Clear Sky Science · it
Costruzione di un modello automatico per il posizionamento di punti di monitoraggio dell’aria basato su rete neurale convoluzionale e clustering K-means
Perché monitor dell’aria più intelligenti contano per la vita in città
Gli abitanti delle città respirano un’aria modellata da traffico, industrie e condizioni meteorologiche, ma la maggior parte delle città può permettersi solo un numero limitato di stazioni di monitoraggio. Questo articolo presenta un nuovo metodo per decidere esattamente dove collocare queste stazioni in modo che un insieme ristretto di sensori possa comunque offrire un quadro chiaro dell’inquinamento sull’intero territorio urbano. Combinando algoritmi moderni di riconoscimento dei pattern con un clustering intelligente di aree simili, gli autori mirano a mappare la qualità dell’aria a livello cittadino con alta accuratezza mantenendo sotto controllo costi e tempi di calcolo.
Da letture disomogenee a un quadro completo
Le reti tradizionali di monitoraggio dell’aria lasciano ampi vuoti tra le stazioni, perciò la qualità dell’aria in molti quartieri rimane di fatto sconosciuta. Allo stesso tempo, aggiungere molte più stazioni è troppo costoso e spesso impraticabile. Lo studio si concentra sul problema della collocazione: data una città divisa in piccole celle di griglia e un budget limitato per i sensori, quali posizioni dovrebbero essere monitorate perché le letture riflettano i modelli di inquinamento ovunque, non solo vicino ai siti esistenti? Gli autori sostengono che buone scelte devono tener conto di come l’inquinamento cambia nello spazio e nel tempo e di come è influenzato da meteo, traffico e uso del suolo, non soltanto dalle medie in pochi punti.
Lasciare che una rete neurale apprenda i pattern
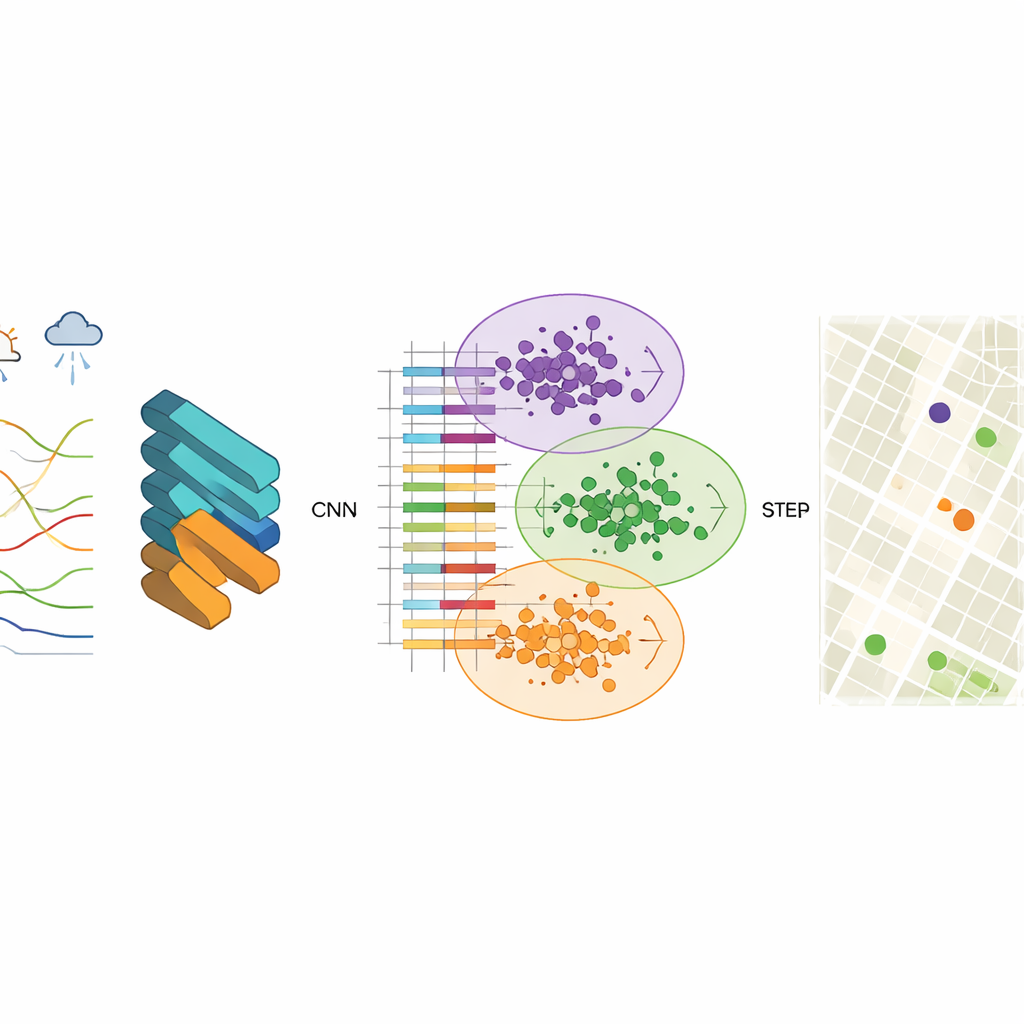
