Clear Sky Science · pt
FAIR m-BIDS: Avançando a utilização de dados cerebrais por meio de princípios multimodais e FAIR
Por que organizar dados cerebrais importa
A pesquisa cerebral moderna produz um fluxo enorme de informações digitais: imagens do cérebro, registros elétricos, dados genéticos e até notas detalhadas sobre comportamento. No entanto, grande parte dessa informação está presa em formatos que são difíceis de buscar, combinar ou reutilizar. Este artigo apresenta o FAIR m-BIDS, uma nova forma de organizar dados cerebrais para que cientistas em qualquer lugar possam encontrar, conectar e reutilizar com mais facilidade e segurança informações de muitos tipos diferentes de estudos.
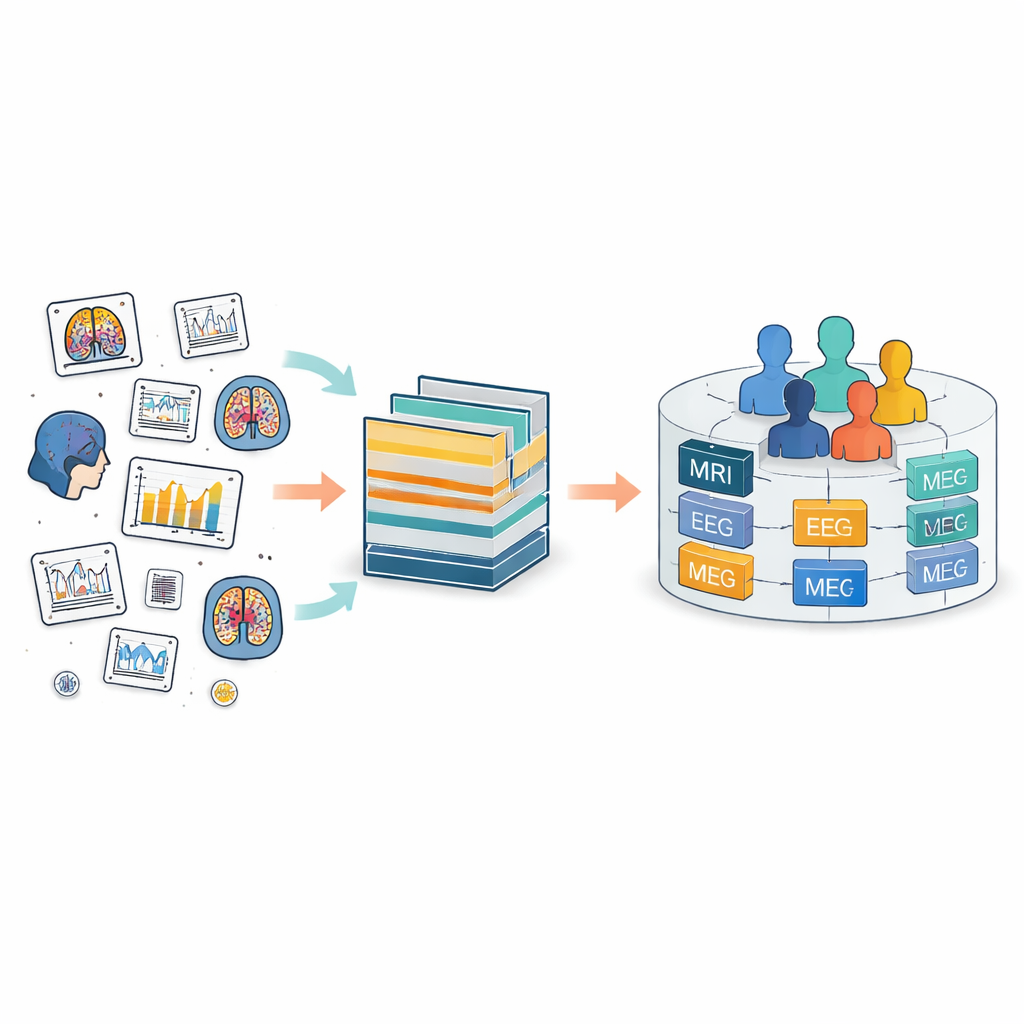
O problema dos registros cerebrais espalhados
Atualmente, dados cerebrais são coletados em todo o mundo usando muitas ferramentas, desde scanners de RM até capuzes de EEG e sensores de movimento. O Brain Imaging Data Structure (BIDS) foi criado para trazer ordem a esse caos, definindo estruturas de pastas e nomes de arquivos comuns. O BIDS foi ampliado para muitos tipos de medidas, mas ainda trata cada estudo como uma ilha separada. Dentro de cada ilha, pessoas e arquivos recebem rótulos locais próprios, que frequentemente não coincidem entre estudos. Isso torna difícil rastrear a mesma pessoa ao longo do tempo ou combinar diferentes tipos de medições dessa pessoa, como associar sua imagem cerebral à sua atividade elétrica e registros clínicos.
