Clear Sky Science · nl
FAIR m-BIDS: Het bevorderen van het gebruik van hersengegevens via multimodale en FAIR-principes
Waarom het organiseren van hersengegevens ertoe doet
Moderne hersenonderzoeken produceren een stortvloed aan digitale informatie: hersenscans, elektrische opnamen, genetische data en zelfs gedetailleerde aantekeningen over gedrag. Veel van deze informatie blijft echter opgesloten in formaten die moeilijk te doorzoeken, te combineren of opnieuw te gebruiken zijn. Dit artikel introduceert FAIR m-BIDS, een nieuwe manier om hersengegevens te organiseren zodat wetenschappers overal ter wereld gemakkelijker informatie uit verschillende soorten studies kunnen vinden, verbinden en veilig hergebruiken.
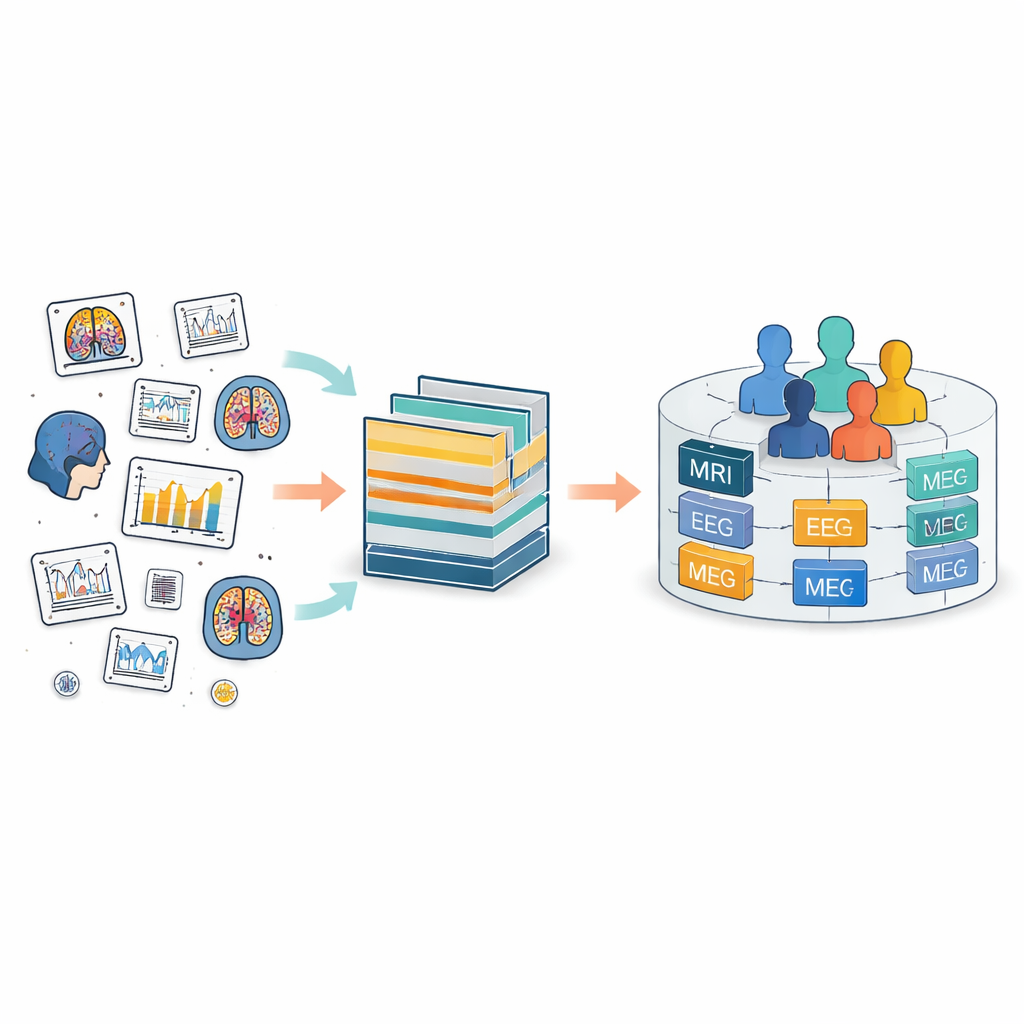
Het probleem van verspreide hersenregistraties
Vandaag de dag worden hersengegevens over de hele wereld verzameld met veel verschillende instrumenten, van MRI-scanners tot EEG-kappen en bewegingssensoren. De Brain Imaging Data Structure (BIDS) is ontworpen om orde te scheppen in deze chaos door gemeenschappelijke mappenstructuren en bestandsnamen te definiëren. BIDS is uitgebreid naar vele soorten metingen, maar beschouwt elke studie nog steeds als een apart eiland. Binnen elk eiland krijgen personen en bestanden lokale labels die vaak niet overeenkomen tussen studies. Dat maakt het moeilijk om dezelfde persoon over de tijd te volgen of om verschillende soorten metingen van die persoon te combineren, bijvoorbeeld het koppelen van een hersenscan aan elektrische activiteit en klinische gegevens.
