Clear Sky Science · de
Konstruktion eines automatischen Standortmodells für Luftüberwachungsstellen basierend auf Convolutional Neural Network und K-Means-Clustering
Warum intelligentere Luftmessungen für das Stadtleben wichtig sind
Stadtbewohner atmen Luft, die von Verkehr, Fabriken und Wetter geprägt wird, doch die meisten Städte können sich nur eine geringe Anzahl von Messstationen leisten. Dieser Beitrag stellt eine neue Methode vor, um genau festzulegen, wohin diese Stationen gestellt werden sollten, damit eine begrenzte Anzahl von Sensoren trotzdem ein klares Bild der Verschmutzung über das gesamte Stadtgebiet liefert. Durch die Kombination moderner Mustererkennungsalgorithmen mit geschicktem Clustering ähnlicher Orte wollen die Autoren die stadtweite Luftqualität mit hoher Genauigkeit abbilden und gleichzeitig Kosten und Rechenzeit im Rahmen halten.
Von lückenhaften Messwerten zu einem vollständigen Bild
Traditionelle Luftüberwachungsnetze lassen große Lücken zwischen den Stationen, sodass die Luftqualität in vielen Vierteln de facto unbekannt ist. Gleichzeitig ist das Hinzufügen vieler weiterer Stationen zu teuer und oft unpraktisch. Die Studie konzentriert sich auf das Standortproblem: Gegeben ist eine Stadt, die in kleine Gitterzellen unterteilt ist, und ein begrenztes Budget für Sensoren — welche Standorte sollten überwacht werden, damit die Messwerte die Verschmutzungsmuster überall widerspiegeln und nicht nur in der Nähe bereits vorhandener Messstellen? Die Autoren argumentieren, dass gute Entscheidungen berücksichtigen müssen, wie sich Verschmutzung räumlich und zeitlich verändert und wie sie durch Wetter, Verkehr und Flächennutzung geformt wird, und nicht nur durch Mittelwerte an wenigen Punkten.
Ein neuronales Netzwerk lernt die Muster
Um diese Muster aufzudecken, setzen die Forschenden ein Convolutional Neural Network (CNN) ein, ein Deep-Learning-Modell, das normalerweise in der Bilderkennung verwendet wird. Hier sind die „Bilder“ strukturierte Luftqualitätsaufzeichnungen, die Schadstoffwerte wie Feinstaub, Grobpartikel, Ozon und Kohlenmonoxid sowie Temperatur, Luftfeuchte, Wind und weitere Faktoren enthalten. Das CNN lernt kompakte Merkmalsvektoren — kondensierte numerische Zusammenfassungen —, die erfassen, wie sich Verschmutzung räumlich und zeitlich verhält. Das Team stellt fest, dass 256 versteckte Knoten ein gutes Gleichgewicht zwischen Genauigkeit und Geschwindigkeit bieten und stabile Ausgaben sowie sehr geringe Vorhersagefehler bei der Rekonstruktion der beobachteten Daten liefern.
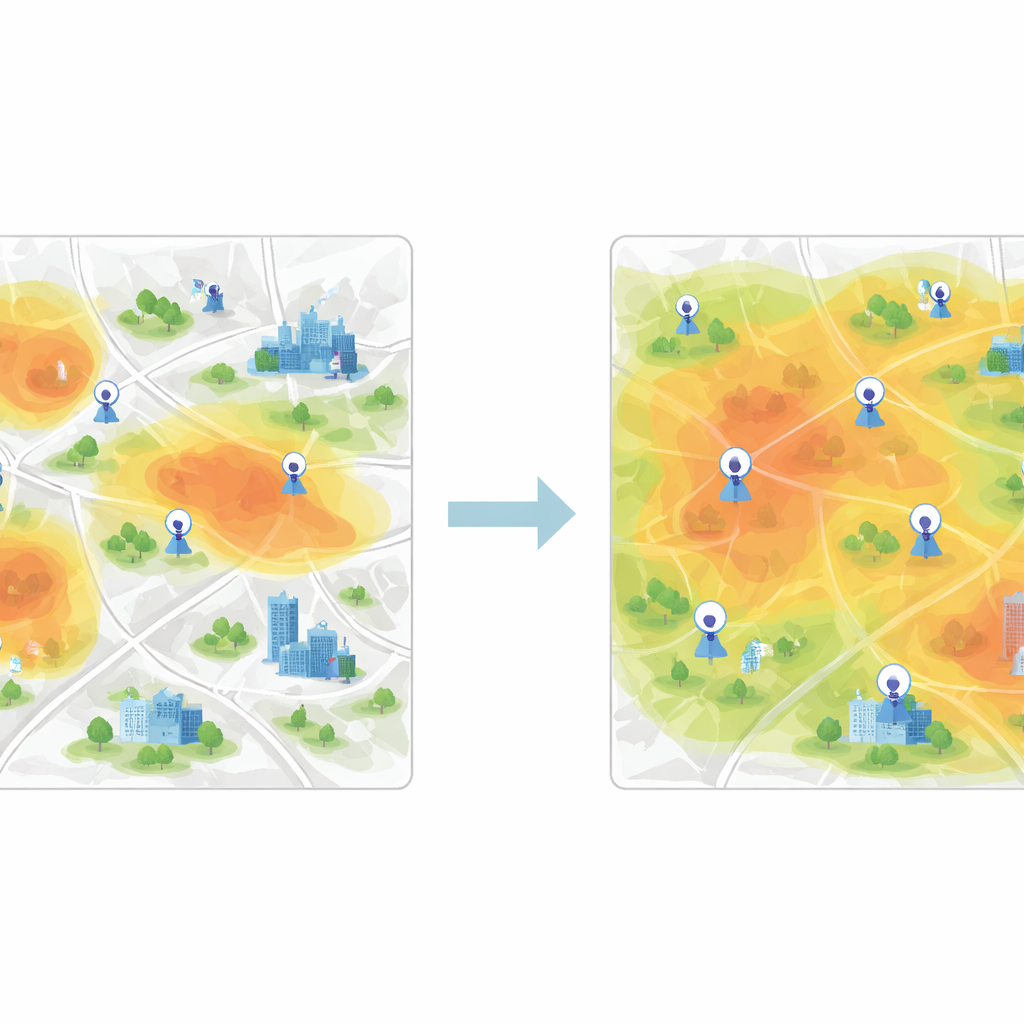
Ähnliche Gebiete gruppieren, um die Stadt fair abzudecken
Sobald diese Merkmalsvektoren erlernt sind, besteht der nächste Schritt darin, Gitterzellen mit ähnlichem Luftqualitätsverhalten zu gruppieren. Dazu verwendet die Studie K-Means-Clustering, einen Algorithmus, der Daten in eine vorgegebene Anzahl von Clustern aufteilt. Wird das Clustering direkt auf Rohmessungen angewandt, sind die Grenzen zwischen Gruppen verschwommen und der Algorithmus konvergiert langsam. Nach der CNN-basierten Merkmalsextraktion werden die Cluster jedoch viel klarer, und der Algorithmus findet schnell stabile Zentren, die typische Verschmutzungsmuster repräsentieren. Jedes Cluster steht für eine Zone in der Stadt, in der die Luft ähnlich reagiert, selbst wenn die darin enthaltenen Viertel auf der Karte sehr unterschiedlich aussehen.
Die besten neuen Standorte mit Informationsgewinn auswählen
Um zu entscheiden, welche neuen Standorte hinzukommen sollen, führen die Autoren ein gieriges Verfahren auf Basis der Informationsentropie ein. Sie betrachten die Stadt als ein Netzwerk von Knoten, von denen einige bereits mit echten Sensordaten beschriftet sind und andere unbeschriftet. Unter Verwendung der Merkmalsähnlichkeit zwischen beschrifteten und unbeschrifteten Knoten berechnen sie, wie unsicher jeder unbeschriftete Knoten in Bezug auf seine Rolle in der Luftqualität ist. Knoten, die am wenigsten den bereits vorhandenen ähneln — oder die an Grenzen zwischen Verschmutzungsregimen liegen — haben einen höheren Informationswert. Iterativ sortiert der Algorithmus die Knoten nach diesem Maß und „befördert“ die informativsten in die beschriftete Menge und trainiert das Modell dabei jedes Mal neu. Die final empfohlenen Stationen sind diejenigen mit der höchsten durchschnittlichen Priorität über mehrere Zeiträume.
