Clear Sky Science · pt
DeepStackVEGF: um framework de aprendizado profundo em empilhamento para predição do fator de crescimento endotelial vascular
Por que prever um sinal de cicatrização importa
Nossos corpos dependem de uma proteína chamada fator de crescimento endotelial vascular, ou VEGF, para formar novos vasos sanguíneos. Esse sinal é essencial para a cicatrização de feridas, reparo ósseo e suporte ao desenvolvimento normal — mas os cânceres também o sequestram para nutrir tumores e se espalhar pelo corpo. Medir e caracterizar o VEGF no laboratório é um processo lento e caro. Este estudo apresenta o DeepStack-VEGF, um modelo computacional poderoso que pode prever rapidamente se uma dada proteína age como o VEGF, potencialmente acelerando a descoberta de fármacos e a medicina de precisão.
Do banco de laboratório ao laptop
Tradicionalmente, os pesquisadores usam técnicas sofisticadas como cristalografia, RMN e coloração de tecidos para estudar o VEGF. Esses métodos revelam a estrutura e a localização da molécula, mas exigem equipamentos especializados e tempo. Ao mesmo tempo, vastos bancos de dados públicos agora contêm milhões de sequências proteicas cuja função permanece apenas parcialmente conhecida. Os autores identificaram uma oportunidade: em vez de primeiro cultivar cristais ou realizar experimentos complexos, por que não deixar os computadores vasculharem sequências proteicas e assinalarem aquelas que provavelmente atuam como VEGF? O DeepStack-VEGF foi projetado como uma ferramenta rápida e escalável para fazer exatamente isso — transformar letras brutas de proteínas em previsões significativas.
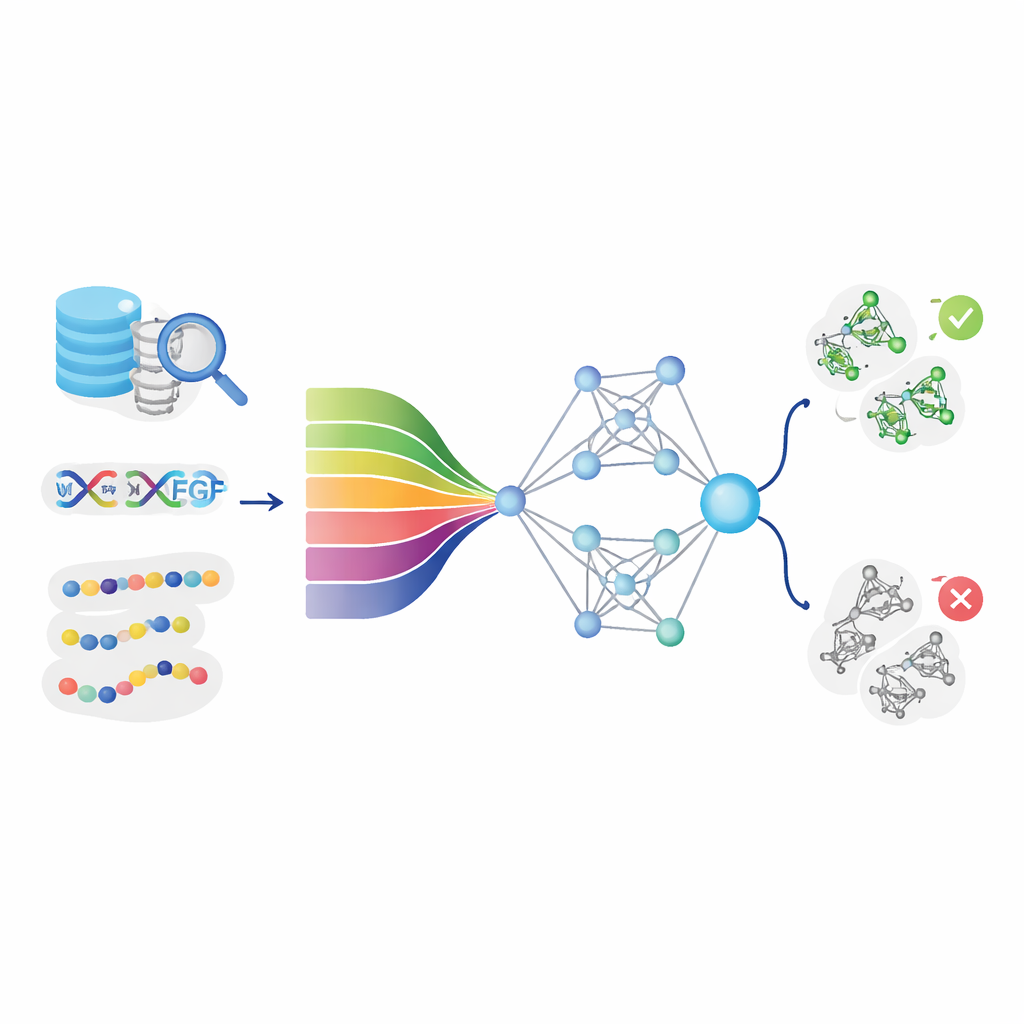
Ensinando computadores a ler a "linguagem" das proteínas
A ideia central do DeepStack-VEGF é que a sequência de uma proteína contém padrões ocultos que sugerem seu comportamento. A equipe reuniu milhares de proteínas VEGF e não-VEGF em grandes bancos de dados e limpou cuidadosamente os dados para evitar quase-duplicatas. Em seguida, descreveram cada proteína por vários ângulos. Algumas características capturaram química básica, como quão hidrofóbicas ou carregadas são diferentes posições. Outras resumiram com que