Clear Sky Science · pl
Budowa automatycznego modelu wyboru lokalizacji punktów monitoringu powietrza oparta na sieci konwolucyjnej i grupowaniu K-means
Dlaczego inteligentniejsze czujniki powietrza mają znaczenie dla życia miejskiego
Mieszkańcy miast oddychają powietrzem ukształtowanym przez ruch drogowy, fabryki i pogodę, a mimo to większość miast może pozwolić sobie tylko na niewielką liczbę stacji pomiarowych. Artykuł przedstawia nowy sposób decydowania o tym, gdzie dokładnie takie stacje powinny się znaleźć, tak aby ograniczona liczba czujników nadal dawała jasny obraz zanieczyszczeń w całym obszarze miejskim. Łącząc nowoczesne algorytmy rozpoznawania wzorców z przemyślanym grupowaniem podobnych miejsc, autorzy dążą do mapowania jakości powietrza w mieście z wysoką dokładnością przy jednoczesnym ograniczeniu kosztów i czasu obliczeń.
Od fragmentarycznych odczytów do pełnego obrazu
Tradycyjne sieci monitoringu powietrza pozostawiają duże luki między stacjami, dlatego jakość powietrza w wielu dzielnicach jest w praktyce nieznana. Jednocześnie dodanie znacznie większej liczby stacji jest zbyt kosztowne i często niepraktyczne. Badanie koncentruje się na problemie wyboru lokalizacji: mając miasto podzielone na małe komórki siatki i ograniczony budżet na czujniki, które miejsca powinny być monitorowane, aby odczyty odzwierciedlały wzorce zanieczyszczeń wszędzie, a nie tylko w pobliżu istniejących punktów? Autorzy argumentują, że dobre wybory muszą uwzględniać, jak zanieczyszczenia zmieniają się w przestrzeni i czasie oraz jak kształtują je warunki pogodowe, ruch drogowy i użytkowanie terenu, a nie tylko średnie wartości w kilku punktach.
