Clear Sky Science · fr
DeepStackVEGF un cadre d’apprentissage profond en empilement pour la prédiction du facteur de croissance endothélial vasculaire
Pourquoi prédire un signal de cicatrisation est important
Notre organisme dépend d’une protéine appelée facteur de croissance endothélial vasculaire, ou VEGF, pour former de nouveaux vaisseaux sanguins. Ce signal est essentiel pour la cicatrisation des blessures, la réparation osseuse et le développement normal — mais les cancers s’en emparent aussi pour alimenter les tumeurs et se disséminer dans le corps. Mesurer et caractériser le VEGF en laboratoire est lent et coûteux. Cette étude présente DeepStack-VEGF, un modèle informatique puissant capable de prédire rapidement si une protéine donnée se comporte comme le VEGF, ce qui pourrait accélérer la découverte de médicaments et la médecine de précision.
Du banc de laboratoire à l’ordinateur
Traditionnellement, les chercheurs utilisent des techniques sophistiquées comme la cristallographie, la RMN et les colorations tissulaires pour étudier le VEGF. Ces méthodes révèlent la structure et la localisation de la molécule, mais exigent des équipements spécialisés et du temps. Parallèlement, d’immenses bases de données publiques contiennent désormais des millions de séquences protéiques dont les fonctions ne sont que partiellement connues. Les auteurs ont vu une opportunité : plutôt que de commencer par faire pousser des cristaux ou réaliser des expériences complexes, pourquoi ne pas laisser les ordinateurs parcourir les séquences protéiques et signaler celles qui sont susceptibles d’agir comme le VEGF ? DeepStack-VEGF a été conçu comme un outil rapide et évolutif pour faire exactement cela — transformer des lettres protéiques brutes en prédictions significatives.
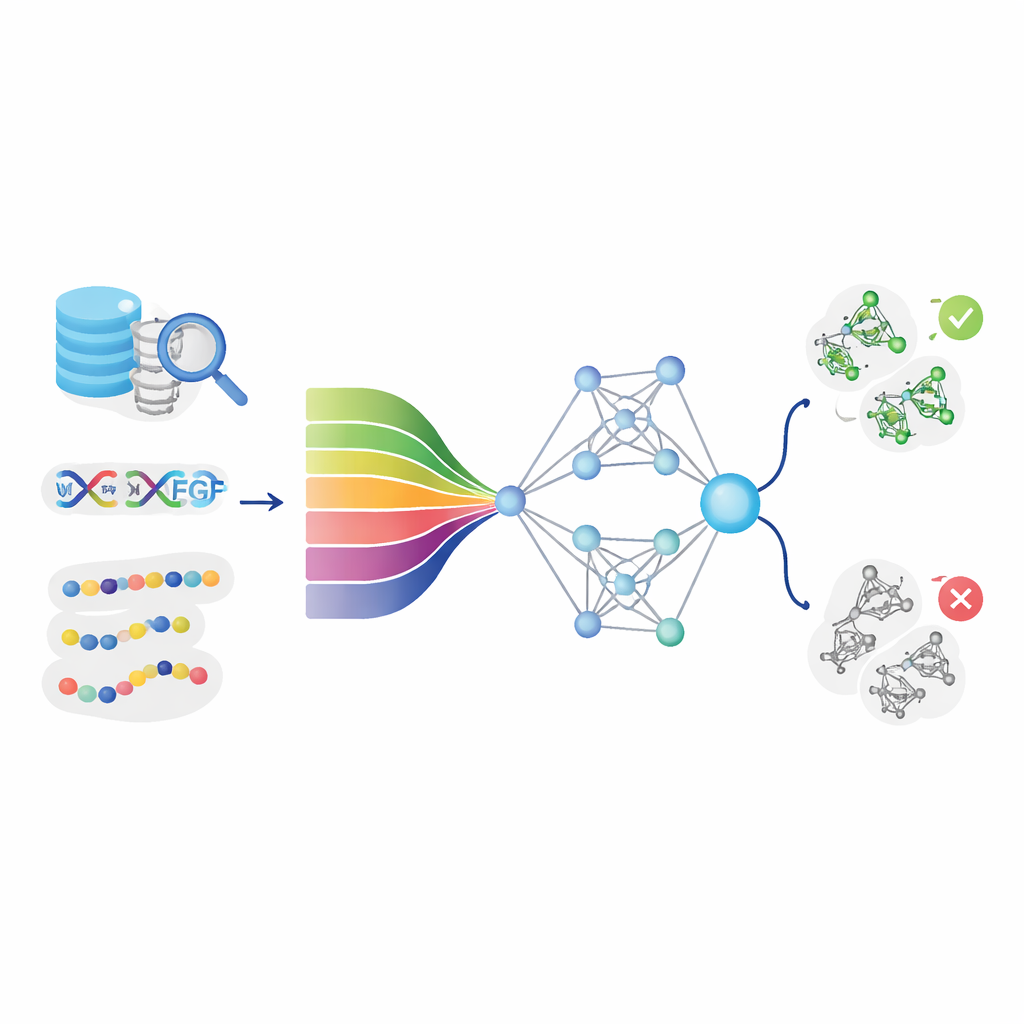
Apprendre aux ordinateurs à lire le « langage » des protéines
