Clear Sky Science · ru
FAIR m-BIDS: Повышение полезности данных о мозге с помощью мультимодальности и принципов FAIR
Почему важно упорядочивать данные о мозге
Современные исследования мозга генерируют поток цифровой информации: снимки мозга, электрические записи, генетические данные и даже подробные заметки о поведении. Тем не менее большая часть этих данных остаётся закрытой в форматах, которые трудно искать, объединять или повторно использовать. В этой работе представлен FAIR m-BIDS — новый способ организации данных о мозге, который позволяет учёным по всему миру легче находить, связывать и безопасно повторно использовать информацию из разных типов исследований.
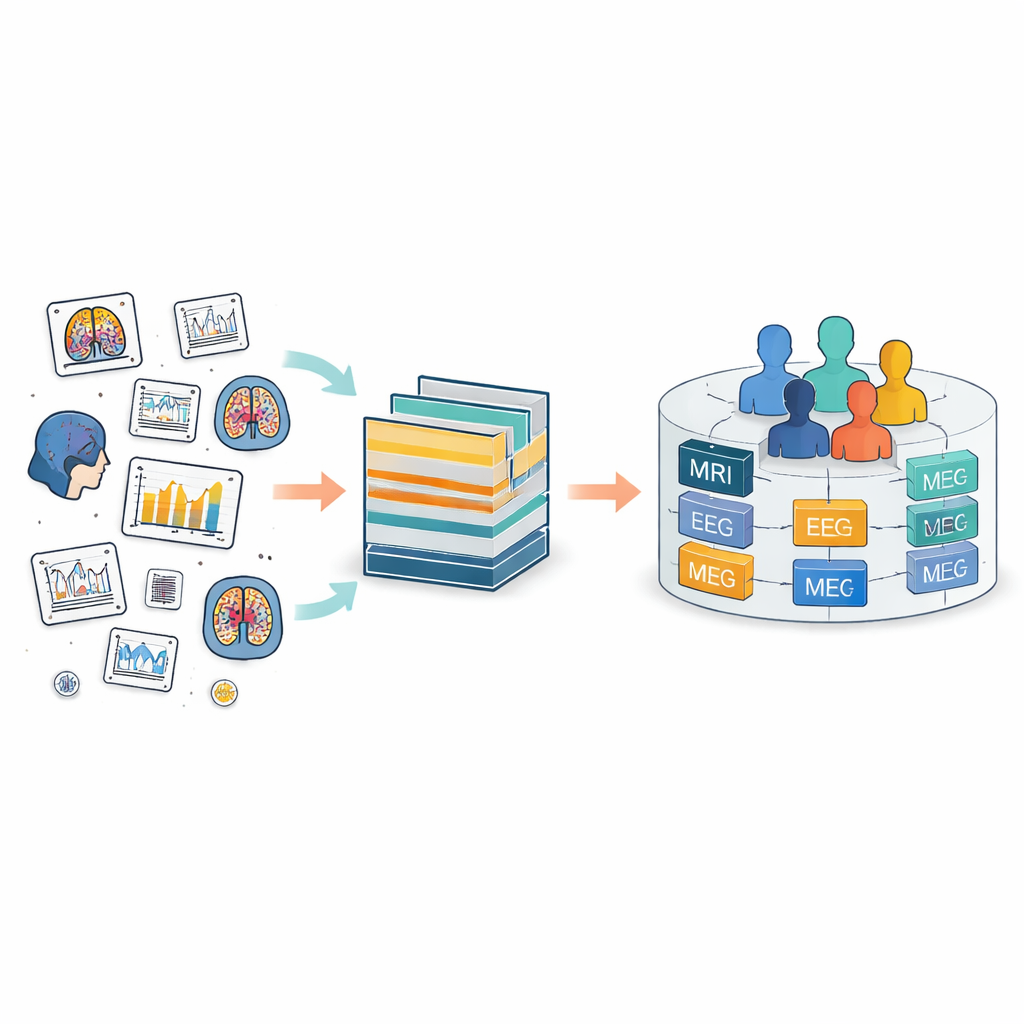
Проблема разрозненных записей о мозге
Сегодня данные о мозге собираются повсеместно с помощью множества приборов — от МРТ-сканеров до ЭЭГ-шапочек и датчиков движения. Структура данных мозговой визуализации (BIDS) была создана, чтобы навести порядок в этом хаосе, задавая общие макеты папок и имена файлов. BIDS расширяли для многих типов измерений, но он по-прежнему рассматривает каждое исследование как отдельный остров. Внутри каждого такого острова людям и файлам присваивают локальные метки, которые часто не совпадают между исследованиями. Это затрудняет отслеживание одного и того же человека во времени или объединение разных типов измерений для этого человека — например, сопоставление его МРТ с электрической активностью и клиническими записями.
