Clear Sky Science · pl
Generowanie odpowiedzi napędzane wieloma emocjami i ich intensywnościami dla bogatszego dialogu multimodalnego
Dlaczego mądrzejsze chatboty muszą bardziej przypominać nas
Wielu z nas rozmawia dziś z cyfrowymi pomocnikami na telefonach, komputerach czy głośnikach inteligentnych. Systemy te dobrze odpowiadają na pytania, lecz często nie wychwytują emocjonalnego tonu naszych słów. Niniejszy artykuł bada, jak zbudować AI, które nie tylko rozpoznaje pojedynczy nastrój, lecz potrafi mieszać kilka uczuć naraz i oceniać, jak silne są każde z nich, wykorzystując jednocześnie mowę, sygnały twarzy i tekst.
Od prostych nastrojów do wielowarstwowych uczuć
Codzienne rozmowy rzadko są czystą radością albo czystym gniewem. Jedno zdanie może nieść zaskoczenie i szczęście, albo gniew wymieszany z obrzydzeniem, a każde z tych uczuć może być słabe lub silne. Wcześniejsze systemy dialogowe zwykle próbowały przypisać wiadomości jedną dominującą emocję. Nawet gdy brały pod uwagę obecność kilku emocji, często traktowały je wszystkie jako jednakowo silne. W efekcie ich odpowiedzi brzmiały albo płasko, albo przesadnie, i nie odzwierciedlały, która emocja powinna dominować.
Słuchanie oczami, uszami i słowami
Aby temu sprostać, autorzy korzystają z obszernej kolekcji scen z ośmiu popularnych anglojęzycznych seriali telewizyjnych, obejmujących dramat i komedię. Oryginalny zbiór danych, nazwany MEIMD, oznaczył każdą kwestię kilkoma emocjami i przypisał każdej z nich wartość intensywności, lecz przechowywał jedynie tekst scenariusza. Badacze rozszerzają go, dodając odpowiadające fragmenty audio i wideo, tworząc nowy multimodalny zasób nazwany MEIMD++. Teraz każde zdanie zawiera głos aktora i wyraz twarzy oraz słowa, oferując pełniejszy obraz tego, jak emocje są faktycznie wyrażane.
Jak działa nowy model konwersacyjny wewnątrz
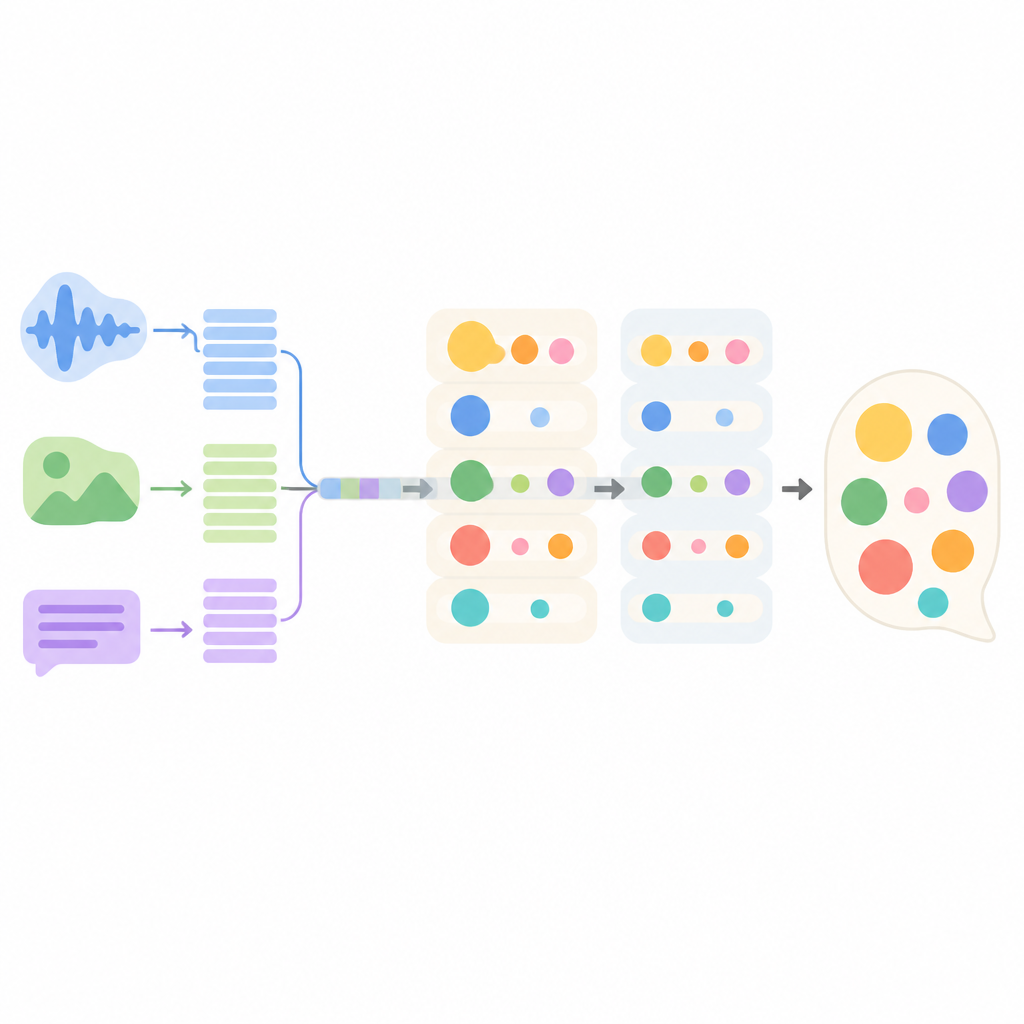
Proponowany system, nazwany MMEI-DD, zbudowany jest z kilku komponentów głębokiego uczenia, z których każdy koncentruje się na innym sygnale. Jedna część odczytuje tekst dialogu, inna przetwarza klatki wideo, a trzecia nasłuchuje dźwięku. Specjalny moduł uczy się powiązań między tymi strumieniami, na przykład łącząc ostry ton głosu i zmarszczenie czoła z pozornie neutralnym zdaniem. Ta połączona reprezentacja pozwala modelowi lepiej ocenić, które emocje są obecne i jak silne są, zanim wybierze odpowiedź.
