Clear Sky Science · it
DeepStackVEGF: un framework di ensemble stacking in deep learning per la predizione del fattore di crescita endoteliale vascolare
Perché ha importanza prevedere un segnale di guarigione
I nostri corpi dipendono da una proteina chiamata fattore di crescita endoteliale vascolare, o VEGF, per la formazione di nuovi vasi sanguigni. Questo segnale è essenziale per la guarigione delle ferite, la riparazione delle ossa e il normale sviluppo — ma i tumori lo sfruttano per nutrirsi e diffondersi nell’organismo. Misurare e caratterizzare il VEGF in laboratorio è un processo lento e costoso. Questo studio introduce DeepStack-VEGF, un potente modello computazionale in grado di predire rapidamente se una data proteina si comporta come il VEGF, accelerando potenzialmente la scoperta di farmaci e la medicina di precisione.
Dal banco di laboratorio al computer
Tradizionalmente i ricercatori usano tecniche sofisticate come cristallografia, NMR e colorazioni tissutali per studiare il VEGF. Questi metodi rivelano la struttura e la posizione della molecola, ma richiedono attrezzature specializzate e tempo. Allo stesso tempo, enormi database pubblici contengono oggi milioni di sequenze proteiche le cui funzioni sono solo parzialmente note. Gli autori hanno visto un’opportunità: invece di coltivare cristalli o eseguire esperimenti complessi prima di tutto, perché non lasciare che i computer setaccino le sequenze proteiche e segnalino quelle più probabili ad agire come VEGF? DeepStack-VEGF è stato progettato come uno strumento veloce e scalabile proprio per questo — trasformare le lettere grezze delle proteine in predizioni significative.
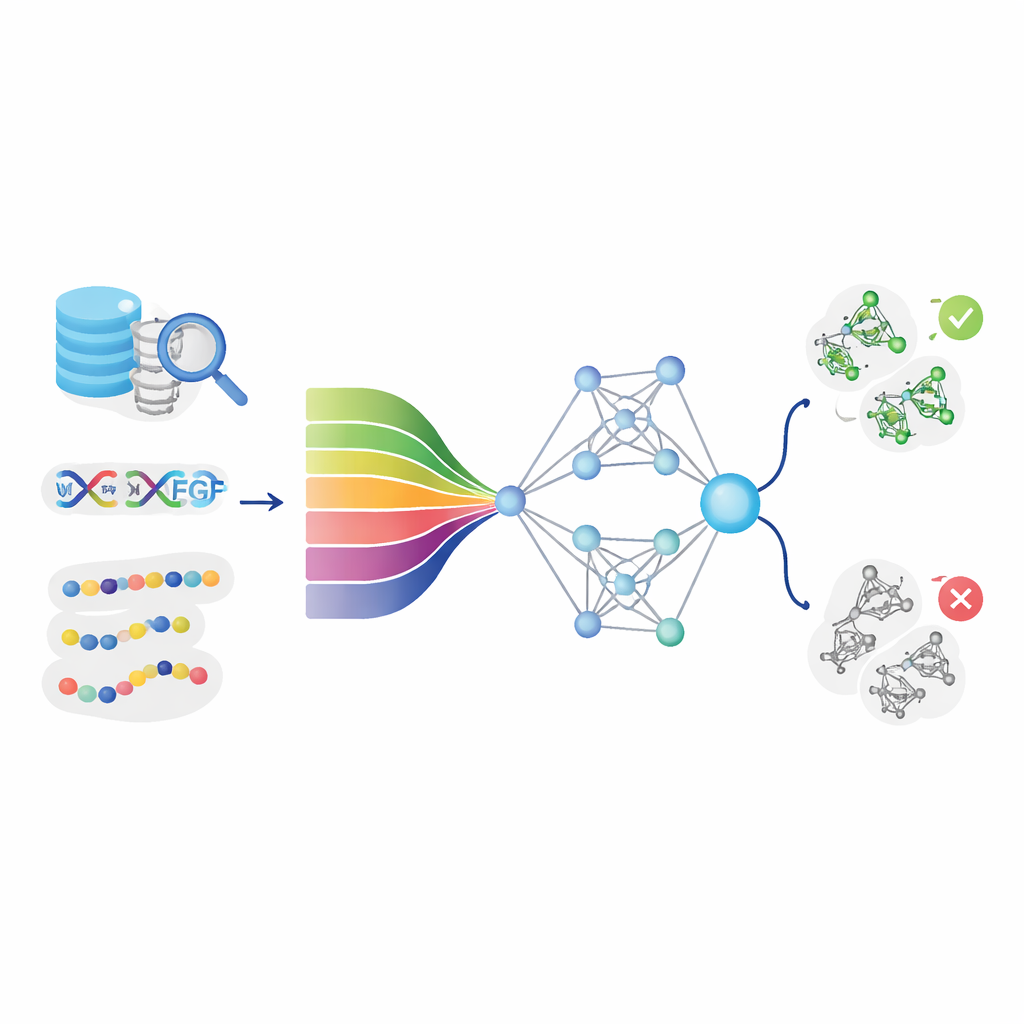
Insegnare ai computer a leggere il “linguaggio” delle proteine
