Clear Sky Science · fr
FAIR m-BIDS : améliorer l’utilisation des données cérébrales grâce aux principes multimodaux et FAIR
Pourquoi l’organisation des données cérébrales est importante
La recherche moderne sur le cerveau génère un flot d’informations numériques : images cérébrales, enregistrements électriques, données génétiques et même des notes détaillées sur le comportement. Pourtant, une grande partie de ces informations reste enfermée dans des formats difficiles à rechercher, combiner ou réutiliser. Cet article présente FAIR m-BIDS, une nouvelle façon d’organiser les données cérébrales afin que les scientifiques, partout dans le monde, puissent plus facilement trouver, relier et réutiliser en toute sécurité des informations issues de nombreux types d’études.
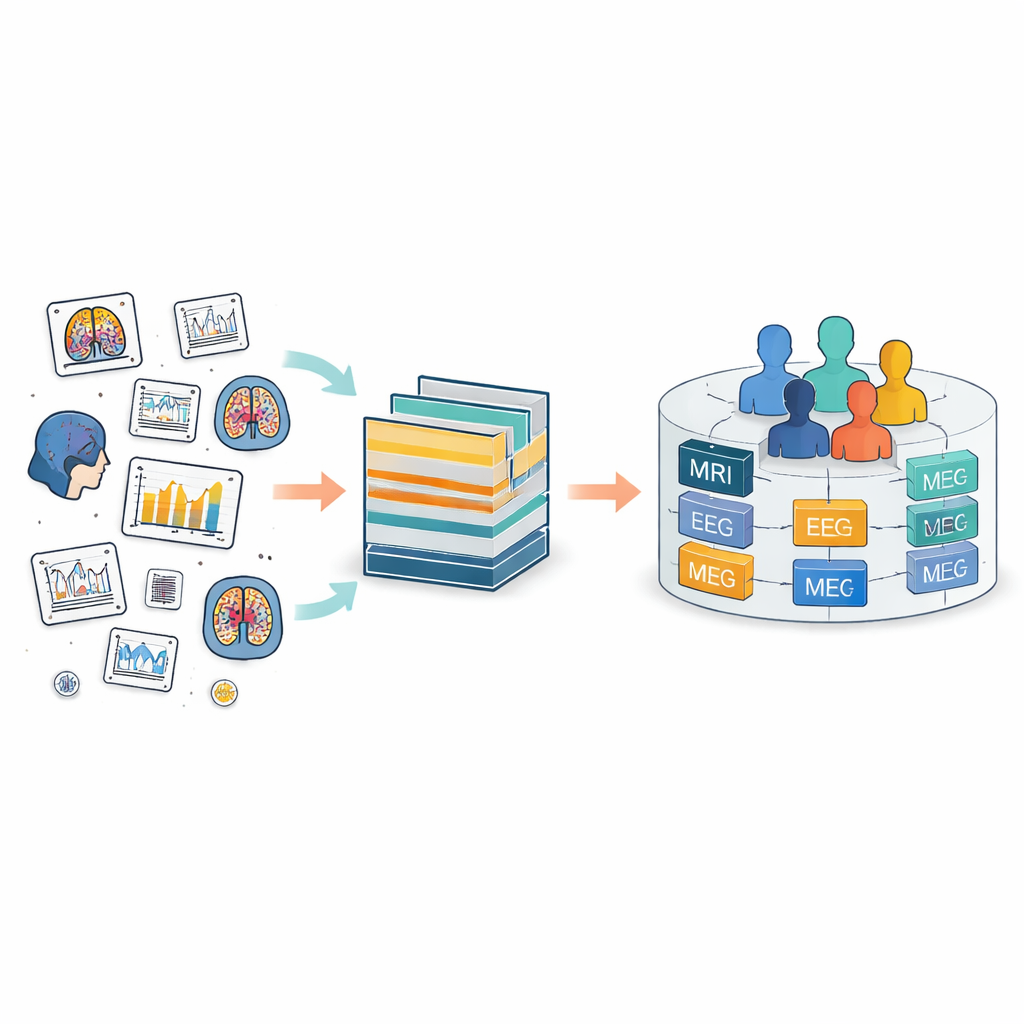
Le problème des dossiers cérébraux éparpillés
Aujourd’hui, les données cérébrales sont collectées partout dans le monde avec de nombreux outils, des scanners IRM aux casques EEG en passant par les capteurs de mouvement. Le Brain Imaging Data Structure (BIDS) a été créé pour apporter de l’ordre dans ce chaos en définissant des agencements de dossiers et des noms de fichiers communs. BIDS a été étendu à de nombreux types de mesures, mais il continue de considérer chaque étude comme une île séparée. À l’intérieur de chaque île, les personnes et les fichiers reçoivent des étiquettes locales qui correspondent souvent peu entre les études. Cela rend difficile le suivi d’une même personne dans le temps ou la combinaison de différents types de mesures pour cette personne, par exemple faire correspondre son image cérébrale avec son activité électrique et ses dossiers cliniques.