Per scoprire questi pattern, i ricercatori utilizzano una rete neurale convoluzionale (CNN), un tipo di modello di deep learning normalmente impiegato per il riconoscimento delle immagini. Qui le “immagini” sono registrazioni strutturate della qualità dell’aria che includono livelli di inquinanti come particolato fine, particolato grosso, ozono e monossido di carbonio, insieme a temperatura, umidità, vento e altri fattori. La CNN apprende vettori di caratteristiche compatti—sintesi numeriche condensate—che catturano come l’inquinamento si comporta nello spazio e nel tempo. Il gruppo trova che usare 256 nodi nascosti offre un buon equilibrio tra accuratezza e velocità, producendo output stabili e errori di previsione molto piccoli nella ricostruzione dei dati osservati.
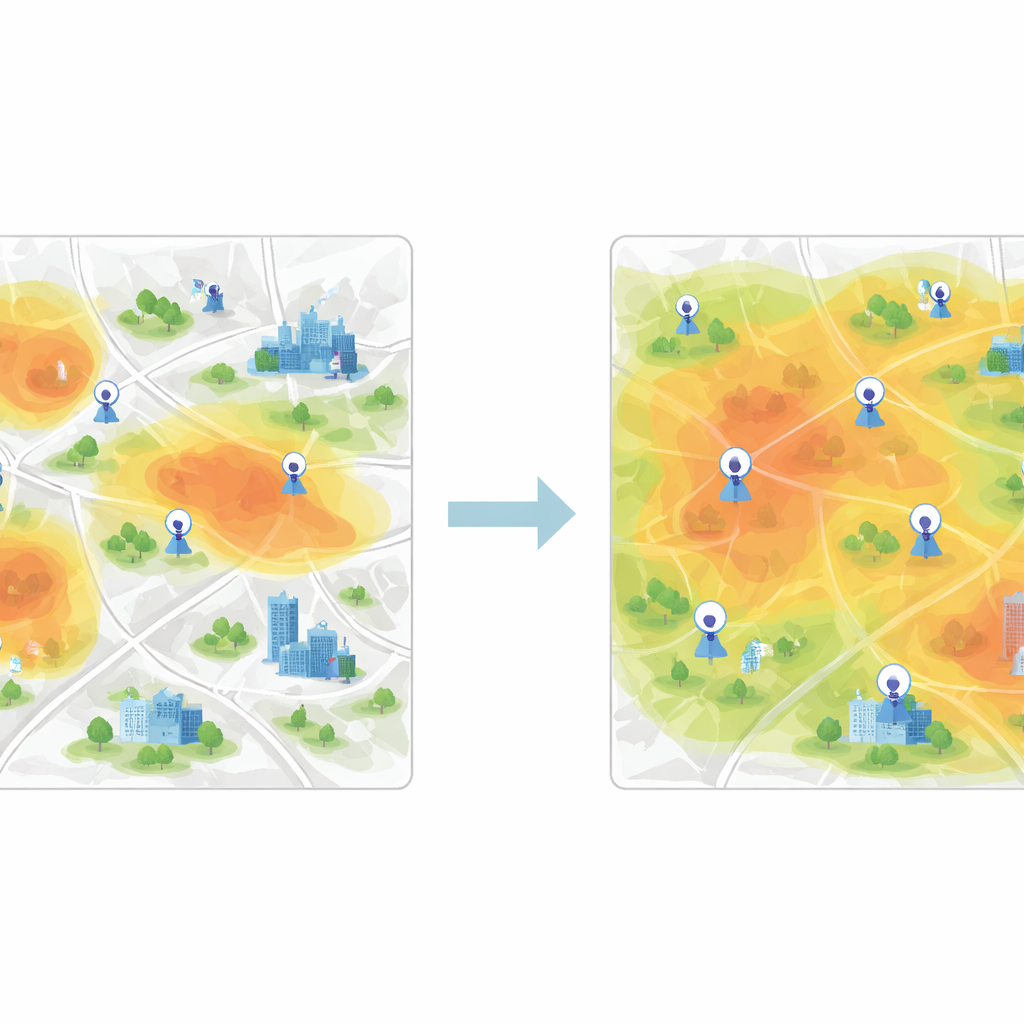
Raggruppare aree simili per coprire la città equamente
Una volta appresi questi vettori di caratteristiche, il passo successivo è raggruppare le celle di griglia con comportamenti simili nella qualità dell’aria. Per questo lo studio utilizza il clustering K-means, un algoritmo che separa i dati in un numero prestabilito di cluster. Quando il clustering viene applicato direttamente alle misurazioni grezze, i confini tra i gruppi sono sfumati e l’algoritmo converge lentamente. Dopo l’estrazione delle caratteristiche basata sulla CNN, però, i cluster diventano molto più netti e l’algoritmo trova rapidamente centri stabili che rappresentano schemi tipici di inquinamento. Ogni cluster rappresenta una zona della città in cui l’aria si comporta in modo simile, anche se i quartieri al suo interno possono apparire molto diversi su una mappa.
Scegliere i posti migliori con il guadagno informativo
Per decidere quali nuovi siti aggiungere, gli autori introducono una procedura greedy basata sull’entropia informativa. Considerano la città come una rete di nodi, alcuni già etichettati con dati reali dei sensori e altri non etichettati. Usando la similarità delle caratteristiche tra nodi etichettati e non etichettati, calcolano quanto è incerto ciascun nodo non etichettato rispetto al suo ruolo nella qualità dell’aria. I nodi meno simili a quelli esistenti—o che si trovano vicino ai confini tra regimi di inquinamento—hanno un valore informativo maggiore. Iterativamente, l’algoritmo classifica i nodi in base a questa misura e “promuove” i più informativi nell’insieme etichettato, riaddestrando il modello a ogni passo. Le stazioni finali raccomandate sono quelle con la priorità media più alta attraverso più periodi temporali.
