Clear Sky Science · sv
Multikänslomässig och intensitetsstyrd responsgenerering för rikare multimodala dialoger
Varför smartare chattrobotar behöver kännas mer som oss
De flesta av oss pratar numera med digitala assistenter på telefoner, datorer eller smarta högtalare. Dessa system är bra på att svara på frågor, men missar ofta den emotionella tonen bakom våra ord. Denna artikel undersöker hur man bygger AI som inte bara känner igen ett enda sinnestillstånd, utan kan blanda flera känslor samtidigt och matcha hur stark varje känsla är, genom att använda tal, ansiktsuttryck och text tillsammans.
Från enkla sinnesstämningar till lager av känslor
Vardagskonversationer är sällan ren glädje eller ren ilska. En enda mening kan bära både överraskning och lycka, eller ilska blandat med avsmak, och varje känsla kan vara svag eller stark. Tidigare dialogsystem försökte vanligtvis fästa varje meddelande vid en huvudkänsla. Även när de accepterade att flera känslor kunde finnas, behandlade de dem ofta som lika starka. Som ett resultat lät deras svar antingen platta eller överdrivna och bevarade inte vilken känsla som borde dominera svaret.
Lyssna med ögon, öron och ord
För att ta itu med detta bygger författarna vidare på en stor samling scener från åtta populära engelskspråkiga TV-serier, med både drama och komedi. Den ursprungliga datamängden, kallad MEIMD, märkte varje replik med flera känslor och en intensitetspoäng för varje, men innehöll endast manusets text. Forskarna berikar detta genom att lägga till motsvarande ljud- och videoklipp och skapar en ny multimodal resurs som heter MEIMD++. Nu kommer varje mening med skådespelarens röst och ansiktsuttryck såväl som orden, vilket ger en fylligare bild av hur känslor faktiskt uttrycks.
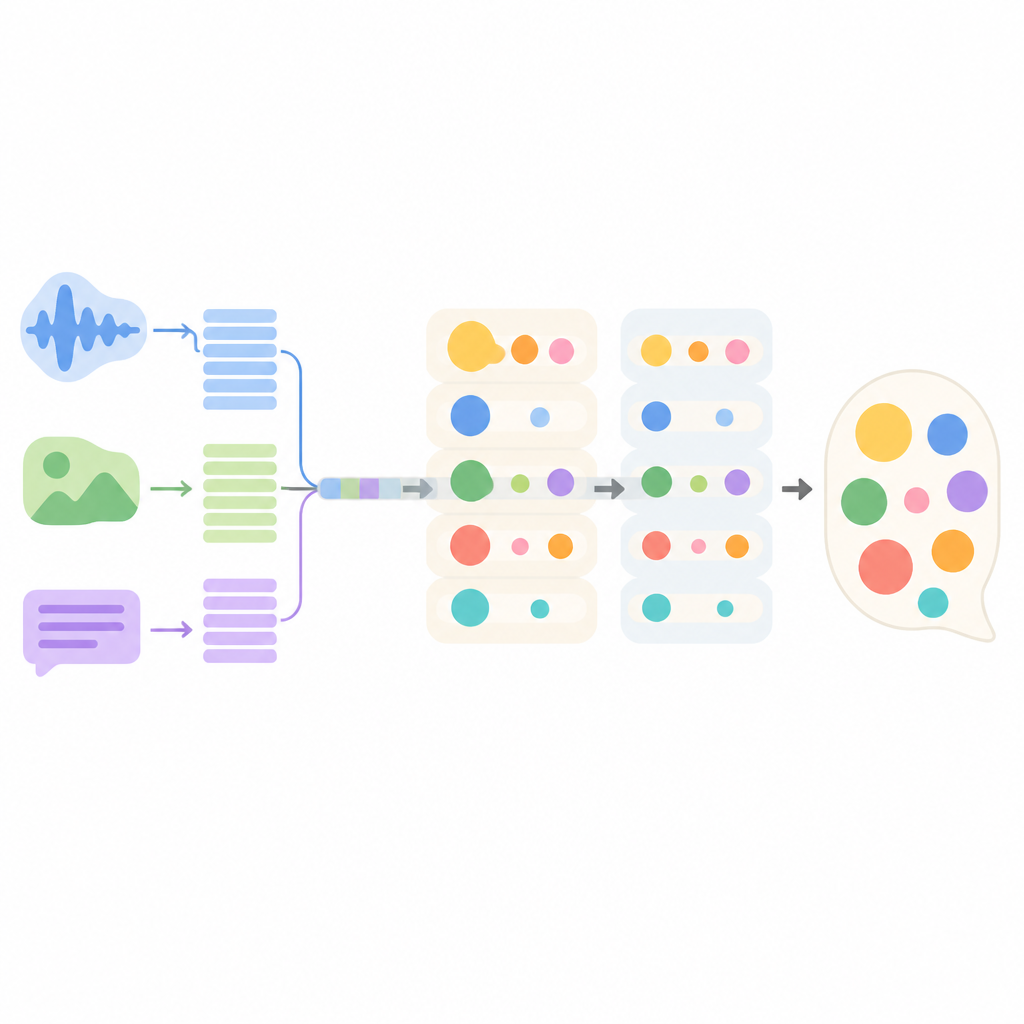
Hur den nya konversationsmodellen fungerar på insidan
Det föreslagna systemet, kallat MMEI-DD, byggs av flera djupinlärningskomponenter som var och en fokuserar på en annan signal. En del läser dialogens text, en annan behandlar videobilder och en tredje lyssnar på ljudet. En särskild modul lär sig sedan hur dessa strömmar relaterar till varandra, till exempel genom att koppla en hård ton och en rynkad panna till en till synes neutral mening. Denna kombinerade representation gör att modellen bättre kan uppskatta vilka känslor som är närvarande och hur starka de är innan den väljer ett svar.