Mieszanie kilku emocji we właściwej sile
Zamiast wybierać jeden nastrój i generować odpowiedź w jednym kroku, model używa dwuetapowego procesu dekodowania. W pierwszym etapie tworzy wersję roboczą odpowiedzi kierowaną jedną emocją i wybraną jej intensywnością, na przykład silnym gniewem. W drugim etapie dopracowuje tę wersję, dodając drugą emocję i jej natężenie, na przykład łagodne zaskoczenie lub niewielkie obrzydzenie. Dzięki rozdzieleniu tych kroków system unika całkowitego zdominowania przez jedno uczucie i utrzymuje równowagę między nimi bliższą tej, która występuje w oryginalnej rozmowie.
Czy bogatsze wskazówki emocjonalne prowadzą do lepszych odpowiedzi
Aby przetestować swoje podejście, autorzy porównują MMEI-DD z kilkoma wcześniejszymi systemami, używając zarówno automatycznych metryk, jak i ocen ludzkich. Mierzą płynność i trafność odpowiedzi, jak dobrze odpowiadają zamierzonym emocjom oraz jak blisko siła każdej emocji pokrywa się z celem. W tych testach nowy model generuje bardziej spójne, emocjonalnie szczegółowe odpowiedzi niż metody oparte wyłącznie na tekście lub ignorujące intensywność. Oceny ludzkie także wskazują, że jego odpowiedzi są bardziej naturalne i emocjonalnie stosowne.
Co to oznacza dla codziennych asystentów AI
Dla osób niebędących specjalistami kluczowy wniosek jest taki, że przyszłe chatboty i asystenci głosowi mogą reagować nie tylko na to, co mówimy, lecz na subtelne mieszanki uczuć kryjące się za naszymi słowami. Dzięki łączeniu dźwięku, mimiki i języka oraz precyzyjnemu kontrolowaniu kilku emocji i ich intensywności, systemy takie jak MMEI-DD zbliżają nas do rozmów, które bardziej pozwalają się poczuć zrozumianym niż po prostu otrzymać odpowiedź.
Cytowanie: Singh, A., Shree, R., Pandey, D. et al. Multi-emotion and intensity-driven response generation for richer multimodal dialogue. Sci Rep 16, 15696 (2026). https://doi.org/10.1038/s41598-026-41034-z
Słowa kluczowe: emocjonalne chatboty, dialog multimodalny, analiza nastroju, intensywność emocji, AI konwersacyjne