Clear Sky Science · es
FAIR m-BIDS: Avanzando el uso de datos cerebrales mediante principios multimodales y FAIR
Por qué importa organizar los datos cerebrales
La investigación cerebral moderna produce un alud de información digital: exploraciones cerebrales, registros eléctricos, datos genéticos e incluso notas detalladas sobre comportamiento. Sin embargo, gran parte de esta información está encerrada en formatos que son difíciles de buscar, combinar o reutilizar. Este artículo presenta FAIR m-BIDS, una nueva forma de organizar los datos cerebrales para que los científicos de cualquier lugar puedan encontrar, conectar y reutilizar con mayor facilidad y seguridad la información procedente de distintos tipos de estudios.
El problema de los registros cerebrales dispersos
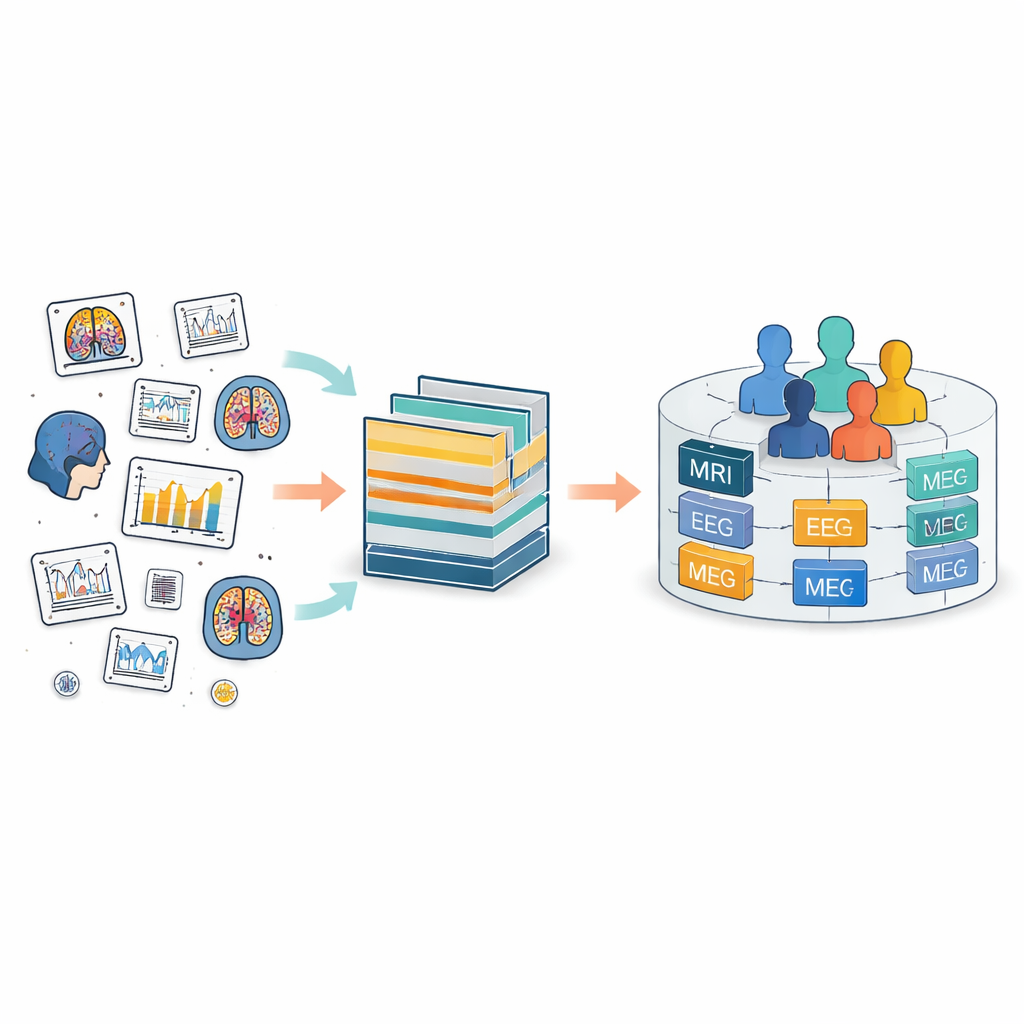
Hoy en día, los datos cerebrales se recogen en todo el mundo con muchas herramientas, desde escáneres de IRM hasta cascos de EEG y sensores de movimiento. El Brain Imaging Data Structure (BIDS) se creó para poner orden en este caos definiendo estructuras comunes de carpetas y nombres de archivos. BIDS se ha extendido a muchos tipos de mediciones, pero aún trata cada estudio como una isla separada. Dentro de cada isla, personas y archivos reciben etiquetas locales propias, que a menudo no coinciden entre estudios. Eso dificulta rastrear a la misma persona a lo largo del tiempo o combinar distintos tipos de mediciones de esa persona, por ejemplo, emparejar su imagen cerebral con su actividad eléctrica y sus registros clínicos.
