Clear Sky Science · ar
توليد استجابات متعددة العواطف ومدفوعة بالشدة لحوارات متعددة الوسائط أكثر ثراءً
لماذا تحتاج البوتات الأذكى لأن تشعر أكثر مثلنا
يتحدث معظمنا الآن إلى مساعدين رقميين على هواتفنا أو حواسبنا أو مكبرات الصوت الذكية. هذه الأنظمة جيدة في الإجابة عن الأسئلة، لكنها غالباً ما تُفوّت النبرة العاطفية الكامنة وراء كلماتنا. تستكشف هذه الورقة كيف نبني ذكاءً اصطناعياً لا يكتفي بالتعرّف على مزاج واحد، بل يستطيع مزج عدة مشاعر في آن واحد ومطابقة قوة كل منها، باستخدام صوتنا وتعابير الوجه والنص معاً.
من الحالات المزاجية البسيطة إلى المشاعر متعددة الطبقات
نادراً ما تكون المحادثات اليومية فرحاً محضاً أو غضباً محضاً. قد تحمل جملة واحدة دهشة وسعادة معاً، أو غضباً ممزوجاً اشمئزازاً، وقد تكون كل عاطفة ضعيفة أو قوية. كانت أنظمة الحوار السابقة عادةً تحاول ربط كل رسالة بعاطفة رئيسية واحدة. وحتى عندما قبلت بوجود عدة عواطف، كانت غالباً تعاملها على أنها متكافئة الشدة. ونتيجة لذلك، بدت ردودها إما مسطحة أو مبالغاً فيها، ولم تحافظ على تحديد أي عاطفة يجب أن تسود الاستجابة.
الاستماع بالعيون والأذنين والكلمات
لمعالجة ذلك، يبني المؤلفون على مجموعة كبيرة من المشاهد من ثمانية مسلسلات تلفزيونية إنجليزية شهيرة، تشمل الدراما والكوميديا. مجموعة البيانات الأصلية، المسماة MEIMD، صنفت كل سطر من الحوار بعدة عواطف ودرجة شدة لكل منها، لكنها احتفظت بنص السيناريو فقط. يثري الباحثون هذا بإضافة المقاطع الصوتية والفيديو المقابلة، فخلقوا موردًا متعدد الوسائط جديدًا باسم MEIMD++. الآن تأتي كل جملة بصوت الممثل وتعابير وجهه فضلاً عن الكلمات، مما يوفر رؤية أكمل عن كيفية التعبير عن العواطف فعلياً.
كيف يعمل نموذج المحادثة الجديد داخلياً
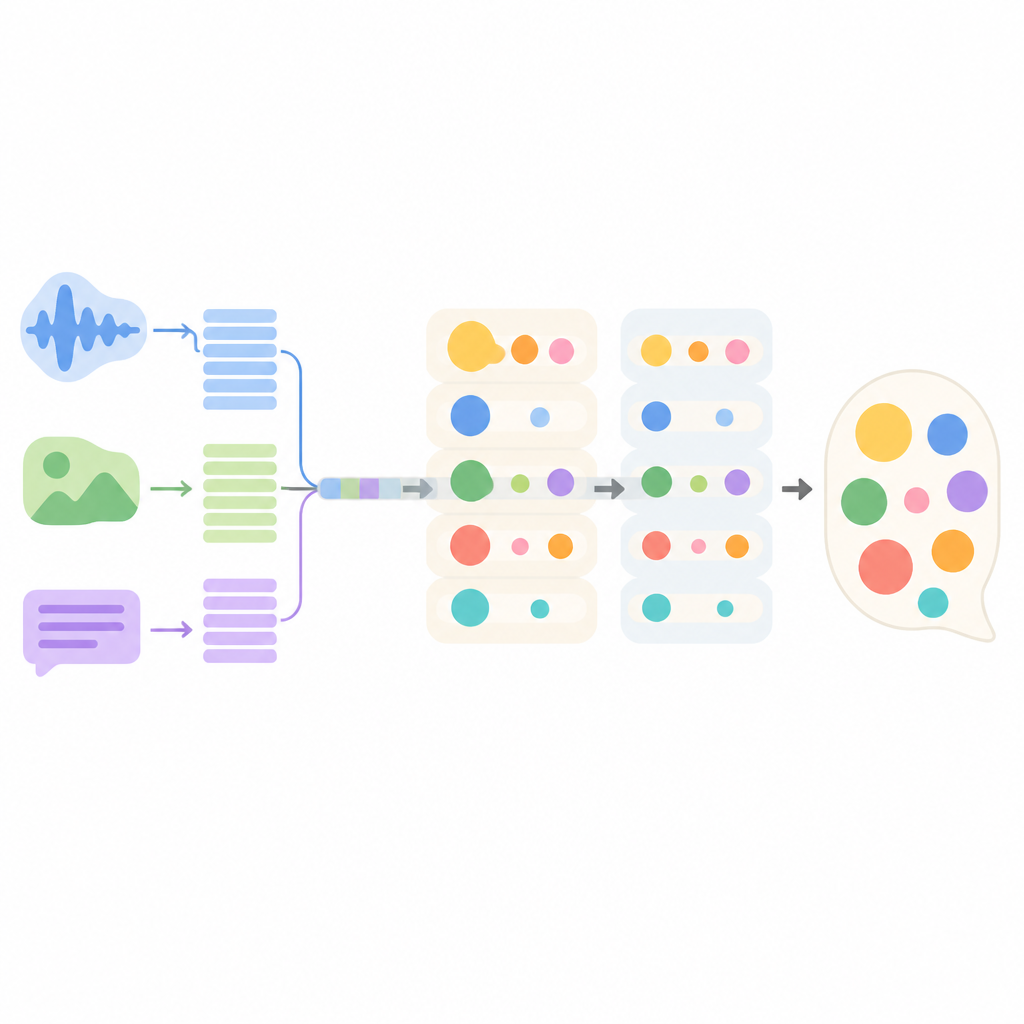