FAIR-regels voor gegevens die anderen kunnen gebruiken
Tegelijk streven veel vakgebieden nu naar de FAIR-principes: gegevens moeten Findable (vindbaar), Accessible (toegankelijk), Interoperable (interoperabel) en Reusable (herbruikbaar) zijn. Voor hersenonderzoek betekent dit dat je over meerdere verzamelingen kunt zoeken, precies de benodigde onderdelen kunt ophalen, verschillende datatypen soepel kunt combineren en dit alles kunt doen met respect voor privacy. Klassieke BIDS is ontworpen voordat FAIR formeel werd gedefinieerd en ondersteunt deze doelen niet volledig. Het is bijvoorbeeld eenvoudig om één dataset te doorbladeren, maar lastig om over veel datasets heen te zoeken naar alle opnamen van een bepaalde leeftijdsgroep, diagnose of type scan.
Een nieuwe manier om elk bestand en elke persoon te taggen
FAIR m-BIDS behoudt het vertrouwde uiterlijk en gevoel van BIDS, maar voegt een nieuwe laag slimme identificatoren toe. Elk databestand krijgt een eigen Global Unique Identifier Key, of bestandskey, die in de tijd stabiel is en uniek is binnen het hele platform. Elke deelnemer krijgt een Global Unique Subject Identifier, of subjectkey, die hetzelfde blijft ongeacht het aantal studies waaraan die persoon deelneemt. Elke collectie gegevens krijgt ook een globale datasetkey. Achter de schermen worden deze keys gemaakt met vaste wiskundige functies die persoonlijke details verbergen maar toch toestaan dat goedgekeurde systemen herkennen wanneer verschillende bestanden bij dezelfde anonieme persoon horen. Deze fijnmazige tagging stelt onderzoekers in staat bestanden te doorzoeken, filteren en hergroeperen op basis van rijke beschrijvingen zonder vast te zitten aan de oorspronkelijke mappenstructuur.
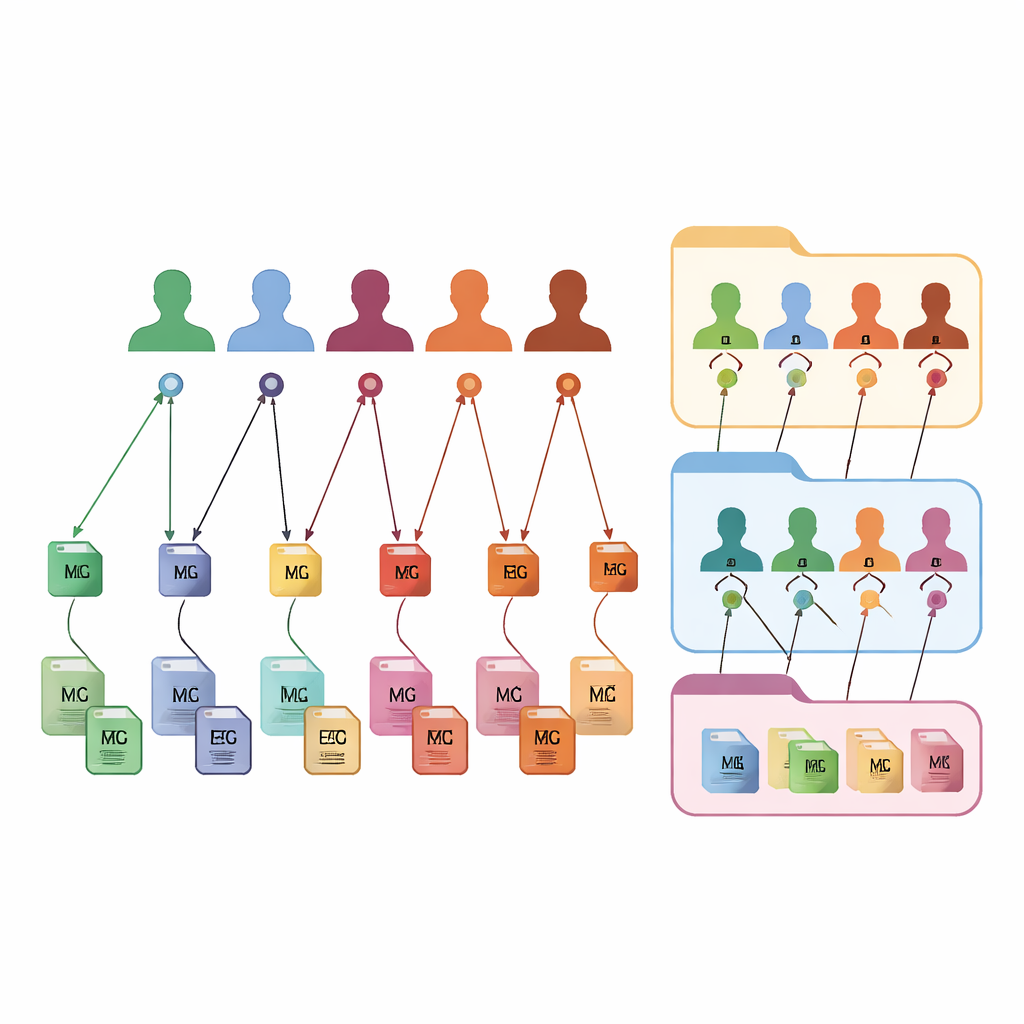
Aangepaste verzamelingen op aanvraag samenstellen
