Clear Sky Science · zh
DeepStackVEGF:用于血管内皮生长因子预测的堆叠集成深度学习框架
为何预测一种愈合信号很重要
我们的身体依赖一种名为血管内皮生长因子(VEGF)的蛋白来生成新血管。该信号对创伤愈合、骨修复和正常发育至关重要——但癌症也会劫持它来养活肿瘤并实现转移。在实验室中测量和表征 VEGF 既缓慢又昂贵。本研究提出了 DeepStack-VEGF,这是一种强大的计算模型,能够快速预测给定蛋白是否表现出类似 VEGF 的功能,可能加速药物发现和精准医疗进程。
从实验台到笔记本电脑
传统上,研究人员使用结晶学、核磁共振(NMR)和组织染色等复杂技术来研究 VEGF。这些方法可以揭示分子的结构和定位,但需要专门设备和较长时间。与此同时,公共数据库中存在数以百万计的蛋白序列,其功能仅部分被注释。作者们看到了一个机会:与其先做晶体生长或运行复杂实验,不如让计算机筛选蛋白序列,标记那些可能像 VEGF 的候选。DeepStack-VEGF 被设计为一个快速、可扩展的工具——将原始的蛋白字母串转化为有意义的预测。
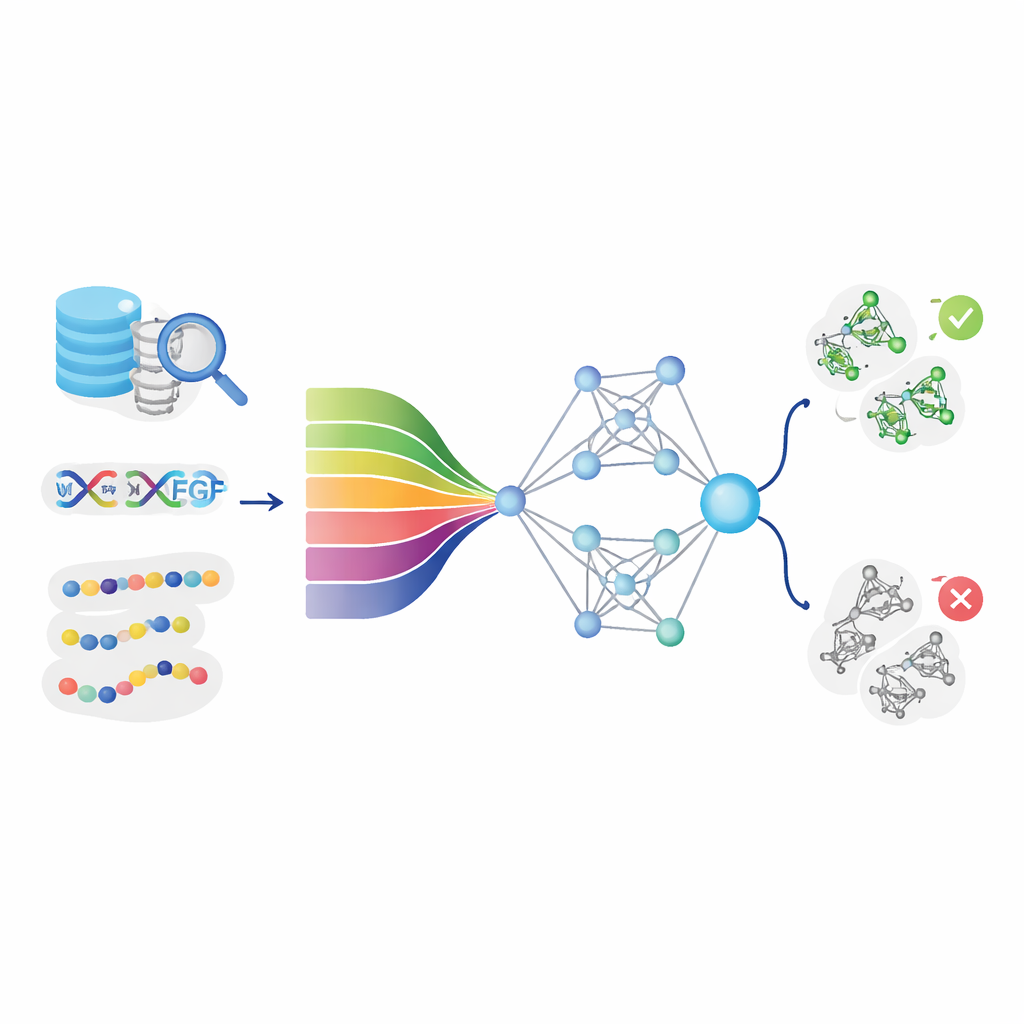
教计算机“阅读”蛋白质的“语言”
DeepStack-VEGF 的核心思想是蛋白质序列中蕴含着提示其功能的隐含模式。团队从主要数据库收集了成千上万的 VEGF 与非-VEGF 蛋白,并通过精心清洗数据以避免高度重复。随后他们从多角度描述每个蛋白。有些特征捕捉了基础化学属性,例如不同位置的疏水性或电荷分布;有些则总结了某些二联体或三联体出现的频率,或链条形成螺旋与片层的可能性。关键的是,模型还使用了现代“蛋白质语言模型”——类似于文本语言模型的人工智能系统,从数百万自然蛋白序列中学习深层模式,并将每个序列转换为丰富的数值指纹。
将多种视角统一为一个决定
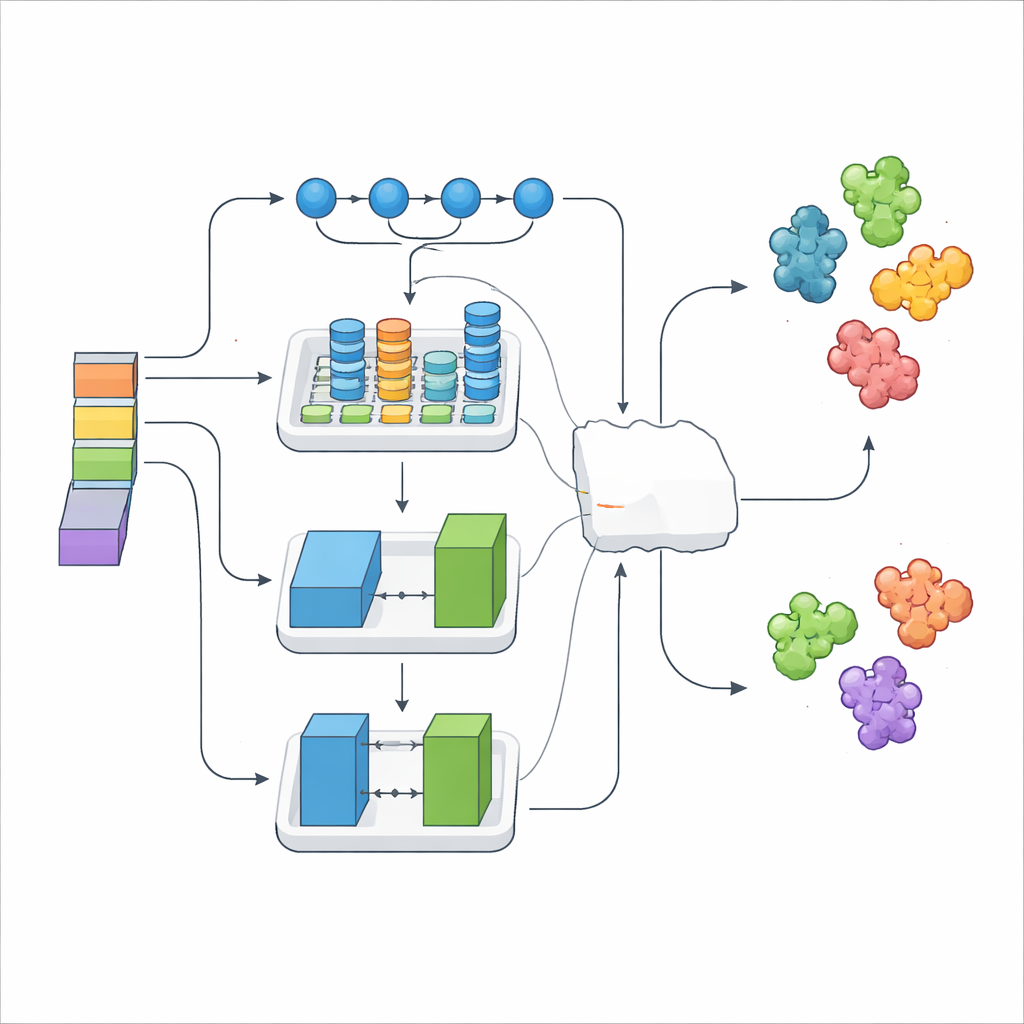