L’idée centrale de DeepStack-VEGF est que la séquence d’une protéine contient des motifs cachés qui suggèrent son comportement. L’équipe a rassemblé des milliers de protéines VEGF et non-VEGF à partir de grandes bases de données et a soigneusement nettoyé les données pour éviter les quasi‑doublons. Ils ont ensuite décrit chaque protéine sous de nombreux angles. Certaines caractéristiques capturaient la chimie de base, comme le degré d’hydrophobicité ou la charge à différentes positions. D’autres résumaient la fréquence d’apparition de certaines paires ou triplets d’acides aminés, ou la propension de la chaîne à se plier en hélices et feuillets. De façon cruciale, le modèle a aussi utilisé des « modèles linguistiques » pour protéines modernes — des systèmes d’intelligence artificielle qui, comme les outils de langage pour le texte, apprennent des motifs profonds à partir de millions de séquences protéiques naturelles et transforment chacune en une empreinte numérique riche.
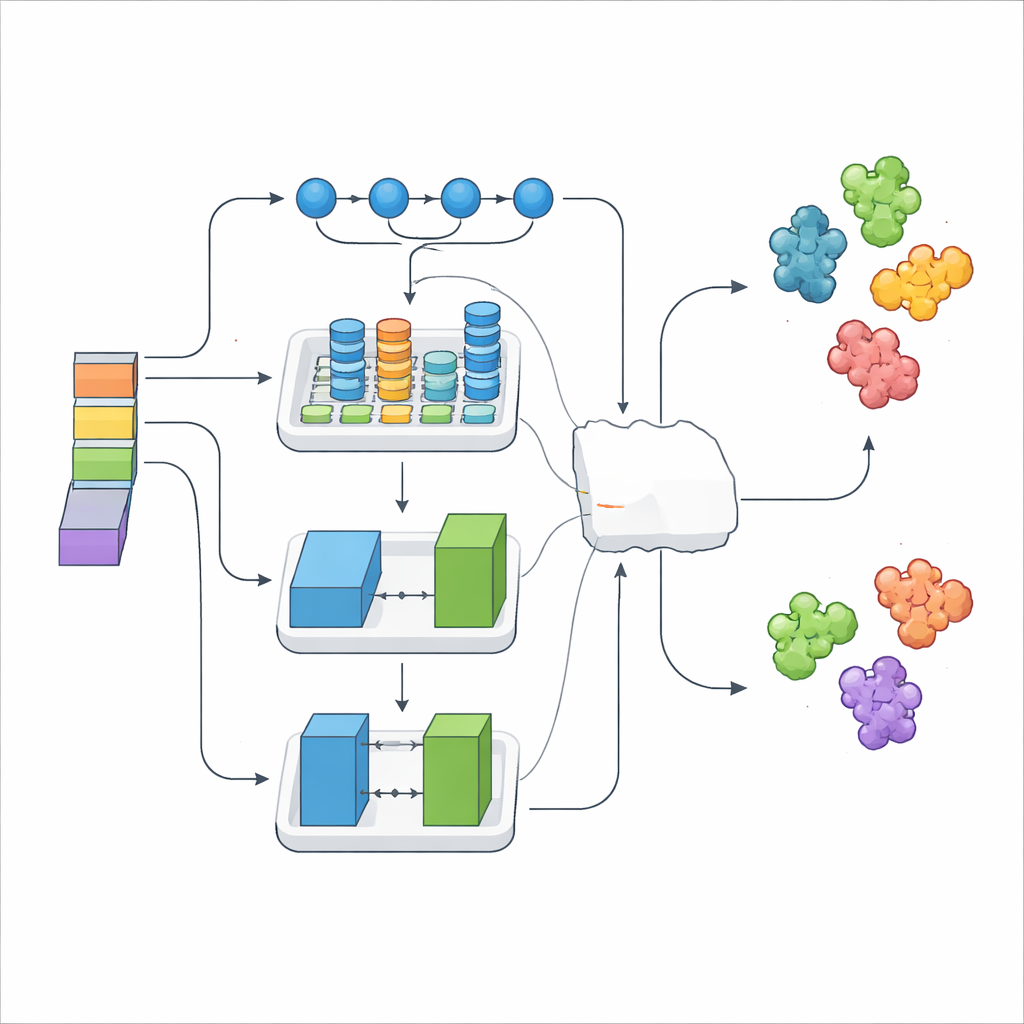
Unir plusieurs points de vue pour une seule décision
Empiler des milliers de caractéristiques numériques peut introduire du bruit, aussi les chercheurs ont-ils utilisé une méthode de sélection qui conserve uniquement les signaux les plus informatifs. Ces caractéristiques affinées ont ensuite été alimentées dans trois modules d’apprentissage profond différents, chacun avec une spécialité distincte. Un modèle excellait à repérer des motifs à longue portée le long de la séquence, un autre capturait des motifs structurels locaux et leurs relations, et un troisième utilisait une configuration générateur–critic de type jeu pour enrichir et régulariser les données. Par-dessus ces éléments, une couche « méta » a appris à combiner au mieux leurs sorties, formant l’ensemble DeepStack-VEGF. Cette stratégie en couches reflète la façon dont un panel d’experts, chacun formé différemment, pourrait délibérer avant d’aboutir à une conclusion commune.
Vérifier la précision et ouvrir la boîte noire