Regras FAIR para dados que outros podem usar
Ao mesmo tempo, muitos campos agora buscam seguir os princípios FAIR: os dados devem ser Encontráveis, Acessíveis, Interoperáveis e Reutilizáveis. Para a pesquisa cerebral, isso significa ser capaz de pesquisar através de muitas coleções, recuperar exatamente as partes necessárias, combinar diferentes tipos de dados sem atrito e fazer tudo isso respeitando a privacidade. O BIDS clássico foi projetado antes de os princípios FAIR serem formalmente definidos, portanto não suporta totalmente esses objetivos. Por exemplo, é simples navegar por um único conjunto de dados, mas é difícil pesquisar em vários conjuntos por todas as gravações de um determinado grupo etário, diagnóstico ou tipo de exame.
Uma nova forma de marcar cada arquivo e cada pessoa
O FAIR m-BIDS mantém a aparência e sensação familiares do BIDS, mas adiciona uma nova camada de identificadores inteligentes. Cada arquivo de dados recebe sua própria Chave Global Única de Identificação de Arquivo, ou file key, que é estável ao longo do tempo e única em toda a plataforma. Cada participante recebe uma Chave Global Única de Sujeito, ou subject key, que é a mesma não importa em quantos estudos ele participe. Cada coleção de dados também recebe uma chave global de conjunto de dados. Nos bastidores, essas chaves são criadas usando funções matemáticas fixas que ocultam detalhes pessoais ao mesmo tempo que permitem a sistemas aprovados reconhecer quando arquivos diferentes pertencem à mesma pessoa anônima. Essa etiquetagem detalhada permite que os pesquisadores busquem, filtrem e reagrupem arquivos com base em descrições ricas sem ficarem presos à estrutura de pastas original.
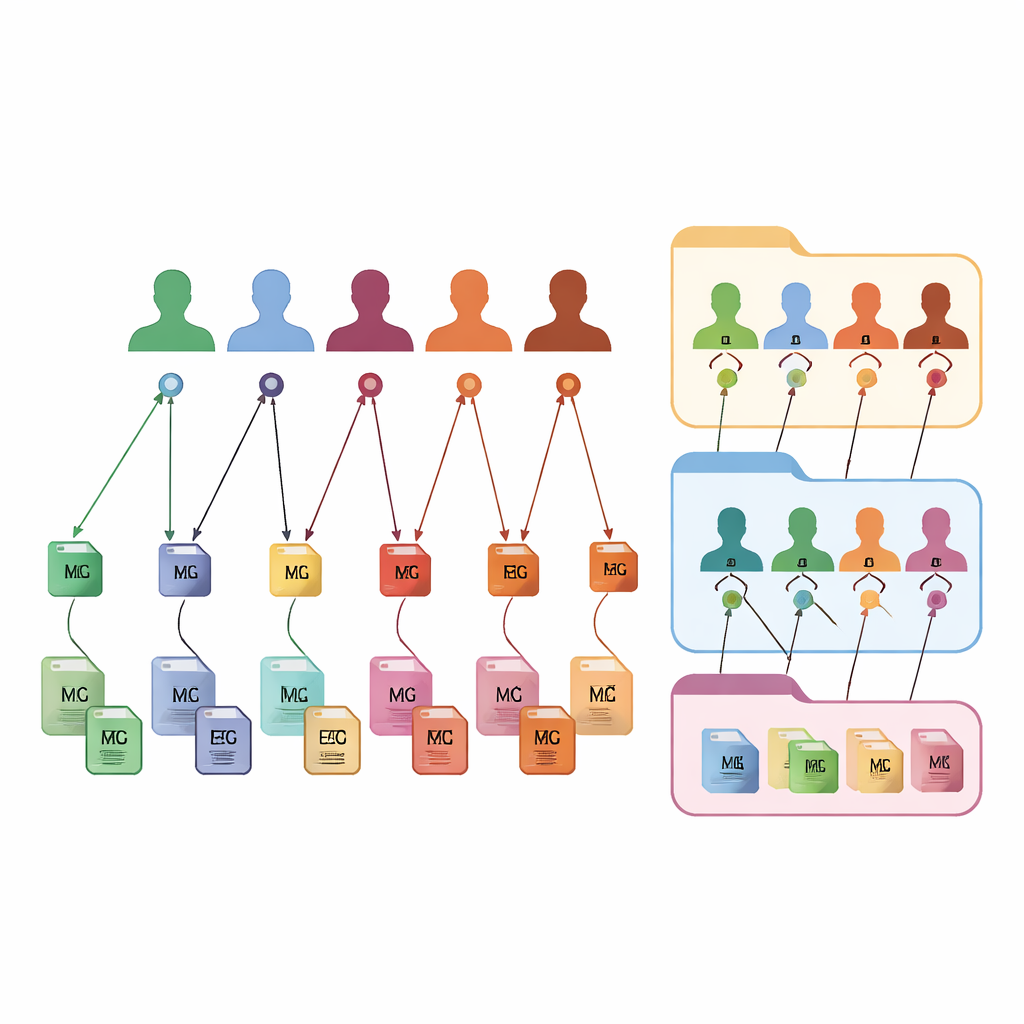
Construindo coleções customizadas sob demanda
