Clear Sky Science · de
Multi-Emotion- und Intensitätsgesteuerte Antwortgenerierung für reichere multimodale Dialoge
Warum klügere Chatbots sich mehr wie wir anfühlen müssen
Die meisten von uns sprechen heute mit digitalen Helfern auf Telefonen, Computern oder Smart Speakern. Diese Systeme sind gut darin, Fragen zu beantworten, aber sie erfassen oft nicht den emotionalen Ton hinter unseren Worten. Dieses Paper untersucht, wie man KI entwickelt, die nicht nur eine einzelne Stimmung erkennt, sondern mehrere Gefühle gleichzeitig mischen und die jeweilige Stärke jedes Gefühls abbilden kann – unter Nutzung von Sprache, Gesichtsausdruck und Text zusammen.
Von einfachen Stimmungen zu geschichteten Gefühlen
Alltägliche Gespräche sind selten reine Freude oder reine Wut. Ein einzelner Satz kann sowohl Überraschung als auch Glück transportieren, oder Wut mit Ekel vermischen, und jedes Gefühl kann schwach oder stark ausgeprägt sein. Frühere Dialogsysteme versuchten meist, jede Äußerung einer Hauptemotion zuzuordnen. Selbst wenn sie mehrere Emotionen zuließen, behandelten sie diese oft als gleich stark. Infolgedessen klangen ihre Antworten entweder flach oder übertrieben und gaben nicht wieder, welches Gefühl die Antwort dominieren sollte.
Mit Augen, Ohren und Worten zuhören
Um dieses Problem anzugehen, bauen die Autor:innen auf einer großen Sammlung von Szenen aus acht beliebten englischsprachigen Fernsehserien auf, die Drama und Komödie abdecken. Der ursprüngliche Datensatz, MEIMD genannt, markierte jede Dialogzeile mit mehreren Emotionen und einem Intensitätsscore pro Emotion, speicherte jedoch nur den Skripttext. Die Forschenden bereichern dies, indem sie die entsprechenden Audio- und Videoclips hinzufügen und so eine neue multimodale Ressource namens MEIMD++ schaffen. Nun enthält jeder Satz die Stimme und Mimik der Schauspieler*innen sowie die Worte und bietet damit ein vollständigeres Bild davon, wie Emotionen tatsächlich ausgedrückt werden.
Wie das neue Konversationsmodell innen funktioniert
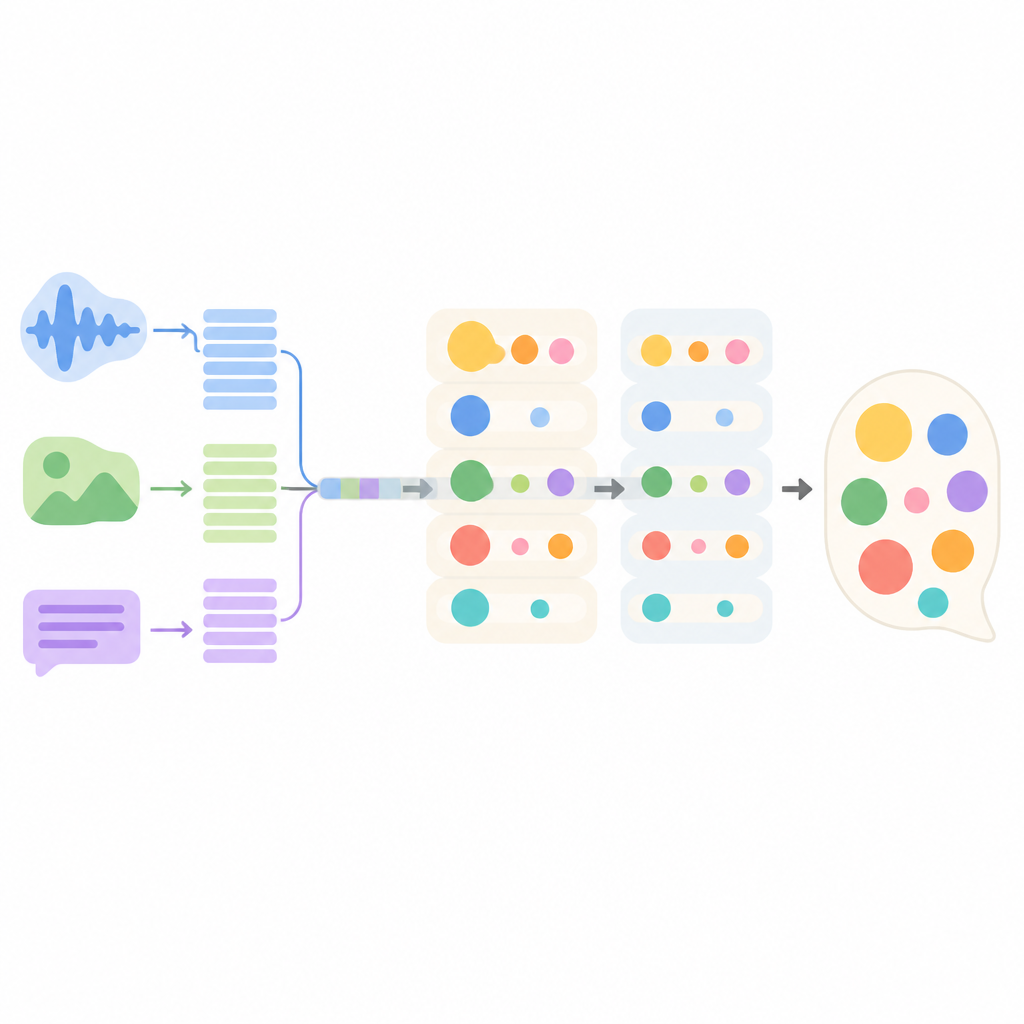
Das vorgeschlagene System, MMEI-DD genannt, besteht aus mehreren Deep-Learning-Komponenten, die sich jeweils auf ein anderes Signal konzentrieren. Ein Teil liest den Dialogtext, ein anderer verarbeitet Videoframes und ein dritter hört den Ton. Ein spezielles Modul lernt dann, wie diese Ströme zusammenhängen, etwa indem es einen scharfen Ton und eine Stirnrunzeln mit einem scheinbar neutralen Satz verknüpft. Diese kombinierte Repräsentation ermöglicht es dem Modell, besser abzuschätzen, welche Emotionen vorhanden sind und wie stark sie sind, bevor es eine Antwort auswählt.