Pour tester leur système, les auteurs ont utilisé une validation croisée rigoureuse et un jeu de test indépendant. Sur plusieurs mesures de précision, DeepStack-VEGF a surpassé chacun de ses modèles composants et deux précédents prédicteurs VEGF de pointe. Sa version finale a correctement classé des protéines de type VEGF dans bien plus de neuf cas sur dix, avec moins de fausses alertes que les approches concurrentes. L’équipe a également appliqué une méthode d’explicabilité qui estime dans quelle mesure chaque caractéristique d’entrée pousse la décision vers « VEGF » ou « non‑VEGF ». Cette analyse a montré que les empreintes apprises par les modèles linguistiques de protéines fournissaient la majeure partie du pouvoir prédictif, tandis que les caractéristiques classiques basées sur la chimie et la structure apportaient des détails fins et de la stabilité.
Ce que cela implique pour la médecine et la recherche
Pour les non‑spécialistes, DeepStack-VEGF peut être vu comme un détecteur de motifs hautement entraîné pour un signal de guérison clé de l’organisme. Au lieu d’attendre des expériences laborieuses, les scientifiques peuvent désormais soumettre des séquences protéiques au modèle pour estimer rapidement si elles se comportent comme le VEGF. Cette capacité peut aider à restreindre les candidats pour de nouveaux traitements contre le cancer ou les maladies oculaires, orienter la conception de médicaments anti‑angiogéniques et soutenir la recherche protéique plus largement. Bien que toute prédiction prometteuse doive encore être confirmée en laboratoire, des outils comme DeepStack-VEGF déplacent une partie du travail de découverte du banc vers l’ordinateur, rendant potentiellement le développement des thérapies futures plus rapide et moins coûteux.
Citation: Ali, F., Khalid, M., Algarni, A. et al. DeepStackVEGF a stacking ensemble deep learning framework for vascular endothelial growth factor prediction. Sci Rep 16, 13035 (2026). https://doi.org/10.1038/s41598-026-40134-0
Mots-clés: prédiction VEGF, angiogenèse, apprentissage profond en biologie, modèles linguistiques de protéines, découverte de médicaments