Clear Sky Science · it
Generazione di risposte guidata da più emozioni e dalla loro intensità per dialoghi multimodali più ricchi
Perché i chatbot più intelligenti devono somigliare di più a noi
Oggi la maggior parte di noi parla con assistenti digitali su telefoni, computer o speaker intelligenti. Questi sistemi sono bravi a rispondere a domande, ma spesso non colgono il tono emotivo che sta dietro alle nostre parole. Questo articolo esplora come costruire un'IA che non si limita a riconoscere un singolo stato d'animo, ma sa mescolare più sentimenti contemporaneamente e valutare quanto è forte ciascuno di essi, usando insieme voce, segnali facciali e testo.
Da umori semplici a sensazioni stratificate
Le conversazioni quotidiane raramente sono pura gioia o pura rabbia. Una singola frase può contenere sorpresa e felicità, oppure rabbia mista a disgusto, e ogni sentimento può essere debole o intenso. I sistemi di dialogo precedenti cercavano di solito di assegnare a ogni messaggio un'unica emozione principale. Anche quando ammettevano la presenza di più emozioni, spesso le trattavano tutte con la stessa intensità. Di conseguenza, le loro risposte suonavano piatte o esagerate e non riflettevano quale emozione dovesse predominare nella risposta.
Ascoltare con occhi, orecchie e parole
Per affrontare questo problema, gli autori si basano su un'ampia raccolta di scene tratte da otto popolari serie televisive in lingua inglese, che comprendono sia drama sia commedie. Il dataset originale, chiamato MEIMD, etichettava ogni battuta con più emozioni e un punteggio di intensità per ciascuna, ma conservava solo il testo della sceneggiatura. I ricercatori lo ampliano aggiungendo i corrispondenti clip audio e video, creando una nuova risorsa multimodale chiamata MEIMD++. Ora ogni frase è associata alla voce e alle espressioni facciali dell'attore oltre che alle parole, offrendo una visione più completa di come le emozioni vengono effettivamente espresse.
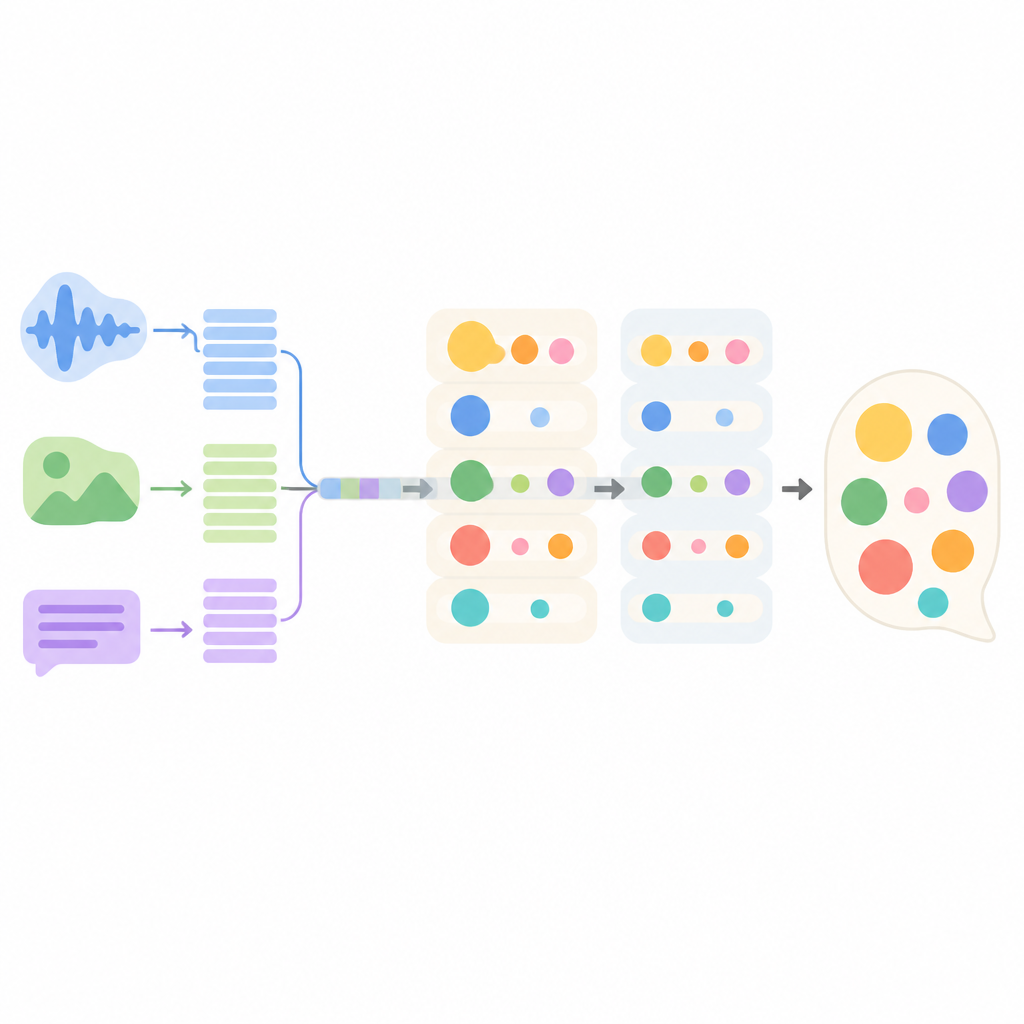
Come funziona internamente il nuovo modello di conversazione
Il sistema proposto, chiamato MMEI-DD, è composto da diversi moduli di deep learning che si concentrano ciascuno su un segnale diverso. Una parte legge il testo del dialogo, un'altra elabora i fotogrammi video e una terza ascolta l'audio. Un modulo speciale impara poi come questi flussi si relazionano tra loro, ad esempio collegando un tono acuto e una smorfia a una frase apparentemente neutra. Questa rappresentazione combinata permette al modello di stimare meglio quali emozioni sono presenti e quanto sono intense prima di scegliere una risposta.