Quanto funziona nelle città reali?
Il modello è testato su tre città cinesi con livelli di inquinamento molto diversi: una città fortemente industriale, una a uso misto e una città turistica più pulita, utilizzando oltre 400.000 record orari di inquinanti e condizioni meteorologiche. Rispetto a due approcci precedenti per il posizionamento, il nuovo metodo raggiunge una correlazione di 0,96 tra valori di qualità dell’aria predetti e osservati, con errori medi inferiori all’1% e forte concordanza sia per inquinanti primari come particolato grosso e anidride solforosa sia per inquinanti secondari come ozono e biossido di azoto. Inoltre processa i dati all’incirca il doppio della velocità dei metodi concorrenti, con latenze medie inferiori al secondo, e funziona in modo efficiente attraverso tipi di città diversi, indicando che può supportare aggiornamenti quotidiani delle raccomandazioni di monitoraggio.
Cosa significa per chi respira l’aria
In termini semplici, lo studio dimostra che una città non ha bisogno di sensori in ogni isolato per sapere quanto è pulita o inquinata l’aria. Permettendo a una rete neurale di apprendere come si muove l’inquinamento e selezionando poi con cura le posizioni più informative, le autorità possono progettare reti di monitoraggio più snelle e intelligenti che tracciano le condizioni cittadine con errori molto piccoli. Per i residenti, questo tipo di sistema promette mappe della qualità dell’aria più affidabili, indicazioni migliori per le attività all’aperto e una base scientifica più solida per politiche mirate a ridurre l’inquinamento dove conta di più.
Citazione: Liu, S., Peng, J. & He, X. Construction of automatic air monitoring point siting model based on convolutional neural network and K-means clustering. Sci Rep 16, 11940 (2026). https://doi.org/10.1038/s41598-026-41078-1
Parole chiave: qualità dell'aria urbana, posizionamento dei sensori, deep learning, monitoraggio ambientale, mappatura dell'inquinamento