времени.
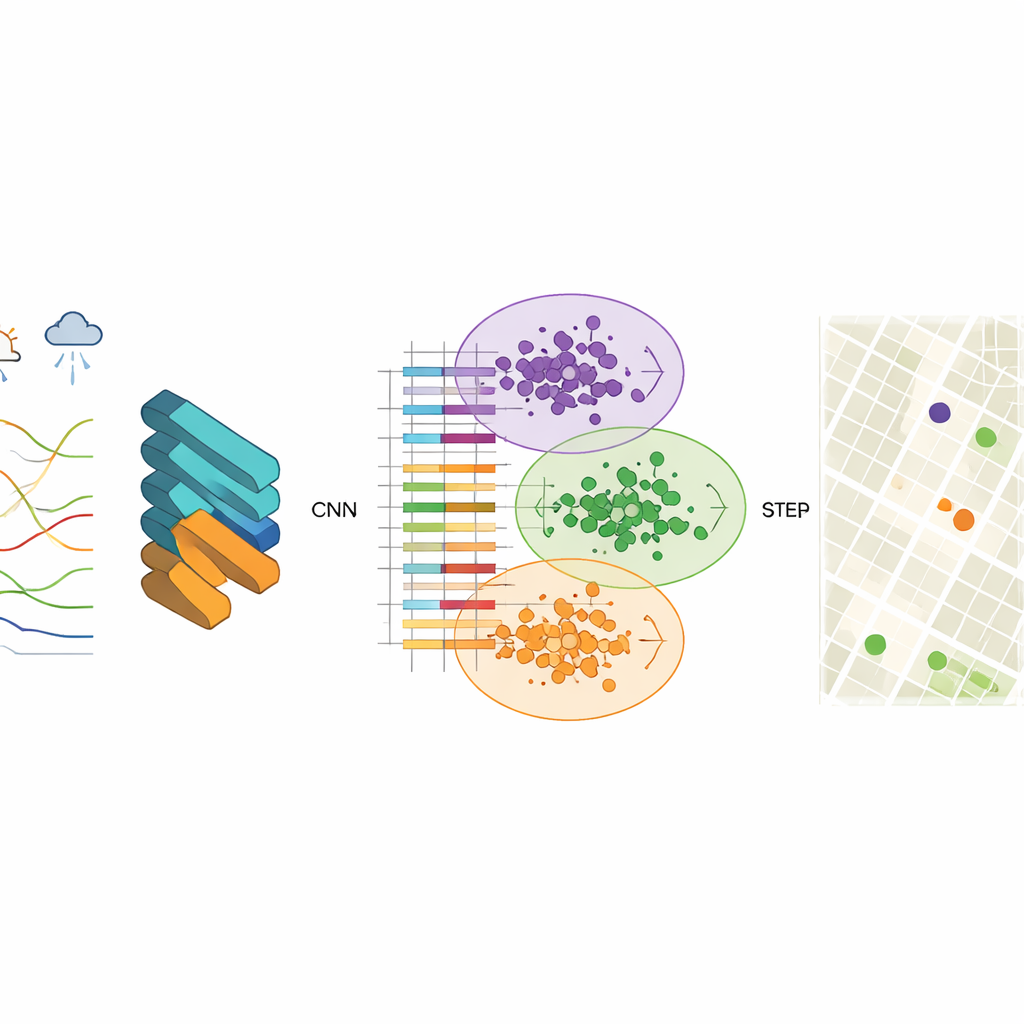
Насколько хорошо это работает в реальных городах?
Модель протестирована на трёх китайских городах с очень разным уровнем загрязнения: в одном — сильная индустриализация, в другом — смешанное использование территорий, в третьем — более чистый туристический город; использовано более 400 000 почасовых записей о загрязнителях и погоде. По сравнению с двумя ранее предложенными подходами к размещению новая методика достигает корреляции 0,96 между предсказанными и наблюдаемыми значениями качества воздуха, со средними ошибками ниже 1% и высокой согласованностью как для первичных загрязнителей (крупных частиц, двуокиси серы), так и для вторичных (озон, диоксид азота). Она также обрабатывает данные примерно вдвое быстрее конкурентов, с средней задержкой менее секунды, и эффективно работает в разных типах городов, что свидетельствует о возможности ежедневного обновления рекомендаций по мониторингу.
Что это значит для людей, дышащих этим воздухом
Проще говоря, исследование показывает: городу не нужны датчики на каждом квартале, чтобы знать, чистый ли его воздух. Позволив нейронной сети изучить, как распространяется загрязнение, и затем тщательно выбрав наиболее информативные места, власти могут спроектировать более стройные и умные сети мониторинга, которые отслеживают параметры по всему городу с очень малыми ошибками. Для жителей такая система обещает более надёжные карты качества воздуха, лучшее руководство по пребыванию на открытом воздухе и более прочную научную базу для политики, направленной на сокращение загрязнения там, где это действительно важно.
Цитирование: Liu, S., Peng, J. & He, X. Construction of automatic air monitoring point siting model based on convolutional neural network and K-means clustering. Sci Rep 16, 11940 (2026). https://doi.org/10.1038/s41598-026-41078-1
Ключевые слова: городское качество воздуха, размещение датчиков, глубокое обучение, экологический мониторинг, картирование загрязнения