Pozwalając sieci neuronowej poznać wzorce
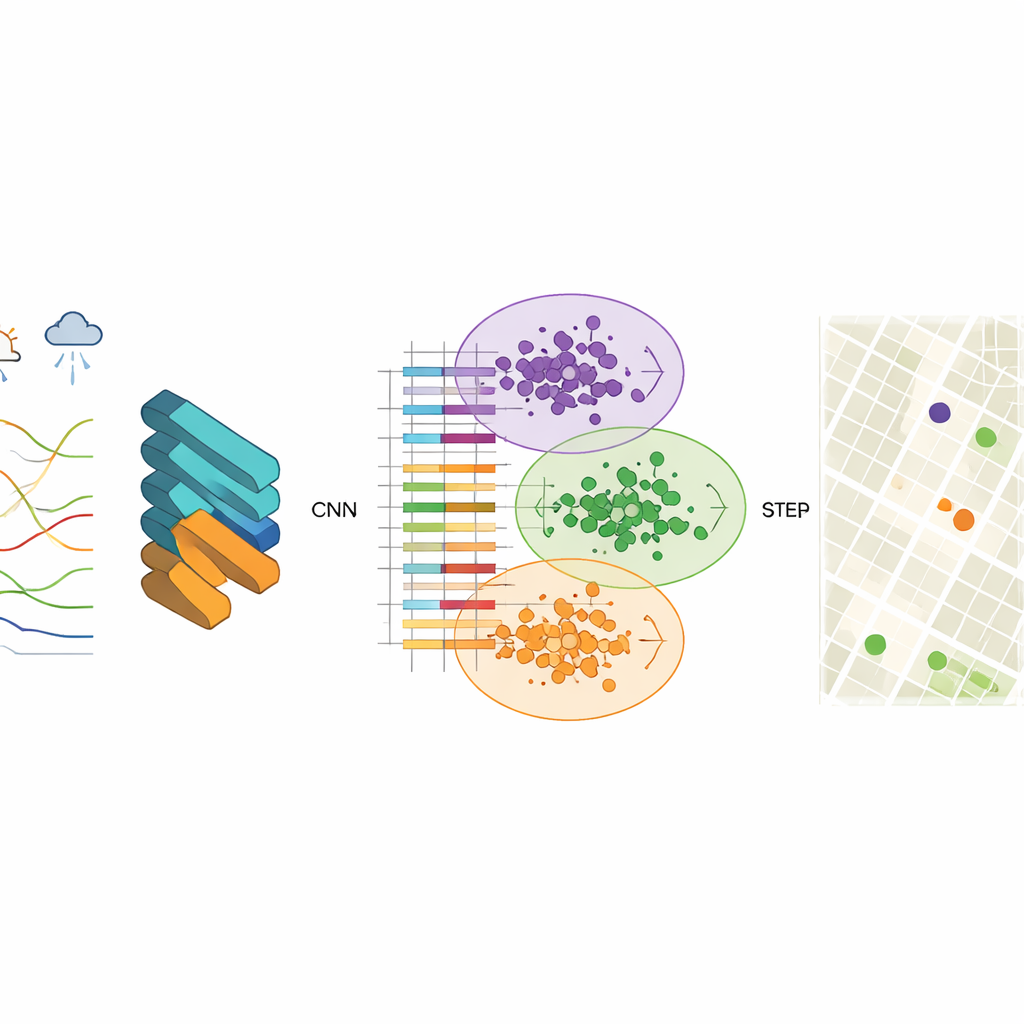
Aby odkryć te wzorce, badacze wykorzystują konwolucyjną sieć neuronową (CNN), rodzaj modelu uczenia głębokiego zwykle używanego do rozpoznawania obrazów. Tutaj „obrazy” to ustrukturyzowane zapisy jakości powietrza obejmujące poziomy zanieczyszczeń, takie jak drobne i grube cząstki, ozon i tlenek węgla, wraz z temperaturą, wilgotnością, wiatrem i innymi czynnikami. CNN uczy się zwartego wektora cech — skondensowanych, numerycznych podsumowań — które uchwycają, jak zanieczyszczenia zachowują się w przestrzeni i czasie. Zespół stwierdza, że użycie 256 ukrytych węzłów daje dobry kompromis między dokładnością a szybkością, generując stabilne wyniki i bardzo małe błędy predykcji przy rekonstruowaniu obserwowanych danych.
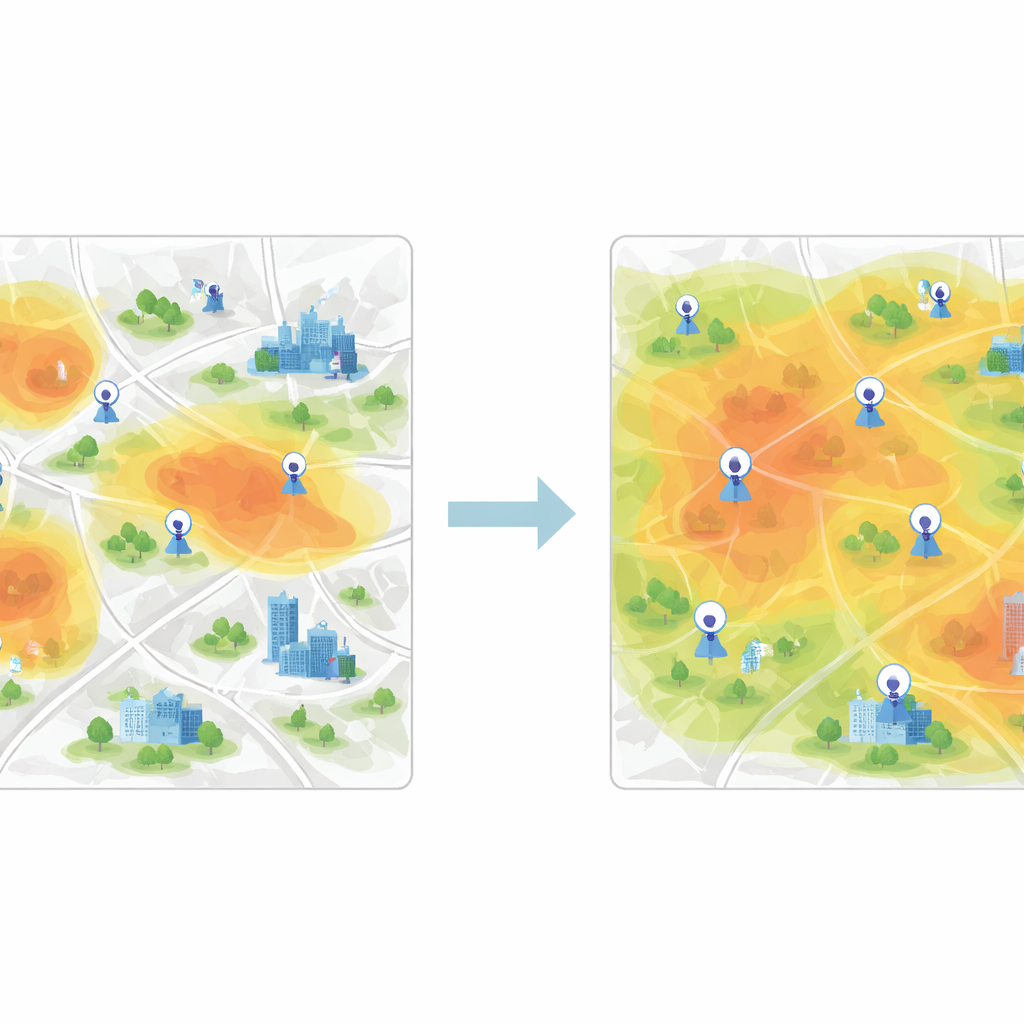
Grupowanie podobnych obszarów, aby równomiernie pokryć miasto
Gdy te wektory cech zostaną wyuczone, kolejnym krokiem jest grupowanie komórek siatki o podobnym zachowaniu jakości powietrza. Do tego celu badanie wykorzystuje grupowanie K-means, algorytm dzielący dane na uprzednio ustaloną liczbę klastrów. Gdy klastrowanie stosuje się bezpośrednio do surowych pomiarów, granice między grupami są rozmyte, a algorytm zbiega wolno. Po ekstrakcji cech przez CNN klastry stają się jednak dużo wyraźniejsze, a algorytm szybko znajduje stabilne centra reprezentujące typowe wzorce zanieczyszczeń. Każdy klaster odpowiada strefie w mieście, gdzie powietrze zachowuje się podobnie, nawet jeśli znajdujące się w niej sąsiedztwa wyglądałyby na mapie bardzo różnie.
