Clear Sky Science · en
FAIR m-BIDS: Advancing brain data utilization through multimodal and FAIR principles
Why organizing brain data matters
Modern brain research produces a flood of digital information: brain scans, electrical recordings, genetic data, and even detailed notes on behavior. Yet much of this information is locked away in formats that are hard to search, combine, or reuse. This paper introduces FAIR m-BIDS, a new way to organize brain data so that scientists anywhere can more easily find, connect, and safely reuse information from many different types of studies.
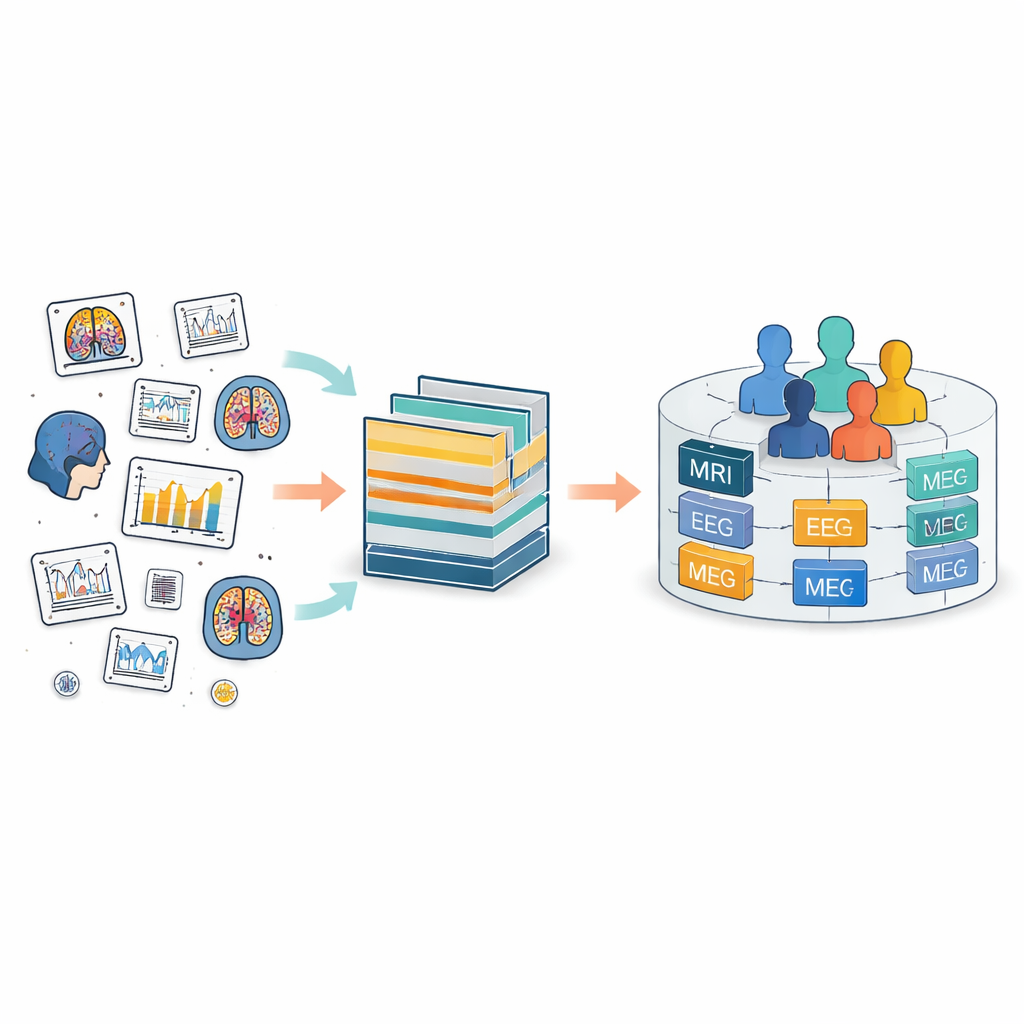
The problem of scattered brain records
Today, brain data are collected all over the world using many tools, from MRI scanners to EEG caps to motion sensors. The Brain Imaging Data Structure (BIDS) was created to bring order to this chaos by defining common folder layouts and file names. BIDS has been extended to many kinds of measurements, but it still treats each study as a separate island. Within each island, people and files get their own local labels, which often do not match across studies. That makes it hard to track the same person through time, or to combine different types of measurements from that person, such as matching their brain scan with their electrical activity and clinical records.
Fair rules for data that others can use
At the same time, many fields now aim to follow the FAIR principles: data should be Findable, Accessible, Interoperable, and Reusable. For brain research, this means being able to search across many collections, retrieve exactly the pieces needed, combine different data types smoothly, and do all of this while respecting privacy. Classic BIDS was designed before FAIR was formally defined, so it does not fully support these goals. For example, it is easy to browse a single dataset, but difficult to search across many datasets for all recordings from a particular age group, diagnosis, or type of scan.
