Clear Sky Science · zh
FAIR m-BIDS:通过多模态与 FAIR 原则推进大脑数据利用
为何组织大脑数据至关重要
现代大脑研究产生大量数字信息:脑部扫描、电生理记录、基因数据,甚至是关于行为的详细笔记。然而许多信息被锁定在难以检索、合并或重用的格式中。本文介绍了 FAIR m-BIDS,这是一种组织大脑数据的新方法,使世界各地的科学家能更容易地发现、关联并在保障安全的前提下重用来自多种研究类型的信息。
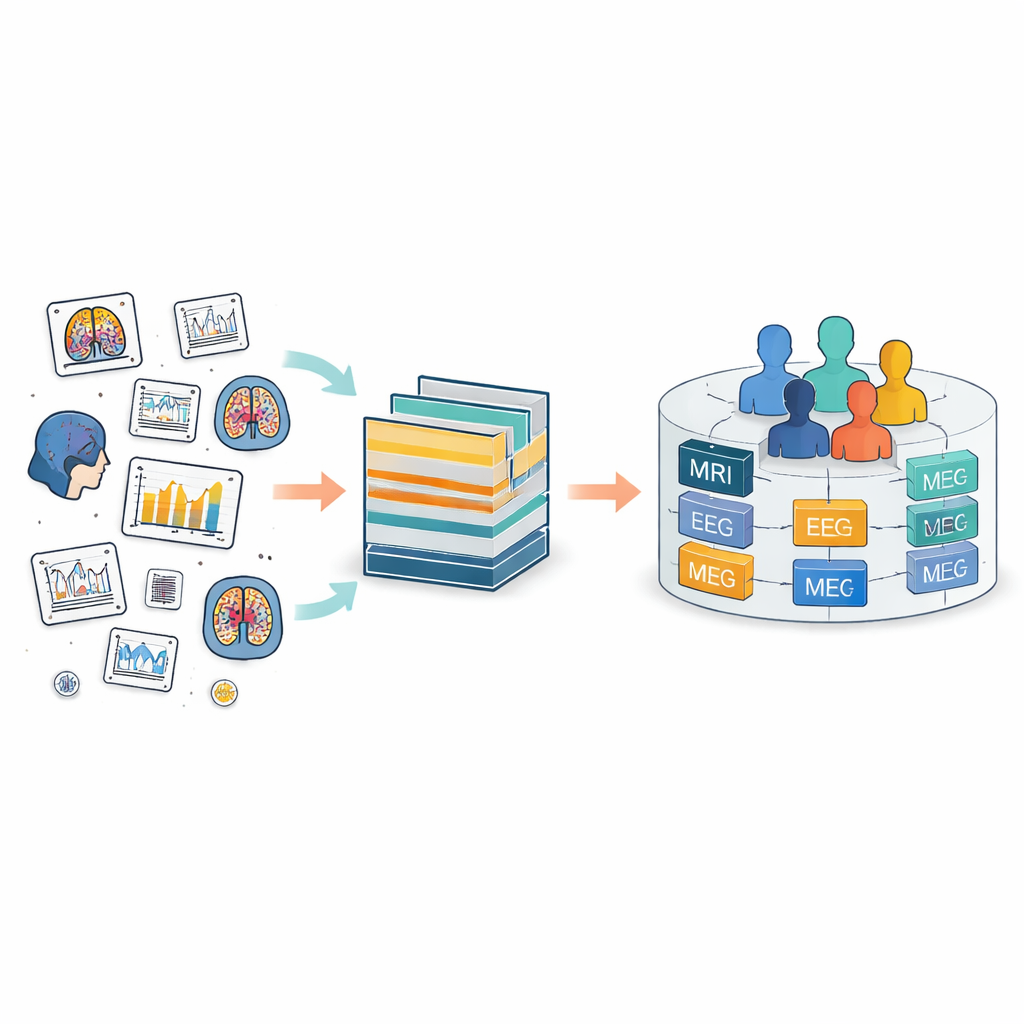
分散的大脑记录问题
如今,大脑数据在全球范围内由多种仪器采集,从 MRI 扫描仪到 EEG 帽再到运动传感器。脑影像数据结构(BIDS)旨在通过定义通用的文件夹布局和文件命名为这片混乱带来秩序。BIDS 已扩展到许多测量类型,但它仍把每个研究视为独立的孤岛。在每个孤岛内,人员和文件往往采用本地标签,这些标签常常不在跨研究之间一致。这就导致难以追踪同一人在不同时间点的数据,或将同一人的不同类型测量(例如脑部扫描、电生理活动和临床记录)进行匹配和整合。
可供他人使用的 FAIR 规则
与此同时,许多领域现在都力求遵循 FAIR 原则:数据应当是可发现(Findable)、可获取(Accessible)、可互操作(Interoperable)且可重用(Reusable)。对于大脑研究而言,这意味着能够跨多个数据集合检索、精确获取所需部分、顺畅地合并不同数据类型,并在此过程中尊重隐私。经典 BIDS 在 FAIR 正式定义之前就已设计,因此不能完全支持这些目标。例如,浏览单个数据集很容易,但要在多个数据集中搜索特定年龄组、诊断或扫描类型的所有记录则很困难。
为每个文件和每个人新增标记的方法
FAIR m-BIDS 保留了 BIDS 熟悉的外观和使用感,但增加了一层智能标识符。每个数据文件都会获得自己的全局唯一标识键(Global Unique Identifier Key,或文件键),该键随时间稳定并在整个平台范围内唯一。每位参与者会获得一个全局唯一受试者标识符(Global Unique Subject Identifier,或受试者键),无论他们参与多少研究,该标识都保持一致。