Clear Sky Science · de
FAIR m-BIDS: Förderung der Nutzung von Hirndaten durch multimodale und FAIR-Prinzipien
Warum die Organisation von Hirndaten zählt
Die moderne Hirnforschung erzeugt einen Strom digitaler Informationen: Gehirnscans, elektrische Aufzeichnungen, genetische Daten und sogar detaillierte Verhaltensprotokolle. Vieles davon ist jedoch in Formaten eingeschlossen, die schwer zu durchsuchen, zu verbinden oder wiederzuverwenden sind. Dieser Beitrag stellt FAIR m-BIDS vor, eine neue Methode zur Organisation von Hirndaten, damit Forschende überall leichter Informationen aus vielen verschiedenen Studien finden, verknüpfen und sicher wiederverwenden können.
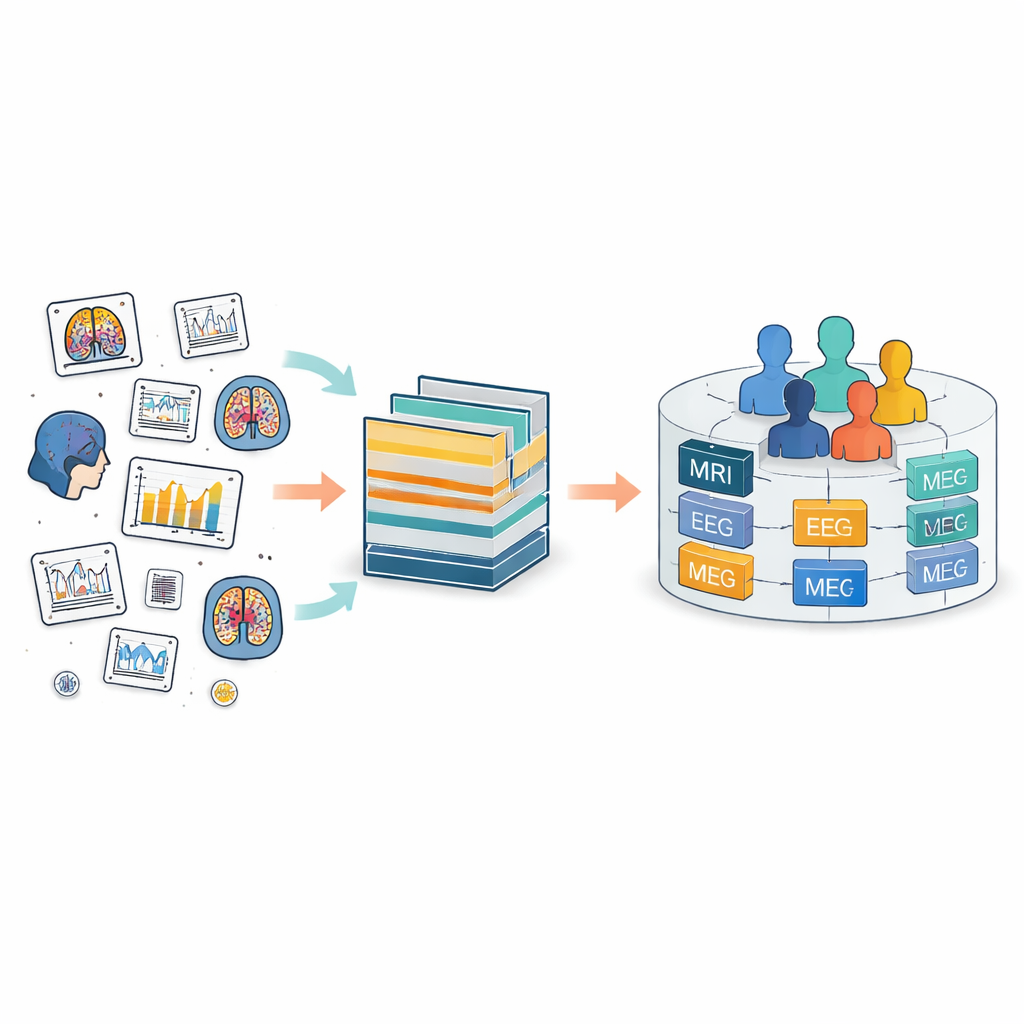
Das Problem verstreuter Hirnaufzeichnungen
Heute werden Hirndaten weltweit mit vielen verschiedenen Geräten erhoben, vom MRT-Scanner über EEG-Kappen bis zu Bewegungssensoren. Die Brain Imaging Data Structure (BIDS) wurde geschaffen, um in dieses Chaos Ordnung zu bringen, indem gemeinsame Ordnerstrukturen und Dateinamen definiert werden. BIDS wurde auf viele Messarten ausgeweitet, behandelt jedoch jede Studie weiterhin als eigene Insel. Innerhalb jeder Insel erhalten Personen und Dateien lokale Bezeichnungen, die oft zwischen Studien nicht übereinstimmen. Das erschwert es, dieselbe Person über die Zeit hinweg zu verfolgen oder verschiedene Messarten von dieser Person zu kombinieren, etwa ihren Hirnscan mit ihren elektrischen Aufzeichnungen und klinischen Daten abzugleichen.