Blanda flera känslor med rätt styrka
I stället för att bestämma en stämning och generera ett svar i ett enda svep använder modellen en tvåstegsdekodering. I första steget producerar den ett utkast till svar styrt av en känsla och dess valda intensitet, till exempel stark ilska. I andra steget förfinar den utkastet genom att lägga till en andra känsla och dess styrka, till exempel mild överraskning eller låg avsmak. Genom att separera dessa steg undviker systemet att en känsla fullständigt överskuggar de andra och behåller balansen mellan dem närmare det som framträder i den ursprungliga konversationen.
Ger rikare känslomässiga ledtrådar bättre svar?
För att testa sin metod jämför författarna MMEI-DD med flera tidigare system både med automatiska mått och mänskliga bedömningar. De mäter hur flytande och relevanta svaren är, hur väl de matchar avsedda känslor och hur väl styrkan för varje känsla överensstämmer med målet. Över dessa tester producerar den nya modellen mer sammanhängande, känslomässigt detaljerade svar än metoder som förlitar sig enbart på text eller som ignorerar intensitet. Mänskliga utvärderare bedömer också dess svar som mer naturliga och emotionellt passande.
Vad detta betyder för vardagliga AI-assistenter
För icke-specialister är huvudbudskapet att framtida chattrobotar och röstassistenter kan komma att svara inte bara på vad vi säger utan på den subtila blandning av känslor som ligger bakom våra ord. Genom att dra nytta av ljud, ansiktsuttryck och språk tillsammans, och genom att noggrant kontrollera flera känslor och deras intensiteter, rör sig system som MMEI-DD närmare konversationer som känns förstådda snarare än blott besvarade.
Citering: Singh, A., Shree, R., Pandey, D. et al. Multi-emotion and intensity-driven response generation for richer multimodal dialogue. Sci Rep 16, 15696 (2026). https://doi.org/10.1038/s41598-026-41034-z
Nyckelord: emotionella chatbottar, multimodal dialog, sentimentanalys, känslointensitet, konversations-AI