Clear Sky Science · fr
Construction d’un modèle automatique de localisation des points de surveillance de l’air basé sur un réseau de neurones convolutionnel et le regroupement K-means
Pourquoi des moniteurs d’air plus intelligents comptent pour la vie urbaine
Les citadins respirent un air façonné par le trafic, les usines et la météo, mais la plupart des villes ne peuvent financer qu’un nombre limité de stations de surveillance. Cet article présente une nouvelle méthode pour décider précisément où installer ces stations afin qu’un ensemble restreint de capteurs fournisse néanmoins une image fidèle de la pollution sur l’ensemble d’un territoire urbain. En combinant des algorithmes modernes de reconnaissance de motifs avec un regroupement astucieux des lieux similaires, les auteurs visent à cartographier la qualité de l’air à l’échelle de la ville avec une grande précision tout en maîtrisant les coûts et le temps de calcul.
Passer de relevés fragmentaires à un panorama complet
Les réseaux de surveillance traditionnels laissent de larges zones non couvertes entre les stations, si bien que la qualité de l’air dans de nombreux quartiers reste pratiquement inconnue. En parallèle, multiplier les stations revient trop cher et se révèle souvent impraticable. L’étude se concentre sur le problème de localisation : étant donné une ville divisée en petites cellules de grille et un budget limité pour les capteurs, quels emplacements doivent être surveillés pour que les relevés reflètent les schémas de pollution partout et pas seulement près des sites existants ? Les auteurs soutiennent que de bons choix doivent tenir compte de la variation de la pollution dans l’espace et le temps et de son façonnement par la météo, le trafic et l’usage des sols, et pas seulement par des moyennes en quelques points.
Laisser un réseau de neurones apprendre les motifs
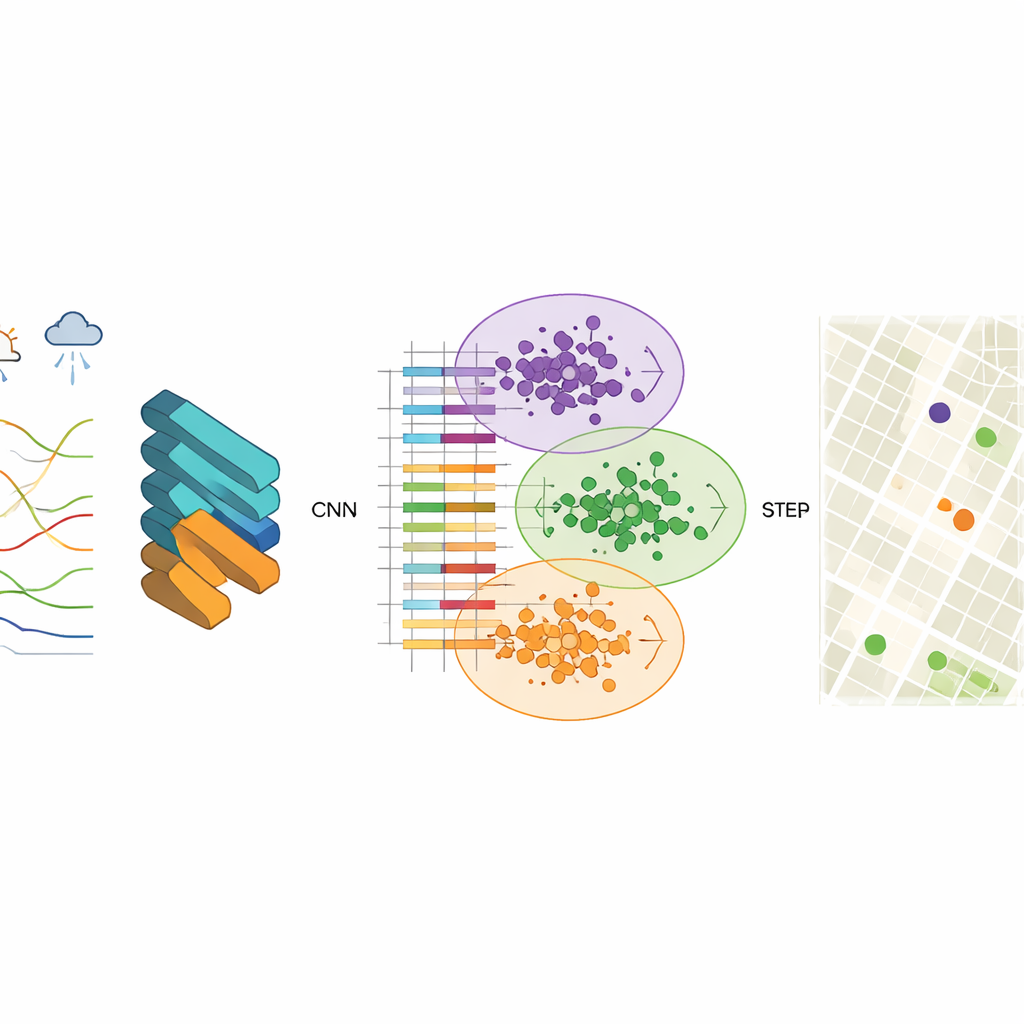
Pour découvrir ces motifs, les chercheurs utilisent un réseau de neurones convolutionnel (CNN), un type de modèle d’apprentissage profond habituellement employé pour la reconnaissance d’images. Ici, les « images » sont des enregistrements structurés de la qualité de l’air incluant des niveaux de polluants tels que particules fines, particules grossières, ozone et monoxyde de carbone, ainsi