Clear Sky Science · en
Multi-emotion and intensity-driven response generation for richer multimodal dialogue
Why smarter chatbots need to feel more like us
Most of us now talk to digital helpers on our phones, computers, or smart speakers. These systems are good at answering questions, but they often miss the emotional tone behind our words. This paper explores how to build AI that does not just recognize a single mood, but can mix several feelings at once and match how strong each of those feelings is, using our speech, facial cues, and text together.
From simple moods to layered feelings
Everyday conversations are rarely pure joy or pure anger. A single sentence can carry both surprise and happiness, or anger mixed with disgust, and each feeling may be weak or strong. Earlier dialogue systems usually tried to pin each message to one main emotion. Even when they accepted that several emotions might be present, they often treated them all as equally strong. As a result, their replies sounded either flat or over the top, and did not preserve which emotion should dominate the response.
Listening with eyes, ears, and words
To tackle this, the authors build on a large collection of scenes from eight popular English-language television shows, covering both drama and comedy. The original dataset, called MEIMD, labelled each line of dialogue with several emotions and an intensity score for each one, but only stored the script text. The researchers enrich this by adding the corresponding audio and video clips, creating a new multimodal resource named MEIMD++. Now each sentence comes with the actor’s voice and facial expressions as well as the words, offering a fuller view of how emotions are actually expressed.
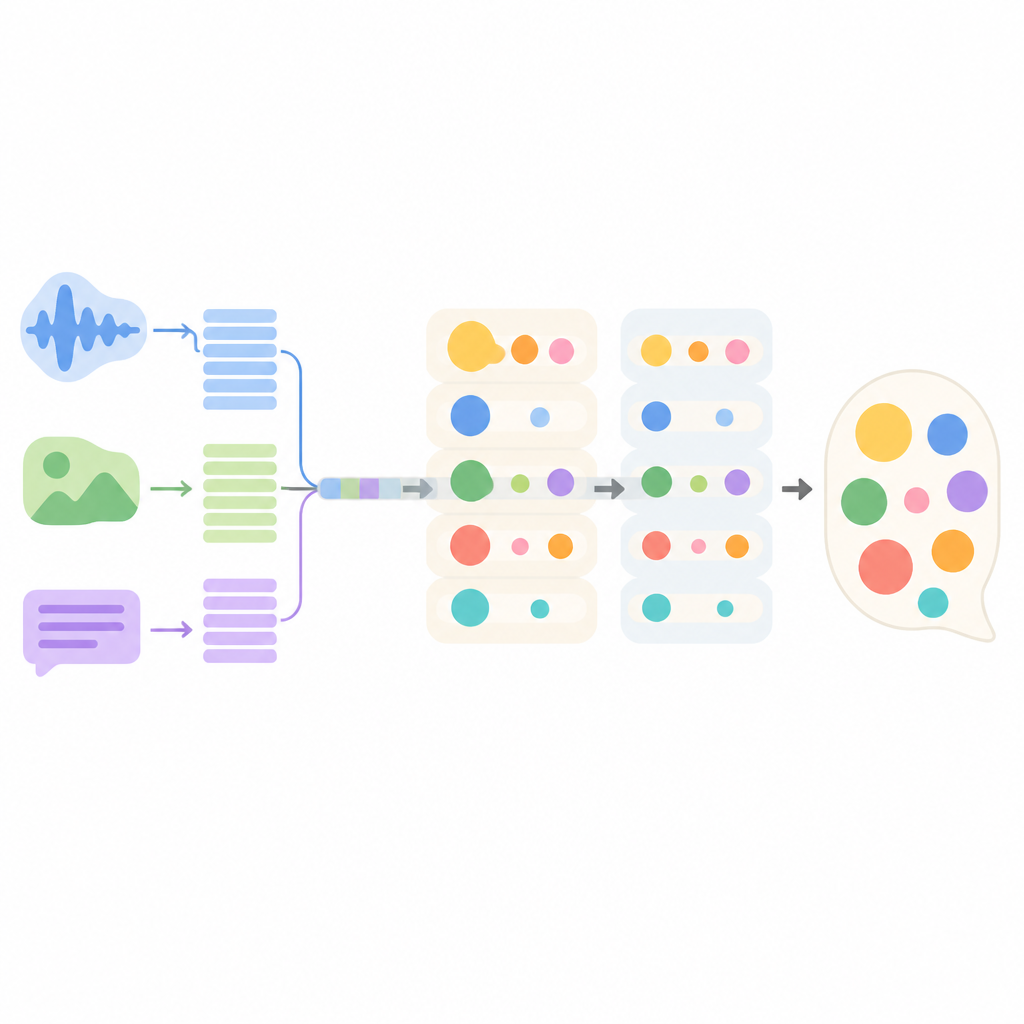
How the new conversation model works inside
The proposed system, called MMEI-DD, is built from several deep-learning components that each focus on a different signal. One part reads the text of the dialogue, another processes the video frames, and a third listens to the sound. A special module then learns how these streams relate to one another, for example by linking a sharp tone and a frown to a seemingly neutral sentence. This combined representation lets the model better estimate which emotions are present and how strong they are before it chooses a reply.
Blending several emotions at the right strength
Instead of deciding on one mood and generating a response in a single sweep, the model uses a two-stage decoding process. In the first stage it produces a draft response guided by one emotion and its chosen intensity, such as strong anger. In the second stage it refines that draft by adding a second emotion and its strength, such as mild surprise or low disgust. By separating these steps, the system avoids letting one feeling completely override the others, and keeps the balance between them closer to what appears in the original conversation.
Do richer emotional cues lead to better replies
To test their approach, the authors compare MMEI-DD with several earlier systems on both automatic scores and human judgments. They measure how fluent and relevant the responses are, how well they match the intended emotions, and how closely the strength of each emotion lines up with the target. Across these tests, the new model produces more coherent, emotionally detailed replies than methods that rely only on text or that ignore intensity. Human evaluators also rate its answers as more natural and emotionally appropriate.
What this means for everyday AI helpers
For non-specialists, the key message is that future chatbots and voice assistants may be able to respond not just to what we say, but to the subtle mix of feelings behind our words. By drawing on sound, facial expression, and language together, and by carefully controlling several emotions and their intensities, systems like MMEI-DD move closer to conversations that feel understood rather than simply answered.
Citation: Singh, A., Shree, R., Pandey, D. et al. Multi-emotion and intensity-driven response generation for richer multimodal dialogue. Sci Rep 16, 15696 (2026). https://doi.org/10.1038/s41598-026-41034-z
Keywords: emotional chatbots, multimodal dialogue, sentiment analysis, emotion intensity, conversational AI