Wybór najlepszych nowych lokalizacji za pomocą zysku informacyjnego
Aby zdecydować, które nowe miejsca dodać, autorzy wprowadzają zachłanną procedurę opartą na entropii informacji. Traktują miasto jako sieć węzłów, z których niektóre są już opisane rzeczywistymi danymi z czujników, a inne pozostają nieoznakowane. Korzystając z podobieństwa cech między węzłami oznaczonymi i nieoznaczonymi, obliczają, jak niepewny jest każdy nieoznaczony węzeł w sensie jego roli w jakości powietrza. Węzły najmniej podobne do istniejących — lub położone blisko granic między reżimami zanieczyszczeń — mają wyższą wartość informacyjną. Iteracyjnie algorytm klasyfikuje węzły według tej miary i „promuje” najbardziej informacyjne do zbioru oznaczonych, za każdym razem ponownie trenując model. Końcowe zalecane stacje to te o najwyższym średnim priorytecie w różnych przedziałach czasowych.
Jak dobrze działa to w rzeczywistych miastach?
Model przetestowano na trzech chińskich miastach o bardzo różnym poziomie zanieczyszczeń: intensywnie uprzemysłowionym mieście, mieście o mieszanym przeznaczeniu oraz czyściejszym mieście turystycznym, wykorzystując ponad 400 000 godzinnych rekordów zanieczyszczeń i parametrów pogodowych. W porównaniu z dwoma wcześniejszymi podejściami do wyboru lokalizacji, nowa metoda osiąga korelację 0,96 między wartościami prognozowanymi a obserwowanymi, ze średnimi błędami poniżej 1% oraz silną zgodnością zarówno dla zanieczyszczeń pierwotnych, takich jak grube cząstki i dwutlenek siarki, jak i wtórnych, takich jak ozon i dwutlenek azotu. Przetwarza też dane około dwukrotnie szybciej niż metody konkurencyjne, z średnią latencją poniżej sekundy, i działa wydajnie we wszystkich typach miast, co sugeruje, że może wspierać codzienne aktualizacje zaleceń dotyczących monitoringu.
Co to oznacza dla osób oddychających powietrzem
Mówiąc prosto, badanie pokazuje, że miasto nie potrzebuje czujników na każdym rogu, aby wiedzieć, jak czyste lub zanieczyszczone jest jego powietrze. Pozwalając sieci neuronowej poznać, jak zanieczyszczenia się przemieszczają, a następnie starannie wybierając najbardziej informatywne lokalizacje, władze mogą zaprojektować bardziej oszczędne, inteligentniejsze sieci monitoringu, które śledzą warunki w całym mieście z bardzo małymi błędami. Dla mieszkańców taki system obiecuje bardziej wiarygodne mapy jakości powietrza, lepsze wskazówki dotyczące aktywności na zewnątrz oraz silniejszą podstawę naukową dla polityk mających na celu ograniczanie zanieczyszczeń tam, gdzie ma to największe znaczenie.
Cytowanie: Liu, S., Peng, J. & He, X. Construction of automatic air monitoring point siting model based on convolutional neural network and K-means clustering. Sci Rep 16, 11940 (2026). https://doi.org/10.1038/s41598-026-41078-1
Słowa kluczowe: jakość powietrza w mieście, rozmieszczenie czujników, uczenie głębokie, monitoring środowiska, mapowanie zanieczyszczeń