Clear Sky Science · es
Construcción de un modelo automático de emplazamiento de puntos de vigilancia del aire basado en red neuronal convolucional y agrupamiento K-means
Por qué importan monitores de aire más inteligentes para la vida urbana
Los habitantes de las ciudades respiran un aire moldeado por el tráfico, las fábricas y el tiempo atmosférico, pero la mayoría de las ciudades solo puede permitirse un número reducido de estaciones de vigilancia. Este artículo presenta una nueva forma de decidir exactamente dónde deben ubicarse esas estaciones para que un conjunto limitado de sensores pueda ofrecer una imagen clara de la contaminación en toda el área urbana. Al combinar algoritmos modernos de reconocimiento de patrones con un agrupamiento inteligente de lugares similares, los autores buscan cartografiar la calidad del aire a escala urbana con alta precisión, manteniendo al mismo tiempo los costes y el tiempo de cálculo bajo control.
De lecturas parciales a una visión completa
Las redes tradicionales de vigilancia del aire dejan grandes huecos entre estaciones, por lo que la calidad del aire en muchos barrios queda en la práctica desconocida. A la vez, añadir muchas más estaciones resulta demasiado caro y a menudo poco práctico. El estudio se centra en el problema del emplazamiento: dado que una ciudad se divide en pequeñas celdas de una cuadrícula y existe un presupuesto limitado para sensores, ¿qué ubicaciones deben monitorizarse para que las lecturas reflejen los patrones de contaminación en todas partes, y no solo cerca de los puntos ya existentes? Los autores sostienen que las buenas decisiones deben tener en cuenta cómo cambia la contaminación en el espacio y en el tiempo y cómo la modelan el tiempo atmosférico, el tráfico y el uso del suelo, no solo los promedios en unos pocos puntos.
Dejar que una red neuronal aprenda los patrones
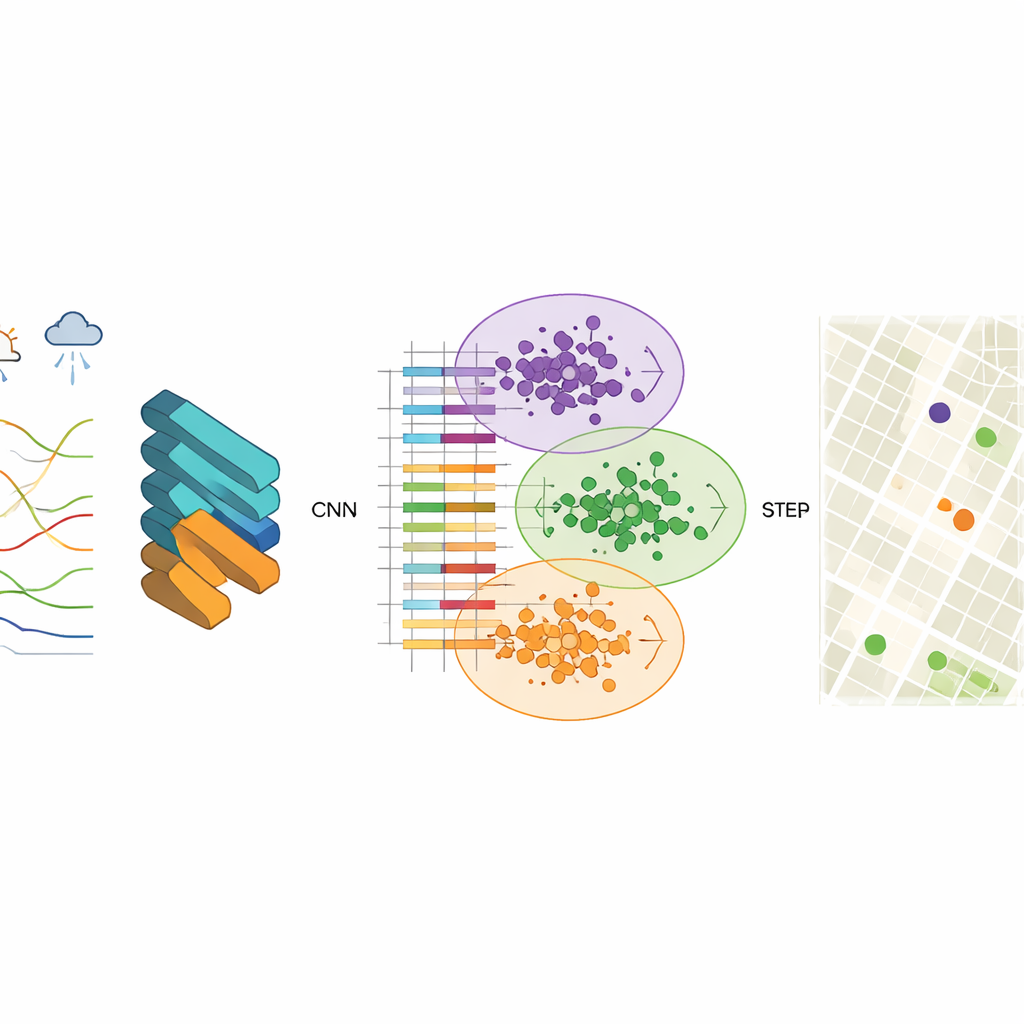
