Clear Sky Science · fr
Génération de réponses guidée par plusieurs émotions et leur intensité pour des dialogues multimodaux plus riches
Pourquoi des chatbots plus intelligents doivent nous ressembler davantage sur le plan émotionnel
La plupart d’entre nous dialoguent aujourd’hui avec des assistants numériques sur nos téléphones, ordinateurs ou enceintes connectées. Ces systèmes sont performants pour répondre à des questions, mais passent souvent à côté de la tonalité émotionnelle de nos propos. Cet article examine comment concevoir une IA qui ne se contente pas d’identifier une humeur unique, mais peut mêler plusieurs sentiments simultanément et évaluer la force de chacun, en exploitant ensemble la voix, les indices faciaux et le texte.
Des humeurs simples à des émotions à plusieurs couches
Les conversations quotidiennes sont rarement une joie pure ou une colère pure. Une même phrase peut exprimer à la fois surprise et bonheur, ou de la colère mêlée de dégoût, et chaque émotion peut être faible ou intense. Les systèmes de dialogue antérieurs tentaient généralement d’attribuer un unique état émotionnel à chaque message. Même lorsqu’ils acceptaient la présence de plusieurs émotions, ils traitaient souvent toutes les émotions comme ayant la même intensité. En conséquence, leurs réponses semblaient soit fades soit excessives, sans respecter laquelle des émotions devait dominer la réplique.
Écouter avec les yeux, les oreilles et les mots
Pour relever ce défi, les auteurs s’appuient sur une vaste collection de scènes tirées de huit séries télévisées anglophones populaires, couvrant le drame et la comédie. Le jeu de données original, nommé MEIMD, étiquetait chaque réplique avec plusieurs émotions et un score d’intensité pour chacune, mais ne conservait que le texte du script. Les chercheurs l’enrichissent en ajoutant les extraits audio et vidéo correspondants, créant ainsi une ressource multimodale nouvelle baptisée MEIMD++. Désormais, chaque phrase est accompagnée de la voix et des expressions faciales de l’acteur ainsi que des mots, offrant une vision plus complète de la manière dont les émotions sont réellement exprimées.
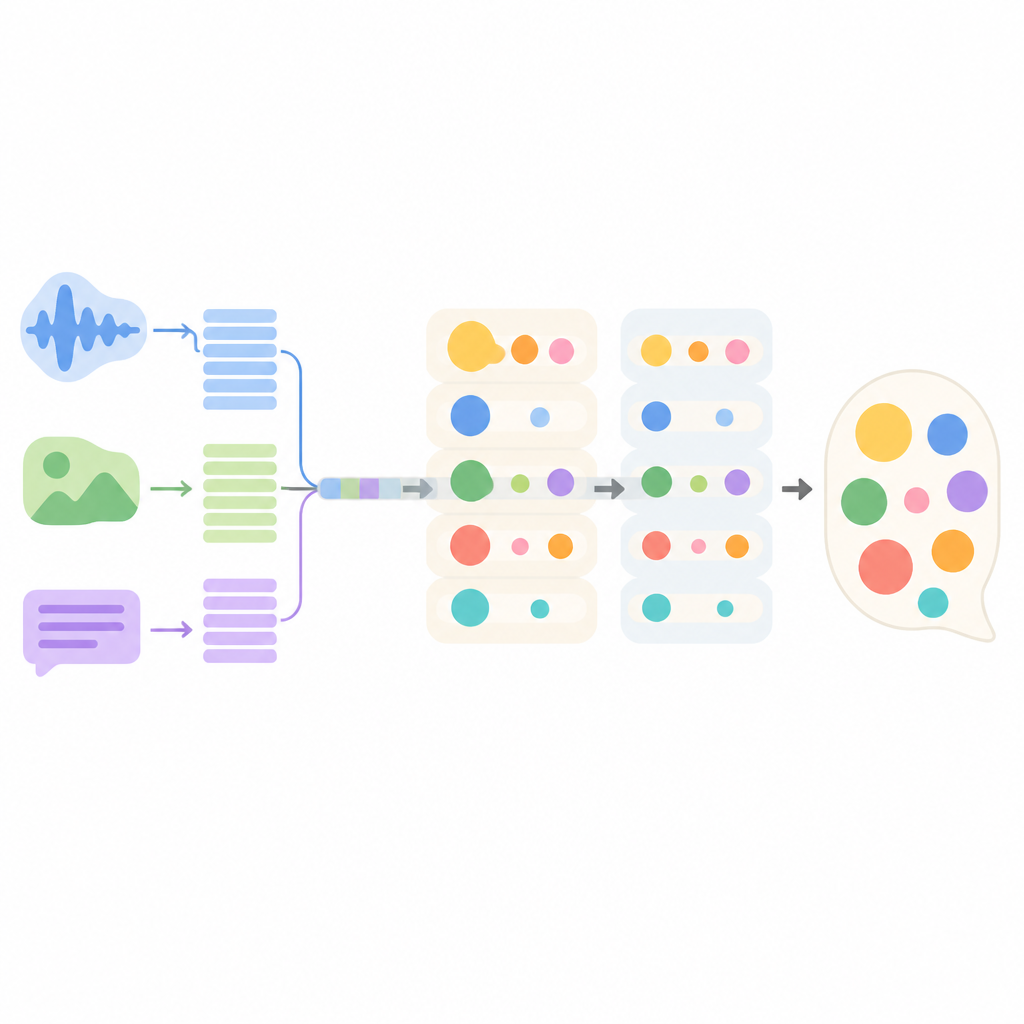
Comment fonctionne le nouveau modèle de conversation en interne