que la température, l’humidité, le vent et d’autres facteurs. Le CNN apprend des vecteurs de caractéristiques compacts — des résumés numériques condensés — qui capturent le comportement de la pollution dans l’espace et le temps. L’équipe constate que l’utilisation de 256 nœuds cachés offre un bon compromis entre précision et rapidité, produisant des sorties stables et des erreurs de prédiction très faibles lors de la reconstruction des données observées.
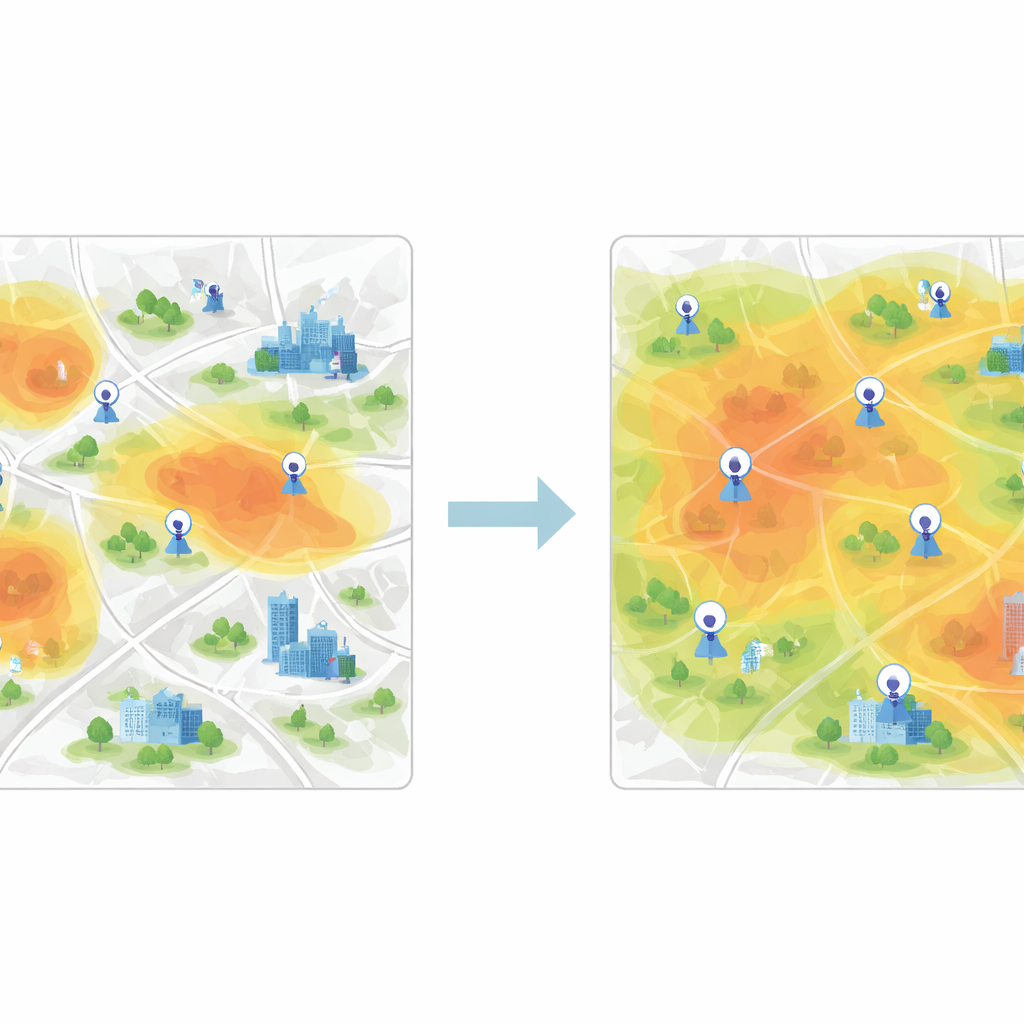
Regrouper les zones similaires pour couvrir la ville équitablement
Une fois ces vecteurs de caractéristiques appris, l’étape suivante consiste à regrouper les cellules de la grille présentant un comportement similaire de la qualité de l’air. Pour cela, l’étude utilise le regroupement K-means, un algorithme qui sépare les données en un nombre prédéterminé de clusters. Lorsqu’on applique le clustering directement aux mesures brutes, les frontières entre groupes sont floues et l’algorithme converge lentement. Après l’extraction de caractéristiques par le CNN, toutefois, les clusters deviennent beaucoup plus nets et l’algorithme trouve rapidement des centres stables représentant des schémas de pollution typiques. Chaque cluster représente une zone de la ville où l’air se comporte de manière semblable, même si les quartiers qui la composent peuvent paraître très différents sur une carte.
Choisir les meilleurs nouveaux emplacements avec le gain d’information
Pour décider quels nouveaux sites ajouter, les auteurs introduisent une procédure gloutonne basée sur l’entropie de l’information. Ils considèrent la ville comme un réseau de nœuds, certains déjà étiquetés par des données de capteurs réels et d’autres non étiquetés. En utilisant la similarité des caractéristiques entre nœuds étiquetés et non étiquetés, ils calculent l’incertitude de chaque nœud non étiqueté quant à son rôle en matière de qualité de l’air. Les nœuds les moins semblables aux nœuds existants — ou situés près des frontières entre régimes de pollution — présentent une valeur informationnelle plus élevée. De manière itérative, l’algorithme classe les nœuds selon cette mesure et « promeut » les plus informatifs dans l’ensemble étiqueté, réentraînant le modèle à chaque étape. Les stations finalement recommandées sont celles qui affichent la priorité moyenne la plus élevée sur plusieurs périodes temporelles.