frequência certos pares ou trincas de blocos aparecem, ou como a cadeia tende a se dobrar em hélices e folhas. De forma crucial, o modelo também usou modernos "modelos de linguagem de proteínas" — sistemas de inteligência artificial que, como ferramentas de linguagem para texto, aprendem padrões profundos a partir de milhões de sequências proteicas naturais e transformam cada uma em uma assinatura numérica rica.
Unindo múltiplos pontos de vista em uma única decisão
Simplesmente empilhar milhares de características numéricas pode introduzir ruído, então os pesquisadores usaram um método de seleção que retém apenas os sinais mais informativos. Essas características refinadas foram então alimentadas em três módulos de aprendizado profundo diferentes, cada um com uma especialidade distinta. Um modelo destacou-se por rastrear padrões de longo alcance ao longo da sequência, outro capturou motivos estruturais locais e suas relações, e um terceiro usou uma configuração gerador–crítico semelhante a jogos para enriquecer e regularizar os dados. Sobre esses, uma camada "meta" aprendeu a melhor forma de combinar suas saídas, formando o ensemble DeepStack-VEGF. Essa estratégia em camadas reflete como um painel de especialistas, cada um com formação diferente, poderia contribuir antes de chegar a uma conclusão conjunta.
Verificando a acurácia e abrindo a caixa-preta
Para testar o sistema, os autores usaram validação cruzada rigorosa e um conjunto de teste independente. Em várias métricas de acurácia, o DeepStack-VEGF superou cada um de seus modelos componentes e dois preditores anteriores de ponta para VEGF. Sua versão final classificou corretamente proteínas semelhantes ao VEGF em bem mais de nove em cada dez casos, com menos falsos positivos do que abordagens concorrentes. A equipe também aplicou um método de explicação que estima quanto cada característica de entrada empurra a decisão para "VEGF" ou "não VEGF". Essa análise mostrou que as impressões digitais aprendidas pelos modelos de linguagem de proteínas forneceram a maior parte do poder preditivo, enquanto características tradicionais baseadas em química e estrutura acrescentaram detalhes finos e estabilidade.