L’idea centrale di DeepStack-VEGF è che la sequenza di una proteina contiene schemi nascosti che suggeriscono il suo comportamento. Il team ha raccolto migliaia di proteine VEGF e non-VEGF dai principali database e ha pulito i dati con cura per evitare quasi-duplicati. Ha quindi descritto ogni proteina da molte angolazioni. Alcune caratteristiche catturavano la chimica di base, come quanto sono idrofobiche o cariche determinate posizioni. Altre riassumevano la frequenza di certe coppie o triplette di amminoacidi, o la probabilità che la catena si ripiegasse in eliche e foglietti. In modo cruciale, il modello ha anche utilizzato moderni “modelli linguistici per proteine” — sistemi di intelligenza artificiale che, come gli strumenti linguistici per il testo, apprendono pattern profondi da milioni di sequenze proteiche naturali e trasformano ciascuna in un ricco’impronta numerica.
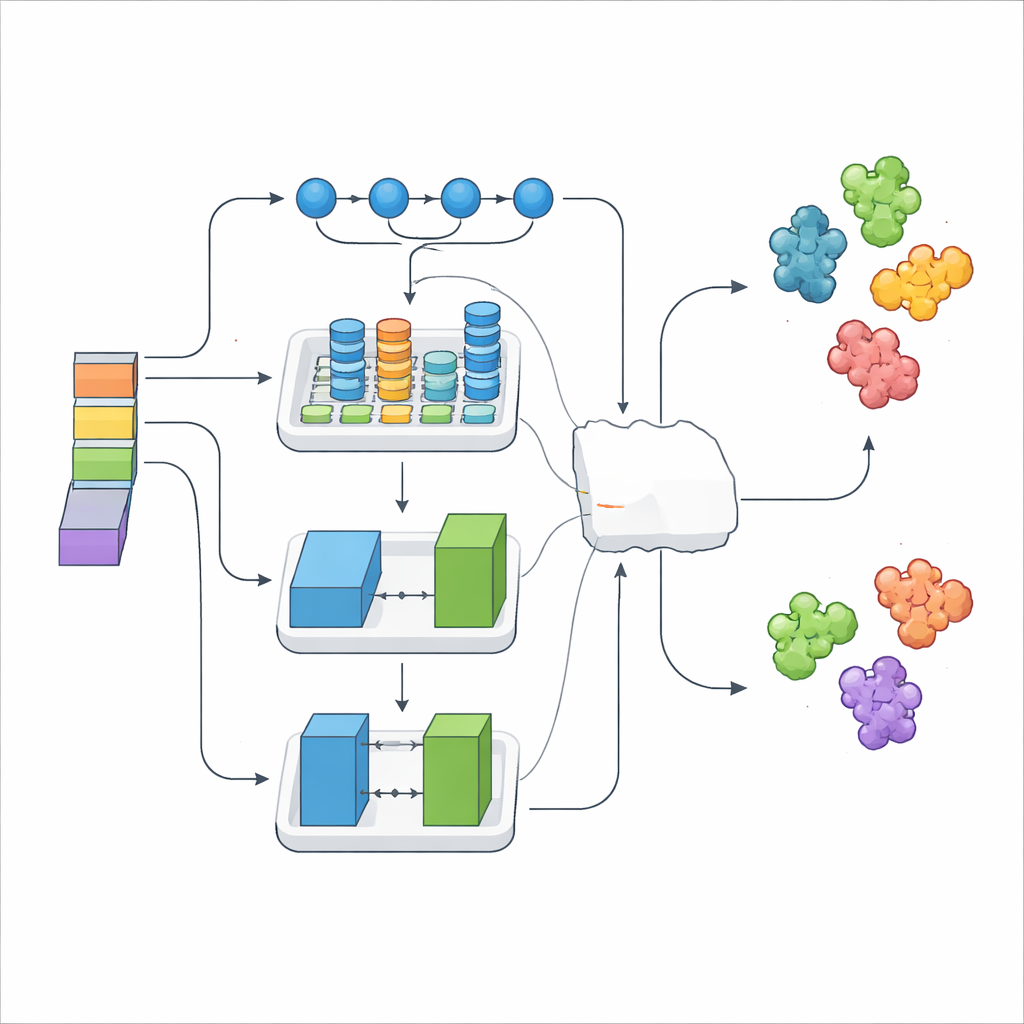
Unire più punti di vista in una decisione
Limitarsi ad accatastare migliaia di caratteristiche numeriche può introdurre rumore, quindi i ricercatori hanno impiegato un metodo di selezione che conserva solo i segnali più informativi. Queste caratteristiche raffinate sono state poi fornite a tre diversi moduli di deep learning, ciascuno con una specialità distinta. Un modello eccelleva nel tracciare pattern a lungo raggio lungo la sequenza, un altro coglieva motivi strutturali locali e le loro relazioni, e un terzo usava una configurazione generatore–critico di stampo ludico per arricchire e regolarizzare i dati. Sulla cima di questi, uno strato “meta” ha imparato come combinare al meglio i loro output, formando l’ensemble DeepStack-VEGF. Questa strategia a strati rispecchia come un pannello di esperti, ciascuno con una formazione diversa, potrebbe esprimersi prima di giungere a una conclusione comune.
Verificare l’accuratezza e aprire la scatola nera