Faire Regeln für wiederverwendbare Daten
Zugleich streben viele Forschungsbereiche inzwischen die FAIR-Prinzipien an: Daten sollen Findable (auffindbar), Accessible (zugänglich), Interoperable (interoperabel) und Reusable (wiederverwendbar) sein. Für die Hirnforschung bedeutet das, über viele Sammlungen hinweg suchen zu können, genau die benötigten Teile abzurufen, verschiedene Datentypen nahtlos zu kombinieren und das alles unter Wahrung des Datenschutzes. Das klassische BIDS wurde vor der formalen Definition von FAIR entwickelt und unterstützt diese Ziele nicht vollständig. So ist es etwa einfach, einen einzelnen Datensatz zu durchsuchen, aber schwierig, über viele Datensätze hinweg nach allen Aufnahmen einer bestimmten Altersgruppe, Diagnose oder Scanart zu suchen.
Eine neue Methode, jede Datei und jede Person zu kennzeichnen
FAIR m-BIDS behält das vertraute Erscheinungsbild von BIDS bei, ergänzt es jedoch um eine neue Ebene intelligenter Kennzeichen. Jede Datendatei erhält einen eigenen Global Unique Identifier Key, oder Dateischlüssel, der über die Zeit stabil und plattformweit eindeutig ist. Jede Teilnehmerin und jeder Teilnehmer bekommt einen Global Unique Subject Identifier, oder Subjektschlüssel, der gleich bleibt, egal an wie vielen Studien sie teilgenommen haben. Auch jede Datensammlung erhält einen globalen Datensatzschlüssel. Im Hintergrund werden diese Schlüssel mit festen mathematischen Funktionen erzeugt, die persönliche Details verschleiern, while zugleich autorisierten Systemen ermöglichen zu erkennen, wenn verschiedene Dateien derselben anonymen Person zuzuordnen sind. Diese feinmaschige Kennzeichnung erlaubt es Forschenden, Dateien anhand reichhaltiger Beschreibungen zu suchen, zu filtern und neu zu gruppieren, ohne an die ursprüngliche Ordnerstruktur gebunden zu sein.
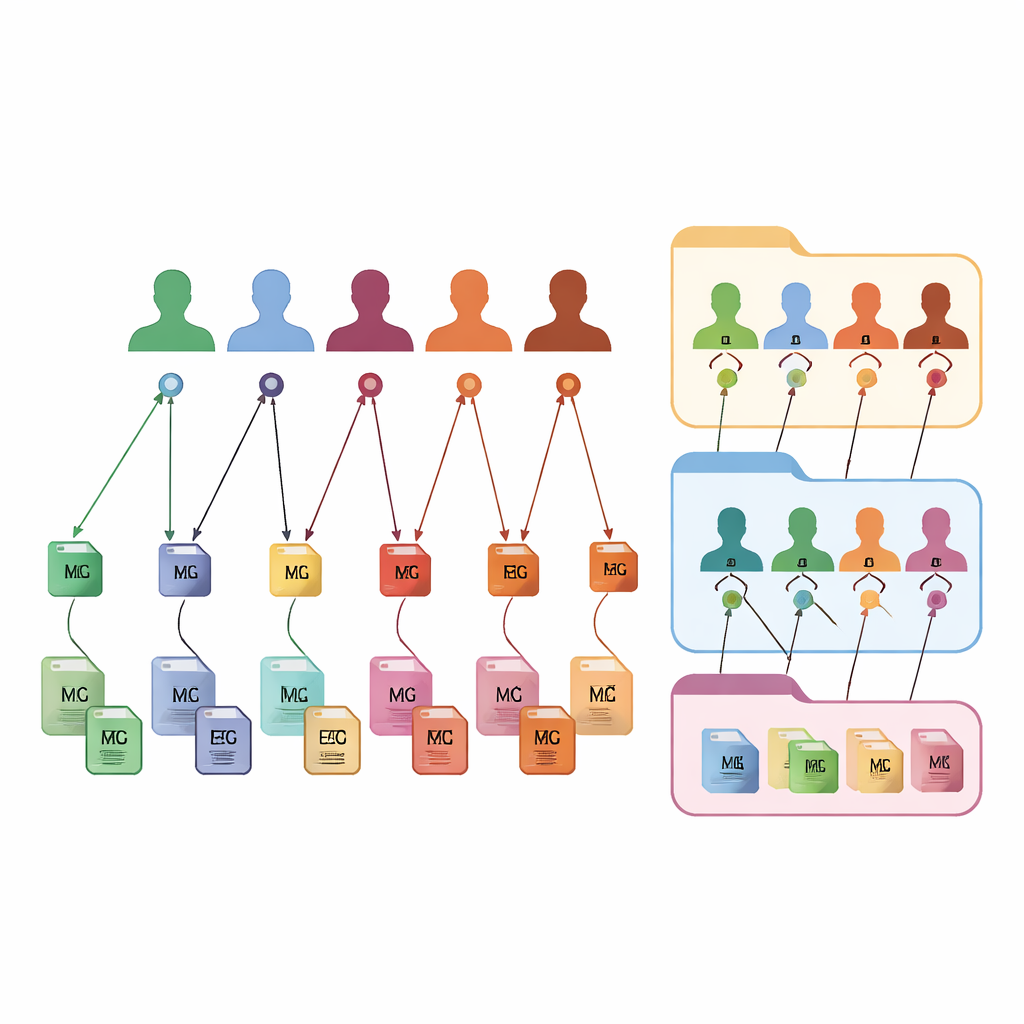
Auf Abruf maßgeschneiderte Sammlungen erstellen