Reglas FAIR para datos que otros puedan usar
Al mismo tiempo, muchos campos aspiran ahora a seguir los principios FAIR: los datos deben ser Encontrables, Accesibles, Interoperables y Reutilizables. Para la investigación cerebral, esto significa poder buscar entre muchas colecciones, recuperar exactamente las piezas necesarias, combinar distintos tipos de datos con fluidez y hacer todo ello respetando la privacidad. El BIDS clásico fue diseñado antes de que los principios FAIR se definieran formalmente, por lo que no respalda completamente estos objetivos. Por ejemplo, es sencillo navegar por un único conjunto de datos, pero difícil buscar a través de muchos conjuntos todos los registros de un determinado grupo de edad, diagnóstico o tipo de exploración.
Una nueva forma de etiquetar cada archivo y cada persona
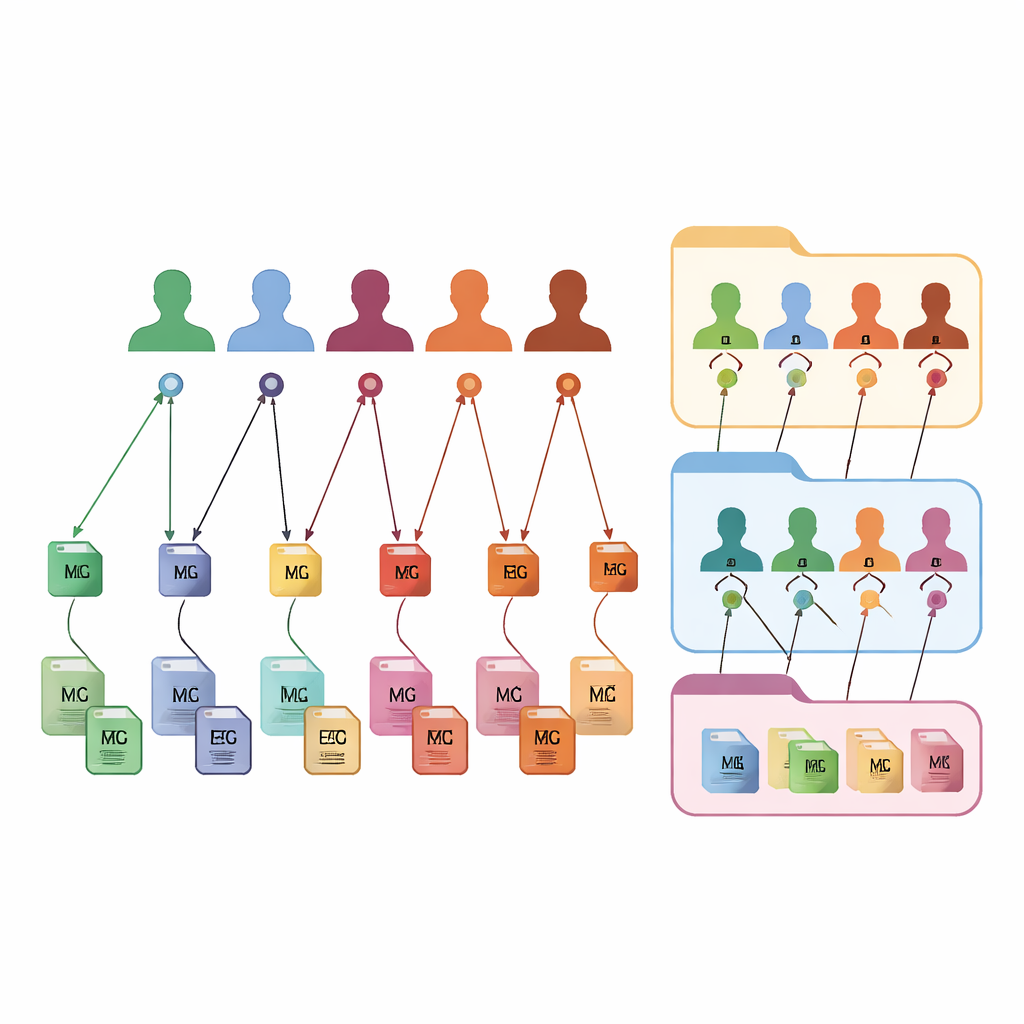
FAIR m-BIDS conserva el aspecto y la sensación familiares de BIDS, pero añade una nueva capa de identificadores inteligentes. Cada archivo de datos recibe su propia Clave Global Única de Identificación, o clave de archivo, que es estable en el tiempo y única en toda la plataforma. Cada participante recibe un Identificador Global Único de Sujeto, o clave de sujeto, que es el mismo sin importar en cuántos estudios participe. Cada colección de datos también obtiene una clave global de conjunto de datos. Tras bastidores, estas claves se crean usando funciones matemáticas fijas que ocultan los detalles personales mientras permiten a los sistemas autorizados reconocer cuándo distintos archivos pertenecen a la misma persona anónima. Esta etiquetación de grano fino permite a los investigadores buscar, filtrar y reagrupar archivos basándose en descripciones ricas sin quedar atrapados dentro de la estructura de carpetas original.
Construir colecciones personalizadas bajo demanda