Porque cada arquivo, sujeito e conjunto de dados está conectado por essas chaves, o FAIR m-BIDS transforma um arquivo estático em um biobanco flexível. Cientistas podem fazer perguntas detalhadas ao sistema: por exemplo, “me dê todas as imagens cerebrais e gravações de EEG de mulheres de 50–60 anos com sinais de perda de memória”, e receber um pacote pronto que abrange múltiplos estudos originais. O sistema pode salvar esses resultados de consulta como novos conjuntos de dados, cada um com sua própria chave de conjunto de dados, mas ainda vinculado às fontes originais. Isso facilita conduzir grandes estudos multimodais, acompanhar as mesmas pessoas ao longo do tempo, comparar métodos e reproduzir ou ampliar trabalhos anteriores. A estrutura foi testada em conjuntos de dados públicos e está sendo implementada em um biobanco nacional de mapeamento cerebral no Irã, onde alimentará uma plataforma online para exploração e análise.
Manter os dados úteis, conectados e seguros
De forma simples, os autores mostram como adicionar IDs inteligentes e que preservam a privacidade sobre padrões existentes pode transformar registros cerebrais espalhados em uma biblioteca bem organizada e pesquisável. O FAIR m-BIDS mantém detalhes sensíveis ocultos enquanto permite que ferramentas aprovadas vinculem arquivos, pessoas e coleções através de muitos estudos. Isso torna os dados cerebrais mais fáceis de encontrar, combinar e reutilizar, ajudando pesquisadores a construir quadros mais ricos sobre saúde e doença do cérebro e abrindo caminho para uma neurociência mais confiável, colaborativa e orientada por dados.
Citação: Mirhosseini, S.M., Naseri, H., Siahlou, B. et al. FAIR m-BIDS: Advancing brain data utilization through multimodal and FAIR principles. Sci Data 13, 555 (2026). https://doi.org/10.1038/s41597-026-06790-7
Palavras-chave: dados cerebrais, neuroimagem, padrões de dados, conjuntos de dados multimodais, princípios FAIR