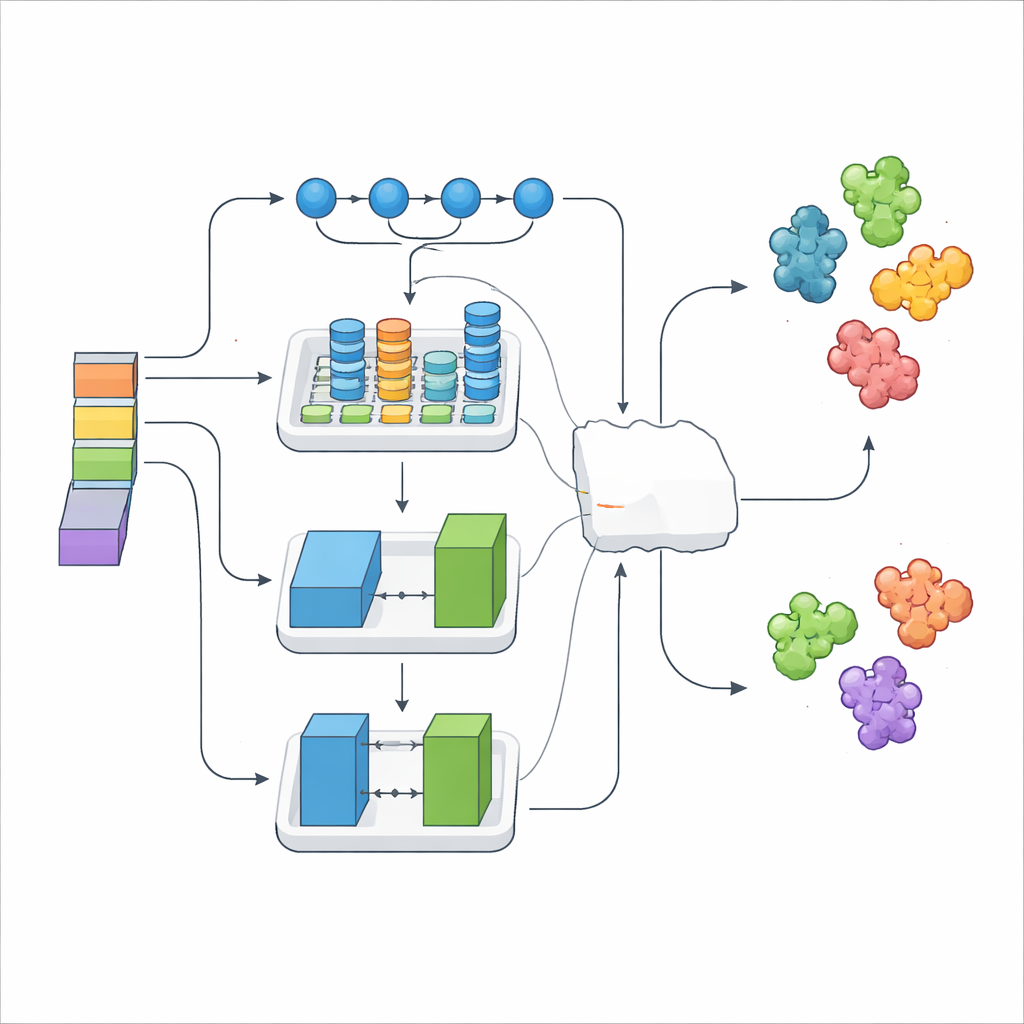
O que isso significa para a medicina e a pesquisa
Para não especialistas, o DeepStack-VEGF pode ser visto como um reconhecedor de padrões altamente treinado para um sinal de cicatrização chave no corpo. Em vez de aguardar experimentos trabalhosos, os cientistas agora podem alimentar sequências proteicas no modelo para estimar rapidamente se elas se comportam como o VEGF. Essa capacidade pode ajudar a reduzir candidatos para novos tratamentos contra câncer ou doenças oculares, orientar o desenho de fármacos antiangiogênicos e apoiar pesquisa proteica mais ampla. Embora qualquer previsão promissora ainda exija confirmação laboratorial, ferramentas como o DeepStack-VEGF transferem parte do trabalho de descoberta do banco para o computador, potencialmente tornando o desenvolvimento de futuras terapias mais rápido e barato.
Citação: Ali, F., Khalid, M., Algarni, A. et al. DeepStackVEGF a stacking ensemble deep learning framework for vascular endothelial growth factor prediction. Sci Rep 16, 13035 (2026). https://doi.org/10.1038/s41598-026-40134-0
Palavras-chave: predição de VEGF, angiogênese, aprendizado profundo em biologia, modelos de linguagem de proteínas, descoberta de fármacos