简单堆叠成千上万的数值特征可能会引入噪声,因此研究者使用了一种选择方法,只保留最具信息量的信号。这些精简后的特征随后被输入到三个不同的深度学习模块中,每个模块有不同的专长。一个模型擅长跟踪序列上的长程模式,另一个捕捉局部结构基元及其关系,第三个采用类似生成—判别的对抗设置来丰富并正则化数据。在这些之上,一个“元”层学习如何最好地组合它们的输出,形成 DeepStack-VEGF 集成。该分层策略类似于一组训练背景不同的专家在达成共同结论前各自权衡意见的方式。
检验准确性并打开黑箱
为测试系统,作者使用了严格的交叉验证和独立测试集。在多项准确性指标上,DeepStack-VEGF 的表现优于其各个组成模型以及两种先前的最先进 VEGF 预测器。最终版本在识别类似 VEGF 的蛋白时正确率远超九成,且误报率低于竞争方法。团队还应用了一种解释方法,评估每个输入特征在多大程度上将决策推向“VEGF”或“非 VEGF”。该分析显示,学习到的蛋白语言指纹贡献了大部分预测能力,而传统的化学和结构特征则提供了细粒度的细节和稳定性。
这对医学与研究意味着什么
对非专业人士而言,DeepStack-VEGF 可被视为针对体内关键愈合信号的高度训练的模式识别器。研究人员无需等待繁琐的实验,就能将蛋白序列输入模型,快速估算其是否表现出 VEGF 特性。这一能力有助于缩小新抗癌或眼病治疗候选者的范围,指导抗血管生成药物的设计,并支持更广泛的蛋白质研究。尽管任何有前景的预测仍需实验室确认,像 DeepStack-VEGF 这样的工具将部分发现工作从实验台转移到计算机上,可能使未来疗法的开发更快且成本更低。
引用: Ali, F., Khalid, M., Algarni, A. et al. DeepStackVEGF a stacking ensemble deep learning framework for vascular endothelial growth factor prediction. Sci Rep 16, 13035 (2026). https://doi.org/10.1038/s41598-026-40134-0
关键词: VEGF 预测, 血管生成, 生物学中的深度学习, 蛋白质语言模型, 药物发现