Правила FAIR для данных, которыми могут пользоваться другие
В то же время во многих областях теперь стремятся следовать принципам FAIR: данные должны быть находимыми (Findable), доступными (Accessible), совместимыми (Interoperable) и пригодными для повторного использования (Reusable). Для исследований мозга это означает возможность искать по множеству коллекций, извлекать именно те фрагменты, которые нужны, плавно объединять разные типы данных и всё это — с уважением к приватности. Классический BIDS был разработан до формального определения FAIR и поэтому не полностью поддерживает эти цели. Например, легко просматривать отдельный набор данных, но сложно искать по многим наборам записи для конкретной возрастной группы, диагноза или типа сканирования.
Новый способ маркировать каждый файл и каждого человека
FAIR m-BIDS сохраняет знакомый внешний вид BIDS, но добавляет новый уровень «умных» идентификаторов. Каждый файл данных получает свой глобальный уникальный идентификатор (Global Unique Identifier Key), или ключ файла, который стабилен с течением времени и уникален в рамках всей платформы. Каждый участник получает глобальный уникальный идентификатор субъекта (Global Unique Subject Identifier), или ключ субъекта, который остаётся одинаковым независимо от числа исследований, в которых он участвует. Каждая коллекция данных также получает глобальный ключ набора данных. За кулисами эти ключи создаются с использованием фиксированных математических функций, которые скрывают личные данные, но при этом позволяют авторизованным системам распознавать, когда разные файлы принадлежат одному и тому же анонимному человеку. Такое детальное тегирование позволяет исследователям искать, фильтровать и группировать файлы на основе богатых описаний, не оставаясь в рамках исходной структуры папок.
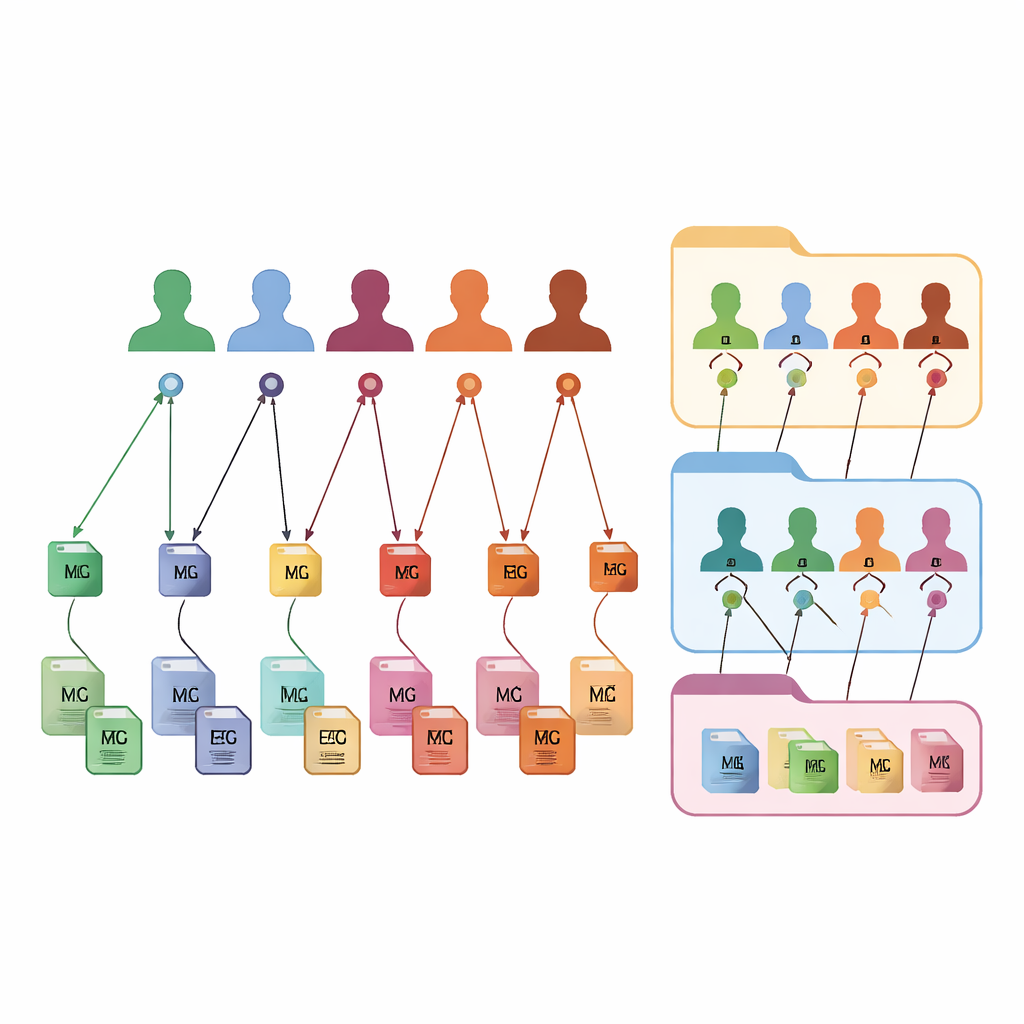
Создание пользовательских коллекций по запросу
