Clear Sky Science · pt
Geração de respostas guiada por múltiplas emoções e intensidades para diálogos multimodais mais ricos
Por que chatbots mais inteligentes precisam parecer mais com a gente
A maioria de nós conversa hoje com assistentes digitais no celular, no computador ou em alto-falantes inteligentes. Esses sistemas são bons em responder perguntas, mas frequentemente deixam de captar o tom emocional por trás das nossas palavras. Este artigo explora como construir IA que não apenas reconheça um único estado de espírito, mas que consiga misturar vários sentimentos ao mesmo tempo e refletir a intensidade de cada um deles, usando fala, sinais faciais e texto em conjunto.
De humores simples a sentimentos em camadas
Conversas do dia a dia raramente são pura alegria ou pura raiva. Uma única frase pode carregar surpresa e felicidade ao mesmo tempo, ou raiva misturada com desgosto, e cada sentimento pode ser fraco ou forte. Sistemas de diálogo anteriores geralmente tentavam associar cada mensagem a uma emoção principal. Mesmo quando aceitavam que várias emoções pudessem estar presentes, muitas vezes tratavam todas com a mesma intensidade. Como resultado, suas respostas soavam ou planas ou exageradas, e não preservavam qual emoção deveria dominar a resposta.
Ouvindo com olhos, ouvidos e palavras
Para enfrentar isso, os autores partiram de uma grande coleção de cenas de oito séries de televisão em inglês populares, abrangendo drama e comédia. O conjunto de dados original, chamado MEIMD, rotulava cada fala com várias emoções e uma pontuação de intensidade para cada uma, mas armazenava apenas o texto do roteiro. Os pesquisadores enriqueceram esse material adicionando os clipes de áudio e vídeo correspondentes, criando um novo recurso multimodal chamado MEIMD++. Agora cada sentença vem com a voz do ator e suas expressões faciais, além das palavras, oferecendo uma visão mais completa de como as emoções são realmente expressas.
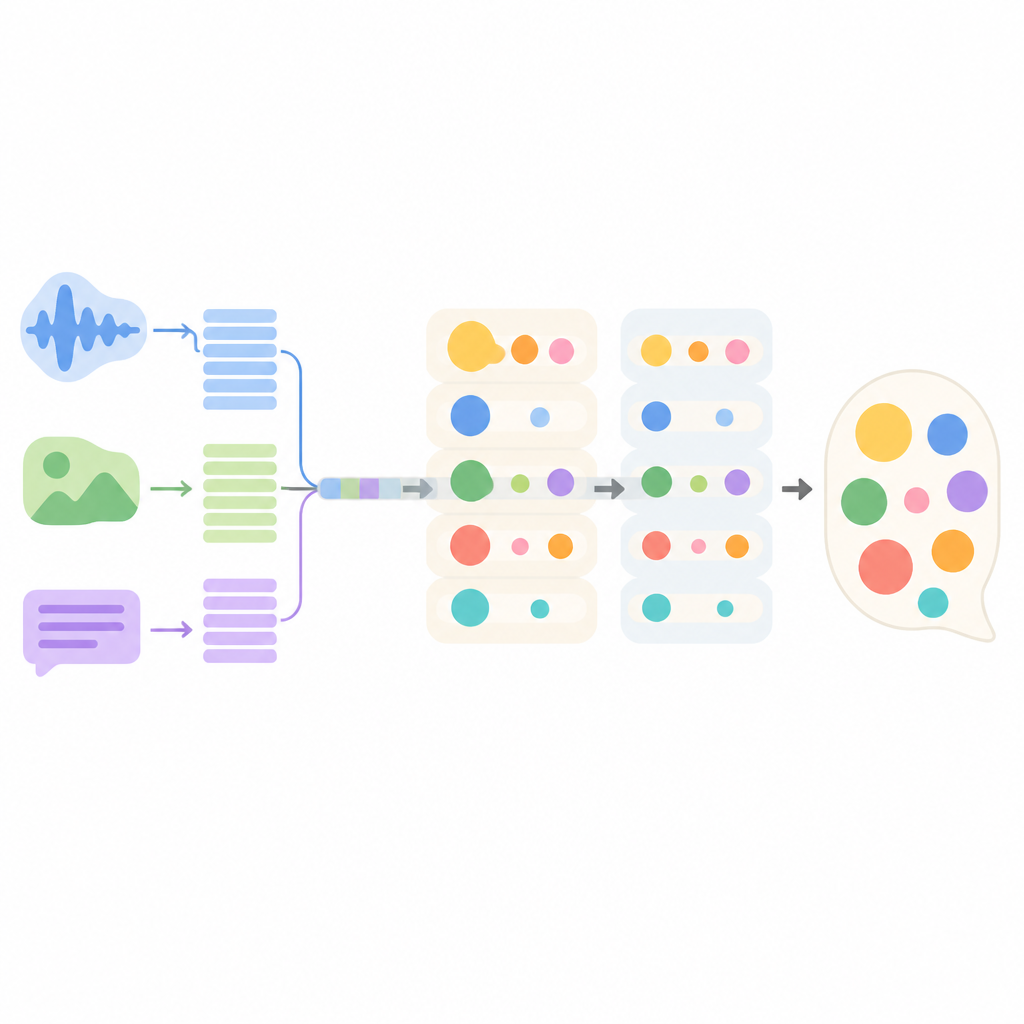
Como o novo modelo de conversação funciona por dentro