Omdat elk bestand, subject en dataset via deze keys verbonden is, verandert FAIR m-BIDS een statische archief in een flexibele biobank. Wetenschappers kunnen gedetailleerde vragen aan het systeem stellen: bijvoorbeeld “geef mij alle hersenscans en EEG-opnamen van vrouwen van 50–60 jaar met aanwijzingen voor geheugenverlies,” en ontvangen een kant-en-klaar pakket dat meerdere oorspronkelijke studies overspant. Het systeem kan deze zoekresultaten opslaan als nieuwe datasets, elk met een eigen datasetkey maar nog steeds terug te voeren naar de originele bronnen. Dit vergemakkelijkt grootschalige multimodale studies, het volgen van dezelfde personen in de tijd, het vergelijken van methoden en het herhalen of uitbreiden van eerder werk. De structuur is getest op openbare datasets en wordt uitgerold in een nationale hersenkaart-biobank in Iran, waar het een online platform voor verkenning en analyse zal ondersteunen.
Gegevens nuttig, verbonden en veilig houden
In eenvoudige bewoordingen laten de auteurs zien hoe het toevoegen van slimme, privacybeschermende ID's bovenop bestaande standaarden verspreide hersenregistraties kan omzetten in een goed georganiseerde, doorzoekbare bibliotheek. FAIR m-BIDS houdt gevoelige details verborgen terwijl goedgekeurde tools bestanden, personen en collecties over meerdere studies kunnen koppelen. Dit maakt hersengegevens gemakkelijker te vinden, te combineren en te hergebruiken, helpt onderzoekers rijkere beelden van hersengezondheid en -ziekte op te bouwen en effent de weg voor betrouwbaardere, samenwerkingsgerichte en data-gedreven neurowetenschap.
Bronvermelding: Mirhosseini, S.M., Naseri, H., Siahlou, B. et al. FAIR m-BIDS: Advancing brain data utilization through multimodal and FAIR principles. Sci Data 13, 555 (2026). https://doi.org/10.1038/s41597-026-06790-7
Trefwoorden: hersengegevens, neurale beeldvorming, gegevensstandaarden, multimodale datasets, FAIR-principes