A new way to tag every file and every person
FAIR m-BIDS keeps the familiar look and feel of BIDS, but adds a new layer of smart identifiers. Each data file receives its own Global Unique Identifier Key, or file key, that is stable over time and unique across the whole platform. Each participant receives a Global Unique Subject Identifier, or subject key, that is the same no matter how many studies they take part in. Each collection of data also gets a global dataset key. Behind the scenes, these keys are created using fixed mathematical functions that hide personal details while still allowing approved systems to recognize when different files belong to the same anonymous person. This fine-grained tagging lets researchers search, filter, and regroup files based on rich descriptions without being trapped inside the original folder structure.
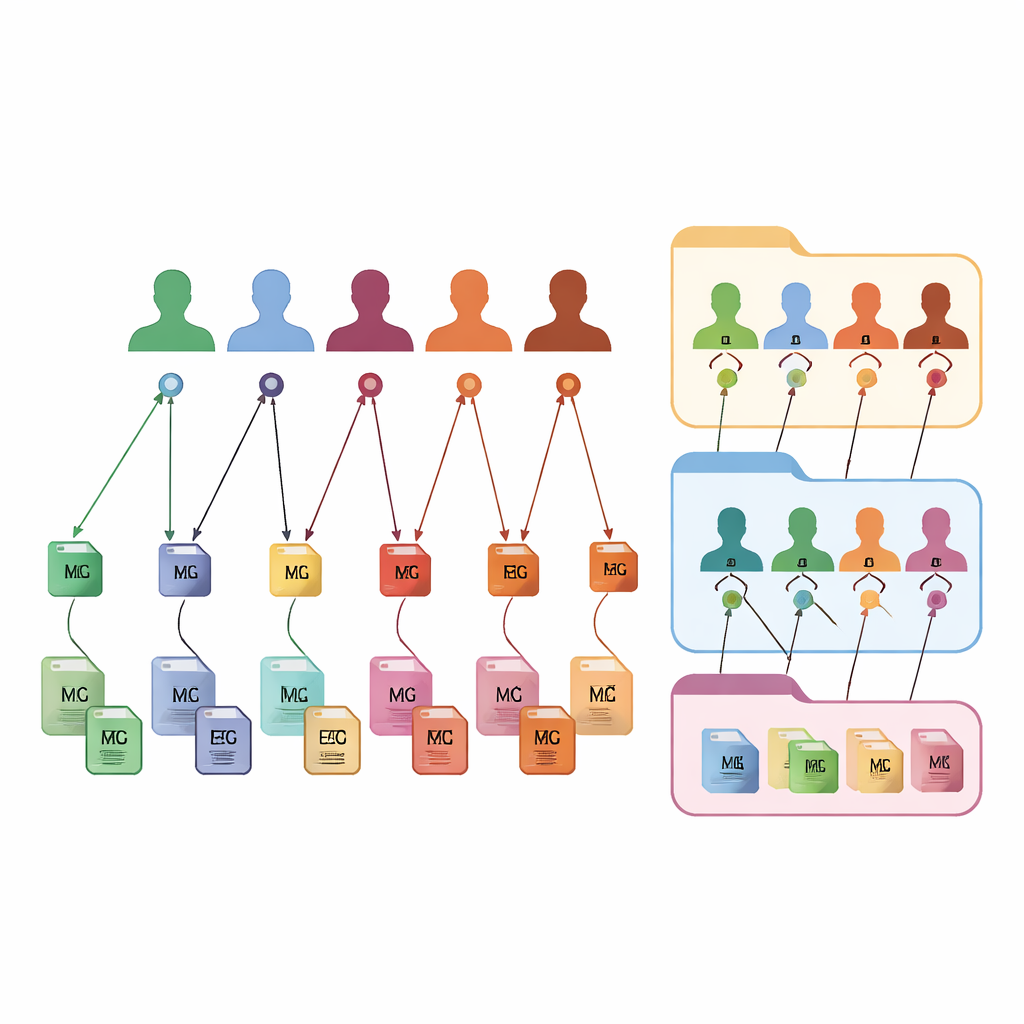
Building custom collections on demand
Because every file, subject, and dataset is linked through these keys, FAIR m-BIDS turns a static archive into a flexible biobank. Scientists can pose detailed questions to the system: for example, “give me all brain scans and EEG recordings from women aged 50–60 with signs of memory loss,” and receive a ready-made package that spans multiple original studies. The system can save these query results as new datasets, each with its own dataset key but still tied back to the original sources. This makes it easier to run large multimodal studies, follow the same people over time, compare methods, and repeat or extend previous work. The structure has been tested on public datasets and is being rolled out in a national brain mapping biobank in Iran, where it will power an online platform for exploration and analysis.
Keeping data useful, connected, and safe
In simple terms, the authors show how adding smart, privacy-preserving IDs on top of existing standards can turn scattered brain records into a well-organized, searchable library. FAIR m-BIDS keeps sensitive details hidden while letting approved tools link files, people, and collections across many studies. This makes brain data easier to find, combine, and reuse, helping researchers build richer pictures of brain health and disease and paving the way for more reliable, collaborative, and data-driven neuroscience.
Citation: Mirhosseini, S.M., Naseri, H., Siahlou, B. et al. FAIR m-BIDS: Advancing brain data utilization through multimodal and FAIR principles. Sci Data 13, 555 (2026). https://doi.org/10.1038/s41597-026-06790-7
Keywords: brain data, neuroimaging, data standards, multimodal datasets, FAIR principles