Règles FAIR pour des données utilisables par d’autres
Parallèlement, de nombreux domaines cherchent désormais à suivre les principes FAIR : les données doivent être Trouvables, Accessibles, Interopérables et Réutilisables. Pour la recherche sur le cerveau, cela signifie pouvoir interroger plusieurs collections, récupérer exactement les éléments nécessaires, combiner différents types de données de manière fluide et faire tout cela en respectant la confidentialité. Le BIDS classique a été conçu avant la définition formelle des principes FAIR, il ne prend donc pas entièrement en charge ces objectifs. Par exemple, il est facile de parcourir un jeu de données unique, mais difficile de rechercher dans de nombreuses collections tous les enregistrements d’un groupe d’âge particulier, d’un diagnostic donné ou d’un type d’examen spécifique.
Une nouvelle façon d’étiqueter chaque fichier et chaque personne
FAIR m-BIDS conserve l’apparence familière de BIDS, mais ajoute une couche de identifiants intelligents. Chaque fichier de données reçoit sa propre Clé Globale Unique d’Identité de fichier, ou clé de fichier, stable dans le temps et unique sur l’ensemble de la plateforme. Chaque participant reçoit une Clé Globale Unique de Sujet, ou clé de sujet, identique quelle que soit la multiplicité des études auxquelles il participe. Chaque collection de données obtient également une clé globale de jeu de données. Dans les coulisses, ces clés sont créées à l’aide de fonctions mathématiques fixes qui masquent les détails personnels tout en permettant aux systèmes autorisés de reconnaître lorsque différents fichiers appartiennent à une même personne anonymisée. Cet étiquetage fin permet aux chercheurs de rechercher, filtrer et regrouper des fichiers selon des descriptions riches sans rester enfermés dans la structure de dossiers d’origine.
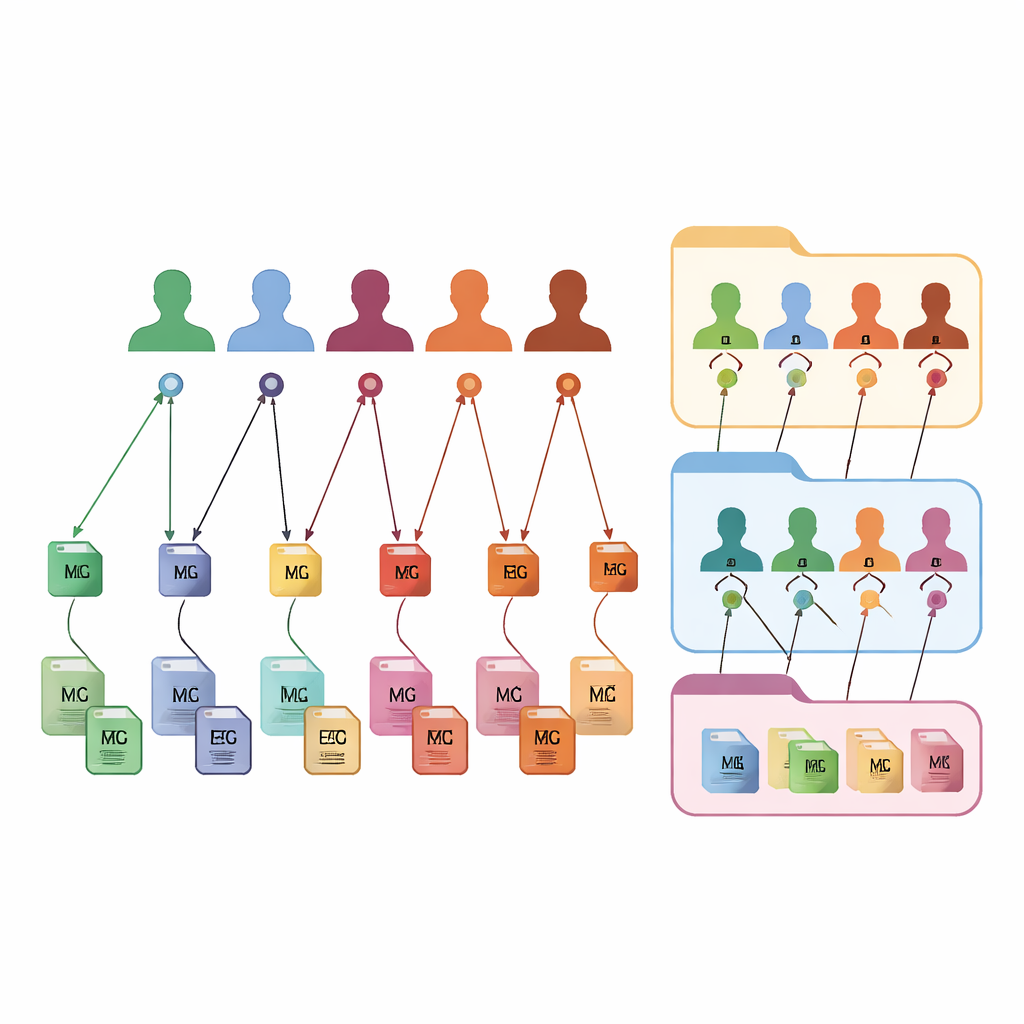
Construire des collections personnalisées à la demande