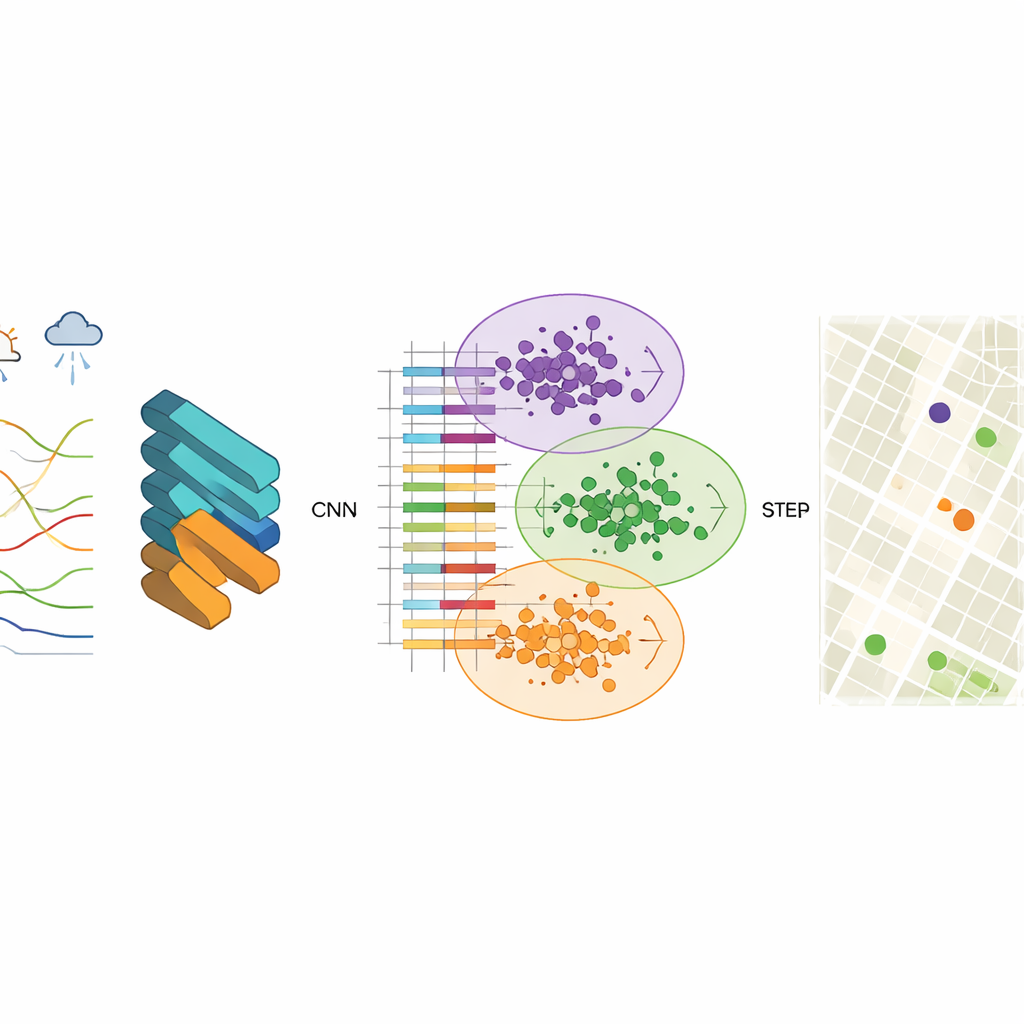
Wie gut funktioniert das in echten Städten?
Das Modell wurde an drei chinesischen Städten mit sehr unterschiedlichen Verschmutzungsniveaus getestet: einer stark industrialisierten Stadt, einer gemischt genutzten Stadt und einer saubereren Tourismusstadt, unter Verwendung von mehr als 400.000 stündlichen Aufzeichnungen von Schadstoffen und Wetterdaten. Im Vergleich zu zwei früheren Standortansätzen erreicht die neue Methode eine Korrelation von 0,96 zwischen vorhergesagten und beobachteten Luftqualitätswerten, mit mittleren Fehlern unter 1 % und starker Übereinstimmung sowohl für primäre Schadstoffe wie Grobpartikel und Schwefeldioxid als auch für sekundäre Schadstoffe wie Ozon und Stickstoffdioxid. Sie verarbeitet Daten zudem etwa doppelt so schnell wie konkurrierende Methoden, mit durchschnittlicher Latenz unter einer Sekunde, und läuft effizient über verschiedene Stadttypen, was darauf hindeutet, dass sie tägliche Aktualisierungen der Überwachungsempfehlungen unterstützen kann.
Was das für die Menschen bedeutet, die die Luft atmen
Kurz gesagt zeigt die Studie, dass eine Stadt nicht auf jedem Block Sensoren braucht, um zu wissen, wie sauber oder belastet ihre Luft ist. Indem ein neuronales Netzwerk lernt, wie sich Verschmutzung bewegt, und dann die informativsten Standorte sorgfältig ausgewählt werden, können Behörden schlankere, intelligentere Überwachungsnetze entwerfen, die die stadtweiten Bedingungen mit sehr geringen Fehlern verfolgen. Für die Bewohner verspricht ein solches System zuverlässigere Luftqualitätskarten, bessere Empfehlungen für Aktivitäten im Freien und eine solidere wissenschaftliche Grundlage für Politiken, die darauf abzielen, die Verschmutzung dort zu reduzieren, wo sie am wichtigsten ist.
Zitation: Liu, S., Peng, J. & He, X. Construction of automatic air monitoring point siting model based on convolutional neural network and K-means clustering. Sci Rep 16, 11940 (2026). https://doi.org/10.1038/s41598-026-41078-1
Schlüsselwörter: städtische Luftqualität, Sensorplatzierung, Deep Learning, Umweltüberwachung, Verschmutzungskartierung