Поскольку каждый файл, субъект и набор данных связаны через эти ключи, FAIR m-BIDS превращает статичный архив в гибридный биобанк. Учёные могут задавать системе подробные запросы: например, «дай мне все МРТ и ЭЭГ-записи женщин в возрасте 50–60 лет с признаками ухудшения памяти» и получить готовый пакет, охватывающий несколько исходных исследований. Система может сохранять результаты таких запросов как новые наборы данных, каждый со своим ключом набора данных, но всё ещё связанным с исходными источниками. Это упрощает проведение крупномасштабных мультимодальных исследований, отслеживание тех же людей во времени, сравнение методов и повторение или расширение предыдущих работ. Структура была протестирована на публичных наборах данных и внедряется в национальный биобанк картирования мозга в Иране, где она будет служить основой онлайн-платформы для исследования и анализа.
Сохранение полезности, связности и безопасности данных
Проще говоря, авторы демонстрируют, как добавление умных, сохраняющих приватность идентификаторов поверх существующих стандартов может превратить разрозненные записи о мозге в хорошо организованную, доступную для поиска библиотеку. FAIR m-BIDS скрывает чувствительные детали, позволяя при этом авторизованным инструментам связывать файлы, людей и коллекции между множеством исследований. Это делает данные о мозге легче для поиска, объединения и повторного использования, помогая исследователям строить более полные картины здоровья и заболеваний мозга и прокладывая путь к более надёжной, совместной и основанной на данных нейронауке.
Цитирование: Mirhosseini, S.M., Naseri, H., Siahlou, B. et al. FAIR m-BIDS: Advancing brain data utilization through multimodal and FAIR principles. Sci Data 13, 555 (2026). https://doi.org/10.1038/s41597-026-06790-7
Ключевые слова: данные о мозге, нейровизуализация, стандарты данных, мультимодальные наборы данных, принципы FAIR