Parce que chaque fichier, sujet et jeu de données est lié par ces clés, FAIR m-BIDS transforme une archive statique en une biobanque flexible. Les scientifiques peuvent poser des requêtes détaillées au système : par exemple, « donnez-moi toutes les images cérébrales et enregistrements EEG de femmes âgées de 50 à 60 ans présentant des signes de perte de mémoire », et recevoir un paquet prêt à l’emploi couvrant plusieurs études d’origine. Le système peut enregistrer ces résultats de requête comme de nouveaux jeux de données, chacun avec sa propre clé de jeu de données mais toujours lié aux sources originales. Cela facilite la réalisation d’études multimodales à grande échelle, le suivi des mêmes personnes dans le temps, la comparaison de méthodes et la reproduction ou l’extension de travaux antérieurs. La structure a été testée sur des jeux de données publics et est actuellement déployée dans une biobanque nationale de cartographie cérébrale en Iran, où elle alimentera une plateforme en ligne d’exploration et d’analyse.
Garder les données utiles, connectées et sécurisées
En termes simples, les auteurs montrent comment l’ajout d’identifiants intelligents et préservant la confidentialité par-dessus des normes existantes peut transformer des dossiers cérébraux éparpillés en une bibliothèque bien organisée et consultable. FAIR m-BIDS cache les détails sensibles tout en permettant aux outils autorisés de relier fichiers, personnes et collections à travers de nombreuses études. Cela rend les données cérébrales plus faciles à trouver, combiner et réutiliser, aidant les chercheurs à construire des images plus riches de la santé et des maladies du cerveau et ouvrant la voie à une recherche en neurosciences plus fiable, collaborative et fondée sur les données.
Citation: Mirhosseini, S.M., Naseri, H., Siahlou, B. et al. FAIR m-BIDS: Advancing brain data utilization through multimodal and FAIR principles. Sci Data 13, 555 (2026). https://doi.org/10.1038/s41597-026-06790-7
Mots-clés: données cérébrales, neuroimagerie, normes de données, jeux de données multimodaux, principes FAIR