Clear Sky Science · es
Generación de respuestas multimodales guiada por múltiples emociones e intensidades para diálogos más ricos
Por qué los chatbots más inteligentes deben parecerse más a nosotros
La mayoría de nosotros ya hablamos con asistentes digitales en el teléfono, el ordenador o los altavoces inteligentes. Estos sistemas son buenos respondiendo preguntas, pero con frecuencia no captan el tono emocional detrás de nuestras palabras. Este artículo explora cómo construir IA que no solo reconozca un único estado de ánimo, sino que pueda mezclar varios sentimientos a la vez y ajustar la intensidad de cada uno, usando conjuntamente la voz, las expresiones faciales y el texto.
De estados de ánimo simples a sentimientos en capas
Las conversaciones cotidianas rara vez son pura alegría o pura ira. Una sola frase puede contener sorpresa y felicidad, o ira mezclada con disgusto, y cada sentimiento puede ser débil o intenso. Los sistemas de diálogo anteriores solían intentar asignar a cada mensaje una emoción principal. Incluso cuando admitían la presencia de varias emociones, a menudo las trataban todas por igual en cuanto a intensidad. Como resultado, sus respuestas sonaban planas o exageradas y no conservaban cuál emoción debía dominar la respuesta.
Escuchar con ojos, oídos y palabras
Para abordar esto, los autores se basan en una gran colección de escenas de ocho series de televisión en inglés populares, que cubren drama y comedia. El conjunto de datos original, llamado MEIMD, etiquetaba cada línea de diálogo con varias emociones y una puntuación de intensidad para cada una, pero solo conservaba el texto del guion. Los investigadores lo enriquecen añadiendo los clips de audio y vídeo correspondientes, creando un nuevo recurso multimodal llamado MEIMD++. Ahora cada frase viene con la voz y las expresiones faciales del actor además de las palabras, ofreciendo una visión más completa de cómo se expresan realmente las emociones.
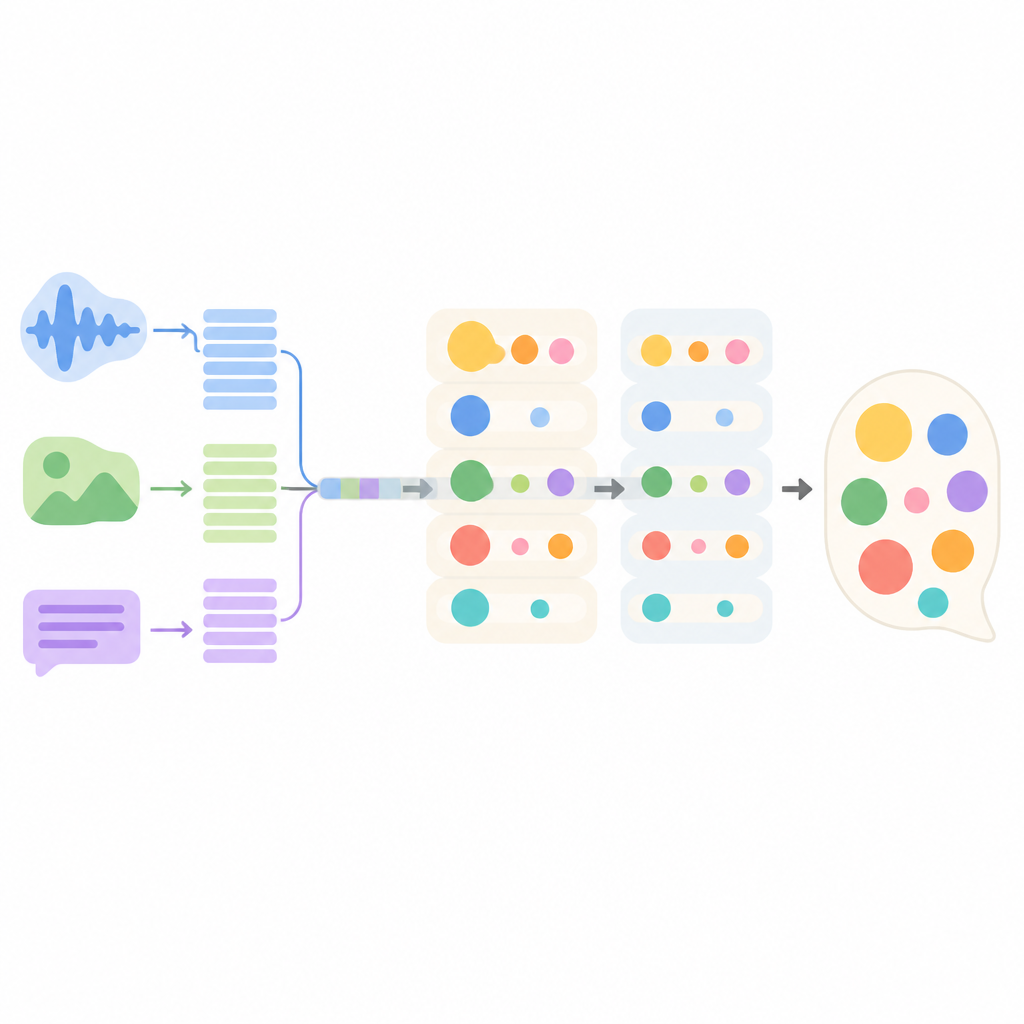
Cómo funciona el nuevo modelo de conversación por dentro
El sistema propuesto, llamado MMEI-DD, se construye a partir de varios componentes de aprendizaje profundo que se centran en distintas señales. Una parte lee el texto del diálogo, otra procesa los fotogramas de vídeo y una tercera escucha el sonido. Un módulo especial aprende entonces cómo se relacionan estos flujos entre sí, por ejemplo vinculando un tono agudo y un ceño fruncido a una frase aparentemente neutra. Esta representación combinada permite al modelo estimar mejor qué emociones están presentes y qué intensidad tienen antes de elegir una respuesta.