Mehrere Emotionen mit der richtigen Stärke mischen
Anstatt sich für eine Stimmung zu entscheiden und eine Antwort in einem Schritt zu generieren, verwendet das Modell einen zweistufigen Dekodierungsprozess. In der ersten Phase erzeugt es einen Entwurf, gesteuert von einer Emotion und ihrer gewählten Intensität, etwa starker Wut. In der zweiten Phase verfeinert es diesen Entwurf, indem es eine zweite Emotion und deren Stärke hinzufügt, etwa milde Überraschung oder niedrigen Ekel. Durch die Trennung dieser Schritte vermeidet das System, dass ein Gefühl die anderen vollständig überdeckt, und bewahrt das Gleichgewicht zwischen den Gefühlen näher an dem, was im ursprünglichen Gespräch erscheint.
Führen reichere emotionale Hinweise zu besseren Antworten?
Um ihren Ansatz zu testen, vergleichen die Autor:innen MMEI-DD mit mehreren früheren Systemen anhand automatischer Metriken und menschlicher Beurteilungen. Sie messen, wie flüssig und relevant die Antworten sind, wie gut sie die beabsichtigten Emotionen treffen und wie eng die Stärke jeder Emotion mit dem Ziel übereinstimmt. Über diese Tests hinweg erzeugt das neue Modell kohärentere, emotional detailreichere Antworten als Methoden, die nur auf Text bauen oder die Intensität ignorieren. Auch menschliche Bewerter:innen bewerten seine Antworten als natürlicher und emotional angemessener.
Was das für alltägliche KI-Helfer bedeutet
Für Nicht-Spezialist:innen ist die Kernbotschaft, dass zukünftige Chatbots und Sprachassistenten möglicherweise nicht nur auf das reagieren, was wir sagen, sondern auf die feine Mischung von Gefühlen hinter unseren Worten. Indem sie Ton, Gesichtsausdruck und Sprache zusammenführen und mehrere Emotionen sowie deren Intensitäten gezielt steuern, kommen Systeme wie MMEI-DD Gesprächen näher, die sich verstanden anfühlen statt nur beantwortet.
Zitation: Singh, A., Shree, R., Pandey, D. et al. Multi-emotion and intensity-driven response generation for richer multimodal dialogue. Sci Rep 16, 15696 (2026). https://doi.org/10.1038/s41598-026-41034-z
Schlüsselwörter: emotionale Chatbots, multimodaler Dialog, Sentimentanalyse, Emotionsintensität, konversationelle KI