O sistema proposto, chamado MMEI-DD, é construído a partir de vários componentes de aprendizado profundo que se concentram em sinais diferentes. Uma parte lê o texto do diálogo, outra processa os quadros de vídeo, e uma terceira escuta o áudio. Um módulo especial então aprende como essas correntes se relacionam entre si, por exemplo, ao vincular um tom cortante e um franzir de sobrancelhas a uma frase aparentemente neutra. Essa representação combinada permite ao modelo estimar melhor quais emoções estão presentes e qual a intensidade de cada uma antes de escolher uma resposta.
Mesclando várias emoções na força certa
Em vez de decidir um único humor e gerar uma resposta de uma só vez, o modelo usa um processo de decodificação em duas etapas. Na primeira etapa ele produz um rascunho de resposta guiado por uma emoção e sua intensidade escolhida, como raiva forte. Na segunda etapa ele refina esse rascunho adicionando uma segunda emoção e sua intensidade, como surpresa leve ou desgosto baixo. Ao separar esses passos, o sistema evita que um sentimento sobreponha completamente os outros e mantém o equilíbrio entre eles mais próximo do que aparece na conversa original.
Sinais emocionais mais ricos levam a respostas melhores?
Para testar sua abordagem, os autores comparam o MMEI-DD com vários sistemas anteriores tanto em métricas automáticas quanto em julgamentos humanos. Eles medem quão fluentes e relevantes são as respostas, quão bem elas correspondem às emoções pretendidas e quão alinhada está a intensidade de cada emoção com o alvo. Nesses testes, o novo modelo produz respostas mais coerentes e emocionalmente detalhadas do que métodos que dependem apenas do texto ou que ignoram a intensidade. Avaliadores humanos também classificam suas respostas como mais naturais e emocionalmente apropriadas.
O que isso significa para assistentes de IA do dia a dia
Para não especialistas, a mensagem principal é que chatbots e assistentes de voz futuros podem ser capazes de responder não apenas ao que dizemos, mas à mistura sutil de sentimentos por trás de nossas palavras. Ao combinar som, expressão facial e linguagem, e ao controlar cuidadosamente várias emoções e suas intensidades, sistemas como o MMEI-DD se aproximam de conversas que transmitem compreensão em vez de apenas respostas.
Citação: Singh, A., Shree, R., Pandey, D. et al. Multi-emotion and intensity-driven response generation for richer multimodal dialogue. Sci Rep 16, 15696 (2026). https://doi.org/10.1038/s41598-026-41034-z
Palavras-chave: chatbots emocionais, diálogo multimodal, análise de sentimento, intensidade emocional, IA conversacional