Per testare il sistema, gli autori hanno usato una rigorosa validazione incrociata e un set di test indipendente. Su diverse misure di accuratezza, DeepStack-VEGF ha superato ciascuno dei suoi modelli componenti e due precedenti predittori di VEGF allo stato dell’arte. La versione finale ha classificato correttamente le proteine simili al VEGF in ben più di nove casi su dieci, con meno falsi allarmi rispetto agli approcci concorrenti. Il team ha anche applicato un metodo di spiegazione che stima quanto ciascuna caratteristica in ingresso spinge la decisione verso “VEGF” o “non VEGF”. Questa analisi ha mostrato che le impronte apprese dai modelli linguistici per proteine fornivano la maggior parte della potenza predittiva, mentre le caratteristiche tradizionali basate su chimica e struttura aggiungevano dettagli fini e stabilità.
Cosa significa per medicina e ricerca
Per i non specialisti, DeepStack-VEGF può essere visto come un riconoscitore di pattern altamente addestrato per un segnale chiave di guarigione nell’organismo. Invece di attendere esperimenti laboriosi, gli scienziati possono ora inserire sequenze proteiche nel modello per stimare rapidamente se si comportano come il VEGF. Questa capacità può aiutare a restringere i candidati per nuovi trattamenti contro il cancro o le malattie oculari, guidare la progettazione di farmaci anti-angiogenici e supportare ricerche proteiniche più ampie. Pur richiedendo ancora conferma di laboratorio per qualsiasi predizione promettente, strumenti come DeepStack-VEGF spostano parte del lavoro di scoperta dal banco al computer, rendendo potenzialmente più rapide ed economiche le terapie future.
Citazione: Ali, F., Khalid, M., Algarni, A. et al. DeepStackVEGF a stacking ensemble deep learning framework for vascular endothelial growth factor prediction. Sci Rep 16, 13035 (2026). https://doi.org/10.1038/s41598-026-40134-0
Parole chiave: predizione VEGF, angiogenesi, deep learning in biologia, modelli linguistici per proteine, scoperta di farmaci