Que vaut la méthode dans des villes réelles ?
Le modèle est testé sur trois villes chinoises aux niveaux de pollution très différents : une ville fortement industrialisée, une ville à usages mixtes et une ville touristique plus propre, en s’appuyant sur plus de 400 000 enregistrements horaires de polluants et de paramètres météorologiques. Comparée à deux approches de localisation antérieures, la nouvelle méthode obtient une corrélation de 0,96 entre valeurs de qualité de l’air prédites et observées, avec des erreurs moyennes inférieures à 1 % et une forte concordance pour les polluants primaires (comme les particules grossières et le dioxyde de soufre) ainsi que pour les polluants secondaires (comme l’ozone et le dioxyde d’azote). Elle traite également les données environ deux fois plus rapidement que les méthodes concurrentes, avec une latence moyenne inférieure à la seconde, et fonctionne efficacement sur différents types de villes, ce qui indique qu’elle peut soutenir des mises à jour quotidiennes des recommandations de surveillance.
Ce que cela signifie pour les personnes qui respirent l’air
En termes simples, l’étude montre qu’une ville n’a pas besoin de capteurs à chaque coin de rue pour connaître la propreté ou la saleté de son air. En laissant un réseau de neurones apprendre comment la pollution se déplace puis en sélectionnant soigneusement les emplacements les plus informatifs, les autorités peuvent concevoir des réseaux de surveillance plus légers et plus intelligents qui suivent l’état de la ville avec des erreurs très faibles. Pour les habitants, ce type de système promet des cartes de qualité de l’air plus fiables, de meilleurs conseils pour les activités en extérieur et une base scientifique plus solide pour des politiques visant à réduire la pollution là où elle compte le plus.
Citation: Liu, S., Peng, J. & He, X. Construction of automatic air monitoring point siting model based on convolutional neural network and K-means clustering. Sci Rep 16, 11940 (2026). https://doi.org/10.1038/s41598-026-41078-1
Mots-clés: qualité de l’air urbain, implantation de capteurs, apprentissage profond, surveillance environnementale, cartographie de la pollution