Para descubrir esos patrones, los investigadores emplean una red neuronal convolucional (CNN), un tipo de modelo de aprendizaje profundo normalmente usado en reconocimiento de imágenes. Aquí, las “imágenes” son registros estructurados de calidad del aire que incluyen niveles de contaminantes como partículas finas, partículas gruesas, ozono y monóxido de carbono, junto con temperatura, humedad, viento y otros factores. La CNN aprende vectores de características compactos—resúmenes numéricos condensados—que capturan cómo se comporta la contaminación en el espacio y el tiempo. El equipo encuentra que usar 256 nodos ocultos ofrece un buen equilibrio entre precisión y velocidad, produciendo salidas estables y errores de predicción muy pequeños al reconstruir los datos observados.
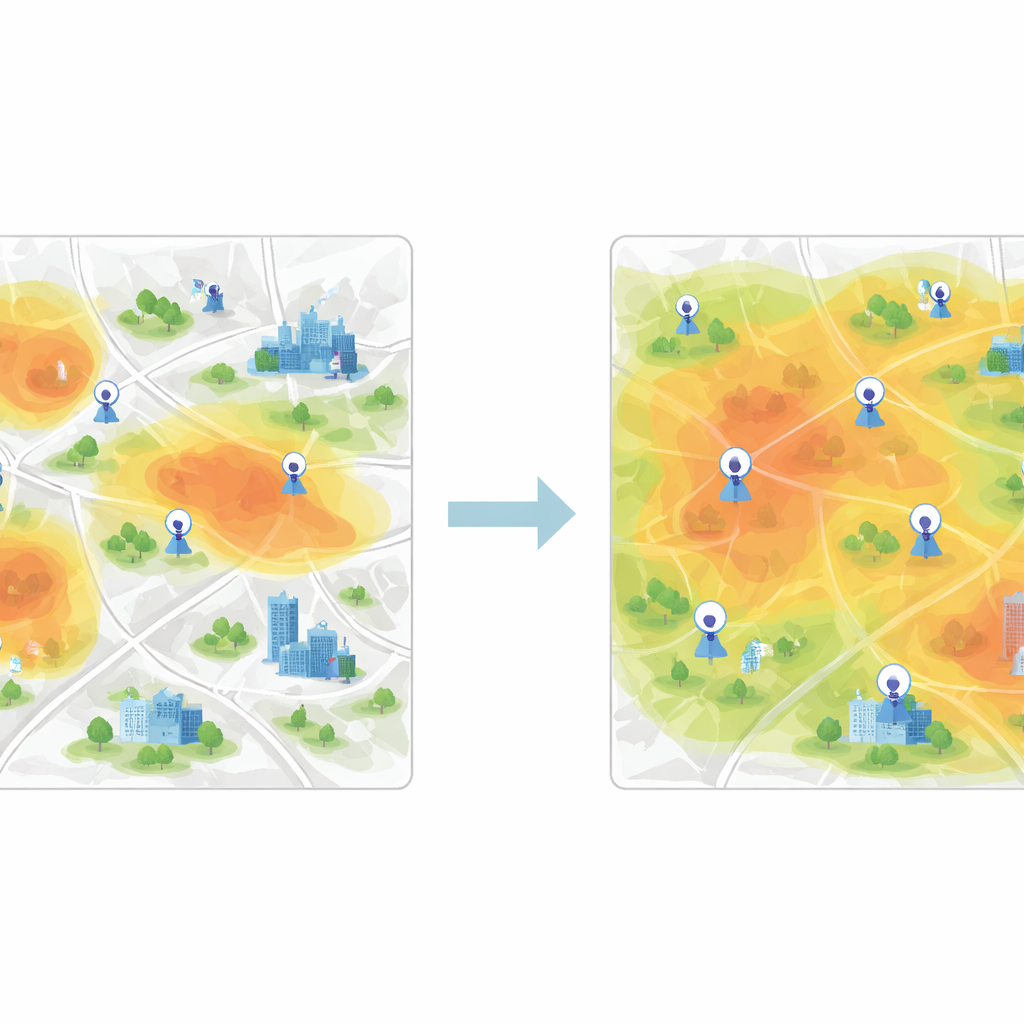
Agrupar áreas similares para cubrir la ciudad de forma equitativa
Una vez aprendidos estos vectores de características, el siguiente paso es agrupar las celdas de la cuadrícula con comportamientos similares de calidad del aire. Para ello, el estudio utiliza K-means, un algoritmo que separa los datos en un número prefijado de clústeres. Cuando el agrupamiento se aplica directamente a las mediciones crudas, los límites entre grupos son difusos y el algoritmo converge lentamente. Sin embargo, tras la extracción de características basada en CNN, los clústeres se vuelven mucho más claros y el algoritmo encuentra rápidamente centros estables que representan patrones típicos de contaminación. Cada clúster representa una zona de la ciudad donde el aire se comporta de manera similar, incluso si los barrios que lo componen son muy distintos en el mapa.
Elegir los mejores nuevos puntos con ganancia de información
Para decidir qué nuevos sitios añadir, los autores introducen un procedimiento voraz basado en la entropía de la información. Consideran la ciudad como una red de nodos, algunos ya etiquetados con datos reales de sensores y otros sin etiquetar. Usando la similitud de características entre nodos etiquetados y no etiquetados, calculan cuán incierto es cada nodo no etiquetado en términos de su papel en la calidad del aire. Los nodos que menos se parecen a los ya existentes—o que se sitúan cerca de límites entre regímenes de contaminación—tienen mayor valor informativo. Iterativamente, el algoritmo ordena los nodos según esta medida y “promueve” los más informativos al conjunto etiquetado, reentrenando el modelo en cada paso. Las estaciones recomendadas al final son aquellas con mayor prioridad promedio a lo largo de varios periodos temporales.