Weil jede Datei, jede Person und jeder Datensatz durch diese Schlüssel verknüpft ist, verwandelt FAIR m-BIDS ein statisches Archiv in eine flexible Biobank. Forschende können detaillierte Anfragen an das System stellen: zum Beispiel „gib mir alle Gehirnscans und EEG-Aufzeichnungen von Frauen im Alter von 50–60 Jahren mit Anzeichen von Gedächtnisstörungen“, und erhalten ein fertiges Paket, das sich über mehrere ursprüngliche Studien erstreckt. Das System kann diese Abfrageergebnisse als neue Datensätze speichern, jeweils mit eigenem Datensatzschlüssel, der jedoch weiterhin auf die Originalquellen rückverweisbar ist. Das erleichtert große multimodale Studien, das Verfolgen derselben Personen über die Zeit, den Vergleich von Methoden sowie das Replizieren oder Erweitern früherer Arbeiten. Die Struktur wurde an öffentlichen Datensätzen getestet und wird derzeit in einer nationalen Hirnkartierungs-Biobank im Iran eingeführt, wo sie eine Onlineplattform für Exploration und Analyse antreiben wird.
Daten nützlich, vernetzt und sicher halten
Einfache gesagt zeigen die Autorinnen und Autoren, wie das Hinzufügen intelligenter, datenschutzwahrender IDs auf bestehenden Standards verstreute Hirnaufzeichnungen in eine gut organisierte, durchsuchbare Bibliothek verwandeln kann. FAIR m-BIDS hält sensible Details verborgen, erlaubt es jedoch autorisierten Werkzeugen, Dateien, Personen und Sammlungen über viele Studien hinweg zu verknüpfen. Das macht Hirndaten leichter auffindbar, kombinierbar und wiederverwendbar und hilft Forschenden, umfassendere Bilder von Gehirngesundheit und -krankheit zu erstellen und den Weg für zuverlässigere, kollaborative und datengetriebene Neurowissenschaften zu ebnen.
Zitation: Mirhosseini, S.M., Naseri, H., Siahlou, B. et al. FAIR m-BIDS: Advancing brain data utilization through multimodal and FAIR principles. Sci Data 13, 555 (2026). https://doi.org/10.1038/s41597-026-06790-7
Schlüsselwörter: Hirndaten, Neuroimaging, Datenstandards, multimodale Datensätze, FAIR-Prinzipien