Le système proposé, nommé MMEI-DD, est composé de plusieurs composants d’apprentissage profond, chacun se concentrant sur un signal différent. Une partie lit le texte du dialogue, une autre traite les images vidéo, et une troisième écoute l’audio. Un module spécial apprend ensuite comment ces flux s’articulent entre eux, par exemple en reliant un ton sec et un froncement de sourcils à une phrase apparemment neutre. Cette représentation combinée permet au modèle d’estimer plus précisément quelles émotions sont présentes et leur intensité avant de choisir une réponse.
Mêler plusieurs émotions à la bonne intensité
Plutôt que de décider d’une seule humeur et de générer une réponse en une seule passe, le modèle utilise un processus de décodage en deux étapes. Dans la première étape, il produit un brouillon de réponse guidé par une émotion et son intensité choisie, par exemple une colère forte. Dans la deuxième étape, il affine ce brouillon en ajoutant une seconde émotion et son intensité, par exemple une légère surprise ou un faible dégoût. En séparant ces étapes, le système évite qu’un sentiment n’écrase complètement les autres et conserve un équilibre entre eux plus proche de celui observé dans la conversation d’origine.
Des indices émotionnels plus riches conduisent-ils à de meilleures réponses ?
Pour évaluer leur approche, les auteurs comparent MMEI-DD à plusieurs systèmes antérieurs en utilisant à la fois des scores automatiques et des jugements humains. Ils mesurent la fluidité et la pertinence des réponses, l’adéquation aux émotions visées, et la concordance entre l’intensité de chaque émotion et la cible. Sur l’ensemble de ces tests, le nouveau modèle génère des répliques plus cohérentes et émotionnellement détaillées que les méthodes reposant uniquement sur le texte ou ignorant l’intensité. Les évaluateurs humains jugent également ses réponses plus naturelles et émotionnellement appropriées.
Ce que cela implique pour les assistants IA de tous les jours
Pour les non-spécialistes, le message clé est que les chatbots et assistants vocaux de demain pourraient répondre non seulement à ce que nous disons, mais au mélange subtil de sentiments derrière nos mots. En s’appuyant conjointement sur le son, l’expression faciale et le langage, et en contrôlant finement plusieurs émotions et leurs intensités, des systèmes comme MMEI-DD se rapprochent de conversations qui donnent le sentiment d’être comprises plutôt que simplement traitées.
Citation: Singh, A., Shree, R., Pandey, D. et al. Multi-emotion and intensity-driven response generation for richer multimodal dialogue. Sci Rep 16, 15696 (2026). https://doi.org/10.1038/s41598-026-41034-z
Mots-clés: chatbots émotionnels, dialogue multimodal, analyse de sentiment, intensité émotionnelle, IA conversationnelle