Dado que cada archivo, sujeto y conjunto de datos está vinculado mediante estas claves, FAIR m-BIDS convierte un archivo estático en un biobanco flexible. Los científicos pueden plantear preguntas detalladas al sistema: por ejemplo, “dame todas las exploraciones cerebrales y los registros EEG de mujeres de 50–60 años con signos de pérdida de memoria”, y recibir un paquete listo que abarque múltiples estudios originales. El sistema puede guardar los resultados de estas consultas como nuevos conjuntos de datos, cada uno con su propia clave de conjunto de datos pero aún enlazado a las fuentes originales. Esto facilita realizar grandes estudios multimodales, seguir a las mismas personas a lo largo del tiempo, comparar métodos y repetir o ampliar trabajos previos. La estructura se ha probado en conjuntos de datos públicos y se está desplegando en un biobanco nacional de mapeo cerebral en Irán, donde alimentará una plataforma en línea para exploración y análisis.
Mantener los datos útiles, conectados y seguros
En términos sencillos, los autores muestran cómo añadir identificadores inteligentes que preservan la privacidad sobre los estándares existentes puede convertir registros cerebrales dispersos en una biblioteca bien organizada y buscable. FAIR m-BIDS mantiene ocultos los detalles sensibles mientras permite que herramientas autorizadas vinculen archivos, personas y colecciones a través de muchos estudios. Esto facilita encontrar, combinar y reutilizar datos cerebrales, ayudando a los investigadores a construir imágenes más completas de la salud y la enfermedad cerebral y allanando el camino hacia una neurociencia más fiable, colaborativa y basada en datos.
Cita: Mirhosseini, S.M., Naseri, H., Siahlou, B. et al. FAIR m-BIDS: Advancing brain data utilization through multimodal and FAIR principles. Sci Data 13, 555 (2026). https://doi.org/10.1038/s41597-026-06790-7
Palabras clave: datos cerebrales, neuroimagen, estándares de datos, conjuntos de datos multimodales, principios FAIR