Mezclar varias emociones con la intensidad adecuada
En lugar de decidir un único estado de ánimo y generar una respuesta en un solo paso, el modelo usa un proceso de decodificación en dos etapas. En la primera etapa produce un borrador de respuesta guiado por una emoción y su intensidad elegida, como ira intensa. En la segunda etapa refina ese borrador añadiendo una segunda emoción y su fuerza, como sorpresa leve o disgusto bajo. Al separar estos pasos, el sistema evita que un sentimiento anule completamente a los demás y mantiene el equilibrio entre ellos más cercano a lo que aparece en la conversación original.
¿Conducen las señales emocionales más ricas a respuestas mejores?
Para probar su enfoque, los autores comparan MMEI-DD con varios sistemas anteriores tanto mediante puntuaciones automáticas como juicios humanos. Miden qué tan fluidas y relevantes son las respuestas, qué tan bien coinciden con las emociones previstas y cuán alineada está la intensidad de cada emoción con el objetivo. En estas pruebas, el nuevo modelo produce respuestas más coherentes y emocionalmente detalladas que los métodos que solo dependen del texto o que ignoran la intensidad. Los evaluadores humanos también valoran sus respuestas como más naturales y emocionalmente apropiadas.
Qué significa esto para los asistentes de IA cotidianos
Para el público no especializado, el mensaje clave es que los futuros chatbots y asistentes de voz podrían responder no solo a lo que decimos, sino a la mezcla sutil de sentimientos detrás de nuestras palabras. Al recurrir conjuntamente al sonido, la expresión facial y el lenguaje, y al controlar con cuidado varias emociones y sus intensidades, sistemas como MMEI-DD se acercan a conversaciones que se sienten comprendidas en lugar de simplemente respondidas.
Cita: Singh, A., Shree, R., Pandey, D. et al. Multi-emotion and intensity-driven response generation for richer multimodal dialogue. Sci Rep 16, 15696 (2026). https://doi.org/10.1038/s41598-026-41034-z
Palabras clave: chatbots emocionales, diálogo multimodal, análisis de sentimiento, intensidad emocional, IA conversacional