النظام المقترح، المسمى MMEI-DD، مبني من عدة مكونات تعلم عميق يركز كل منها على إشارة مختلفة. جزء يقرأ نص الحوار، وآخر يعالج إطارات الفيديو، وثالث يستمع إلى الصوت. ثم يتعلم مُكوّن خاص كيف ترتبط هذه التيارات ببعضها، مثلاً بربط نبرة حادة وعبوس بجملة تبدو محايدة. تمكّن هذه التمثيلات المجمعة النموذج من تقدير العواطف الموجودة وشدتها بشكل أفضل قبل أن يختار الرد.
مزاوجة عدة عواطف بالشدة المناسبة
بدلاً من اتخاذ مزاج واحد وتوليد رد في خطوة واحدة، يستخدم النموذج عملية فك ترميز من مرحلتين. في المرحلة الأولى ينتج مسودة رد موجهة بعاطفة واحدة وشدتها المختارة، مثل غضب قوي. في المرحلة الثانية ينقّح تلك المسودة بإضافة عاطفة ثانية وشدتها، مثل دهشة خفيفة أو اشمئزاز منخفض. من خلال فصل هاتين الخطوتين، يتجنب النظام أن تطغى عاطفة واحدة تماماً على البقية، ويحافظ على توازن بينها أقرب لما يظهر في المحادثة الأصلية.
هل تؤدي الدلائل العاطفية الأكثر ثراءً إلى ردود أفضل
لاختبار نهجهم، يقارن المؤلفون MMEI-DD بعدة أنظمة سابقة على مقاييس آلية وتقييمات بشرية. يقيسون مدى طلاقة وصِلة الردود، ومدى تطابقها مع العواطف المقصودة، ومدى قرب شدة كل عاطفة من الهدف. عبر هذه الاختبارات، ينتج النموذج الجديد ردوداً أكثر اتساقاً وتفصيلاً عاطفياً من الطرق التي تعتمد على النص فقط أو التي تتجاهل الشدة. كما يصنف المقيمون البشر إجاباته على أنها أكثر طبيعية وملاءمة عاطفياً.
ماذا يعني هذا للمساعدين الذكيين اليوميين
بالنسبة لغير المتخصصين، الرسالة الرئيسية هي أن البوتات والمساعدات الصوتية المستقبلية قد تتمكن من الاستجابة ليس فقط لما نقول، بل للمزيج الدقيق من المشاعر وراء كلماتنا. من خلال الاستفادة من الصوت وتعابير الوجه واللغة معاً، وبالتحكم الدقيق في عدة عواطف وشداتها، تقترب أنظمة مثل MMEI-DD من محادثات تبدو مفهومة بدلاً من كونها مجرد إجابات.
الاستشهاد: Singh, A., Shree, R., Pandey, D. et al. Multi-emotion and intensity-driven response generation for richer multimodal dialogue. Sci Rep 16, 15696 (2026). https://doi.org/10.1038/s41598-026-41034-z
الكلمات المفتاحية: الدردشة العاطفية, الحوار متعدد الوسائط, تحليل الشعور, شدة العاطفة, الذكاء المحادثي