Mischiare più emozioni alla giusta intensità
Invece di decidere un unico stato d'animo e generare la risposta in un solo passaggio, il modello usa un processo di decodifica in due fasi. Nella prima fase produce una bozza di risposta guidata da un'emozione e dalla sua intensità scelta, ad esempio rabbia forte. Nella seconda fase affina quella bozza aggiungendo una seconda emozione e la sua intensità, come sorpresa lieve o disgusto basso. Separando questi passaggi, il sistema evita che un sentimento sovrasti completamente gli altri e mantiene l'equilibrio tra di essi più vicino a quanto appare nella conversazione originale.
Indizi emotivi più ricchi portano a risposte migliori?
Per testare il loro approccio, gli autori confrontano MMEI-DD con diversi sistemi precedenti sia su metriche automatiche sia su giudizi umani. Misurano quanto le risposte siano fluenti e rilevanti, quanto corrispondano alle emozioni previste e quanto l'intensità di ciascuna emozione si allinei con l'obiettivo. In questi test, il nuovo modello produce risposte più coerenti e ricche di dettagli emotivi rispetto a metodi che si basano solo sul testo o che ignorano l'intensità. Anche i valutatori umani giudicano le sue risposte più naturali e adeguate emotivamente.
Cosa significa questo per gli assistenti IA di tutti i giorni
Per il pubblico generale, il messaggio chiave è che i chatbot e gli assistenti vocali del futuro potranno rispondere non solo a ciò che diciamo, ma al sottile mix di sentimenti che sta dietro alle nostre parole. Attraendo insieme suono, espressione facciale e linguaggio, e controllando con cura più emozioni e le loro intensità, sistemi come MMEI-DD si avvicinano a conversazioni che danno la sensazione di essere comprese piuttosto che semplicemente risposte.
Citazione: Singh, A., Shree, R., Pandey, D. et al. Multi-emotion and intensity-driven response generation for richer multimodal dialogue. Sci Rep 16, 15696 (2026). https://doi.org/10.1038/s41598-026-41034-z
Parole chiave: chatbot emotivi, dialogo multimodale, analisi del sentiment, intensità delle emozioni, IA conversazionale