Clear Sky Science · zh
基于多重情绪与强度驱动的响应生成以丰富多模态对话
为什么更聪明的聊天机器人需要更像我们一样“有感情”
如今我们大多数人都在手机、电脑或智能音箱上与数字助手对话。这些系统擅长回答问题,但常常忽视我们话语背后的情绪语气。本文探讨如何构建一种 AI,不仅识别单一情绪,而是能混合多种感受并匹配每种感受的强度,同时综合我们的语音、面部线索和文本。
从简单情绪到层次化感受
日常对话很少是纯粹的喜悦或纯粹的愤怒。一句话可能既包含惊讶又有喜悦,或愤怒夹杂厌恶,而且每种情绪可能强弱不同。早期的对话系统通常试图将每条信息归到一个主要情绪上。即便承认可能存在多种情绪,它们也常把这些情绪视为同等强度。因此,系统的回复要么显得平淡,要么过于夸张,无法保留应在回复中占主导地位的情绪。
用眼睛、耳朵和语言去倾听
为了解决这一问题,作者基于来自八部流行英语电视剧的大量场景,涵盖戏剧与喜剧两类。原始数据集 MEIMD 为每句台词标注了多种情绪及对应的强度分数,但仅保存了剧本文本。研究者通过添加相应的音频和视频片段对其进行了扩充,形成了新的多模态资源 MEIMD++。现在每句话都配有演员的声音和面部表情以及文字,提供了情绪实际表达的更全面视角。
新对话模型的内部工作原理
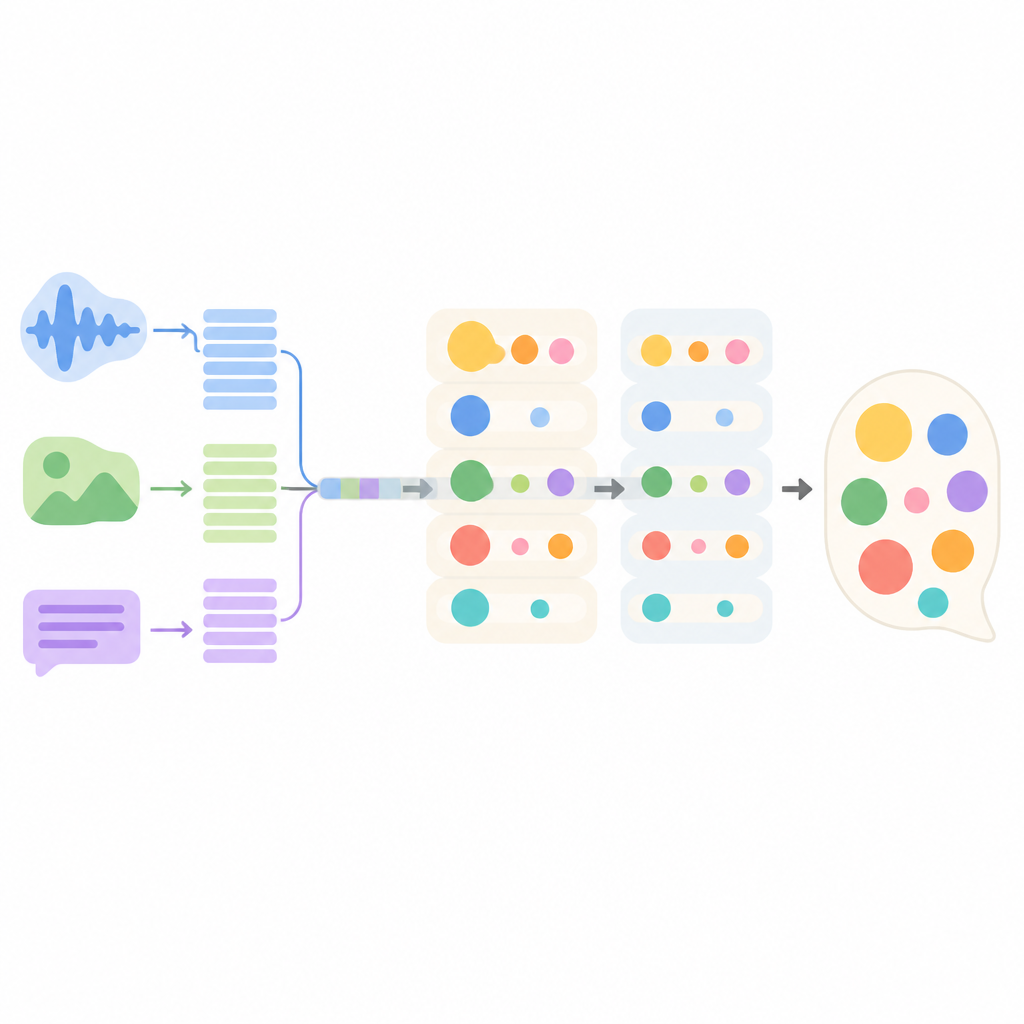
所提出的系统称为 MMEI-DD,由若干关注不同信号的深度学习组件构成。一部分读取对话文本,另一部分处理视频帧,第三部分分析音频。一个专门模块学习这些流之间的关联,例如将尖锐的语调和皱眉与看似中性的句子联系起来。这种组合表示使模型在选择回复前更准确地估计出现了哪些情绪以及它们的强度。
以恰当强度混合多种情绪
模型不是在一次生成中决定单一情绪并据此回复,而是采用两阶段解码过程。第一阶段生成一个以某种情绪及其选定强度(例如强烈愤怒)为指导的初稿。第二阶段通过加入第二种情绪及其强度(例如轻微惊讶或低程度厌恶)来细化该初稿。通过将这些步骤分开,系统避免让一种情绪完全压倒其他情绪,并保持它们之间的平衡,更接近原始对话中的情感分布。
更丰富的情感线索是否带来更好的回复
为验证方法,作者将 MMEI-DD 与若干早期系统在自动评分和人工评估上进行比较。他们衡量回复的流畅性与相关性、与目标情绪的匹配程度,以及各情绪强度与目标的对齐程度。在这些测试中,新模型比仅依赖文本或忽视强度的方法产生了更连贯、更具情感细节的回复。人工评估者也评价其回答更自然、情感更贴切。
这对日常 AI 助手意味着什么
对非专业读者而言,关键观点是未来的聊天机器人和语音助手可能不仅响应我们说了什么,还能回应我们话语背后微妙的情感混合。通过同时利用声音、面部表情和语言,并对多种情绪及其强度进行精细控制,像 MMEI-DD 这样的系统正朝着那种让人感到被理解而不仅仅是被回答的对话迈进。
引用: Singh, A., Shree, R., Pandey, D. et al. Multi-emotion and intensity-driven response generation for richer multimodal dialogue. Sci Rep 16, 15696 (2026). https://doi.org/10.1038/s41598-026-41034-z
关键词: 情感聊天机器人, 多模态对话, 情感分析, 情绪强度, 会话式人工智能