每个数据集合也会获得一个全局数据集键。在后台,这些键通过固定的数学函数生成,以在隐藏个人细节的同时允许经过授权的系统识别出不同文件是否属于同一名匿名个体。这种细粒度的标记使研究人员可以基于丰富的描述搜索、过滤和重新组合文件,而不受限于原始文件夹结构。
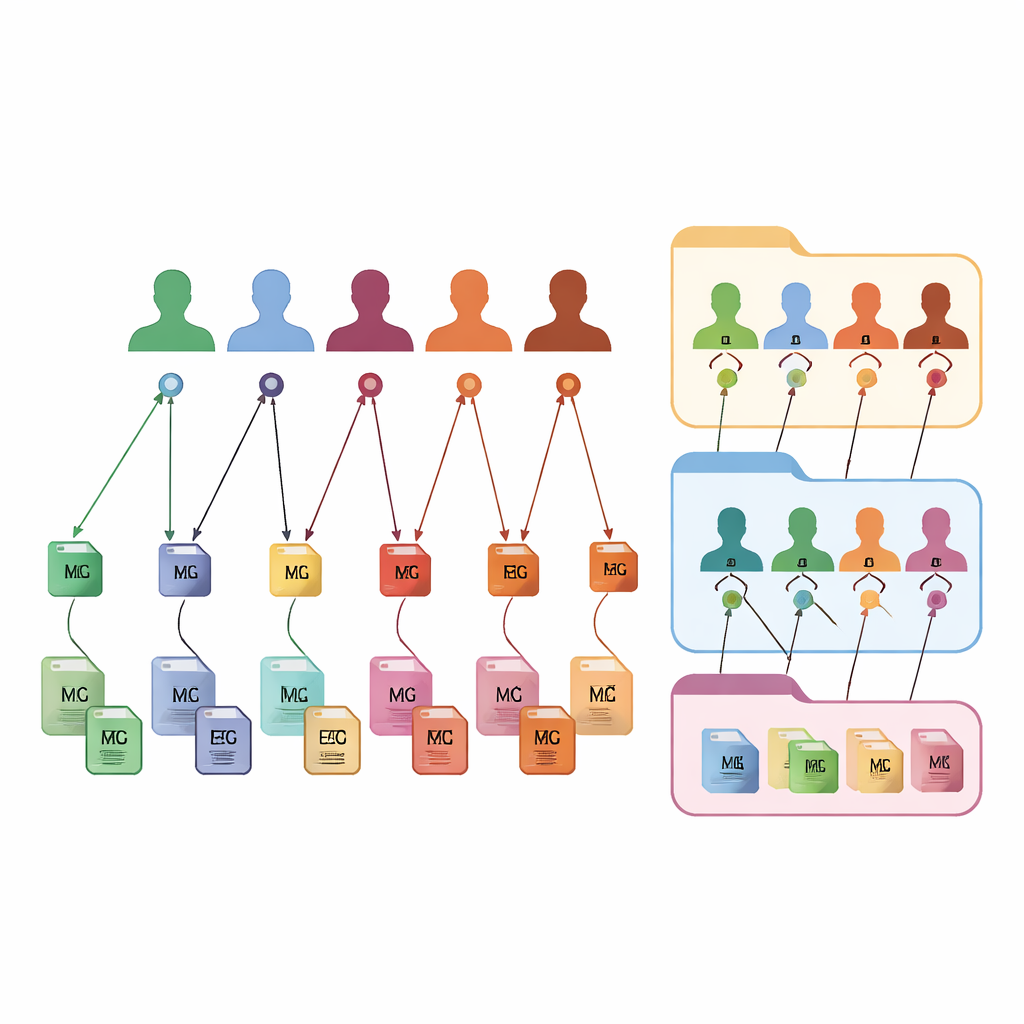
按需构建自定义集合
由于每个文件、受试者和数据集都通过这些键相互关联,FAIR m-BIDS 将静态档案转变为灵活的生物样本库。科学家可以向系统提出详细查询:例如,“给我所有来自50–60岁并出现记忆力下降迹象的女性的脑部扫描和 EEG 记录”,系统即可返回跨越多个原始研究的现成数据包。系统还可以将这些查询结果保存为新的数据集,每个新的数据集都有自己的数据集键,但仍可追溯到原始来源。这让进行大规模多模态研究、随访同一人群随时间的变化、比较方法以及重复或扩展既有工作变得更容易。该结构已在公共数据集上进行测试,并正在伊朗的国家脑图谱生物库中推广,在那里它将为在线探索与分析平台提供支持。
保持数据有用、互联与安全
简言之,作者展示了如何在现有标准之上添加智能且保护隐私的标识,从而将分散的大脑记录转变为组织良好、可搜索的资料库。FAIR m-BIDS 在隐藏敏感细节的同时允许经授权的工具将多个研究中的文件、人员和集合连接起来。这使得大脑数据更易被发现、合并与重用,帮助研究人员构建更为丰富的脑健康与疾病图景,并为更可靠、协作性更强和以数据为驱动的神经科学铺平道路。
引用: Mirhosseini, S.M., Naseri, H., Siahlou, B. et al. FAIR m-BIDS: Advancing brain data utilization through multimodal and FAIR principles. Sci Data 13, 555 (2026). https://doi.org/10.1038/s41597-026-06790-7
关键词: 大脑数据, 神经影像学, 数据标准, 多模态数据集, FAIR 原则