¿Qué tan bien funciona en ciudades reales?
El modelo se prueba en tres ciudades chinas con niveles de contaminación muy distintos: una ciudad fuertemente industrial, una de uso mixto y una ciudad turística más limpia, usando más de 400.000 registros horarios de contaminantes y condiciones meteorológicas. En comparación con dos enfoques de emplazamiento anteriores, el nuevo método logra una correlación de 0,96 entre los valores de calidad del aire predichos y observados, con errores medios por debajo del 1% y un fuerte acuerdo tanto para contaminantes primarios como las partículas gruesas y el dióxido de azufre como para contaminantes secundarios como el ozono y el dióxido de nitrógeno. Además, procesa los datos aproximadamente el doble de rápido que los métodos competidores, con una latencia media por debajo de un segundo, y funciona de manera eficiente en distintos tipos de ciudades, lo que indica que puede soportar actualizaciones diarias de las recomendaciones de monitorización.
Qué significa esto para las personas que respiran el aire
En términos sencillos, el estudio muestra que una ciudad no necesita sensores en cada manzana para saber si su aire es limpio o contaminado. Dejando que una red neuronal aprenda cómo se desplaza la contaminación y seleccionando luego con cuidado las ubicaciones más informativas, las autoridades pueden diseñar redes de vigilancia más austeras e inteligentes que rastreen las condiciones de toda la ciudad con errores muy pequeños. Para los residentes, este tipo de sistema promete mapas de calidad del aire más fiables, mejores orientaciones para actividades al aire libre y una base científica más sólida para políticas destinadas a reducir la contaminación donde más importa.
Cita: Liu, S., Peng, J. & He, X. Construction of automatic air monitoring point siting model based on convolutional neural network and K-means clustering. Sci Rep 16, 11940 (2026). https://doi.org/10.1038/s41598-026-41078-1
Palabras clave: calidad del aire urbano, ubicación de sensores, aprendizaje profundo, monitorización ambiental, cartografía de la contaminación