Clear Sky Science · pl
FAIR m-BIDS: Usprawnianie wykorzystania danych o mózgu przez zasady multimodalne i FAIR
Dlaczego porządkowanie danych o mózgu ma znaczenie
Współczesne badania nad mózgiem generują lawinę informacji cyfrowych: skany mózgu, zapisy elektryczne, dane genetyczne, a nawet szczegółowe obserwacje zachowania. Jednak wiele z tych danych jest zamkniętych w formatach trudnych do przeszukiwania, łączenia czy ponownego wykorzystania. Artykuł przedstawia FAIR m-BIDS — nowy sposób organizacji danych o mózgu, który umożliwia naukowcom na całym świecie łatwiejsze odnajdywanie, łączenie i bezpieczne ponowne użycie informacji pochodzących z różnych typów badań.
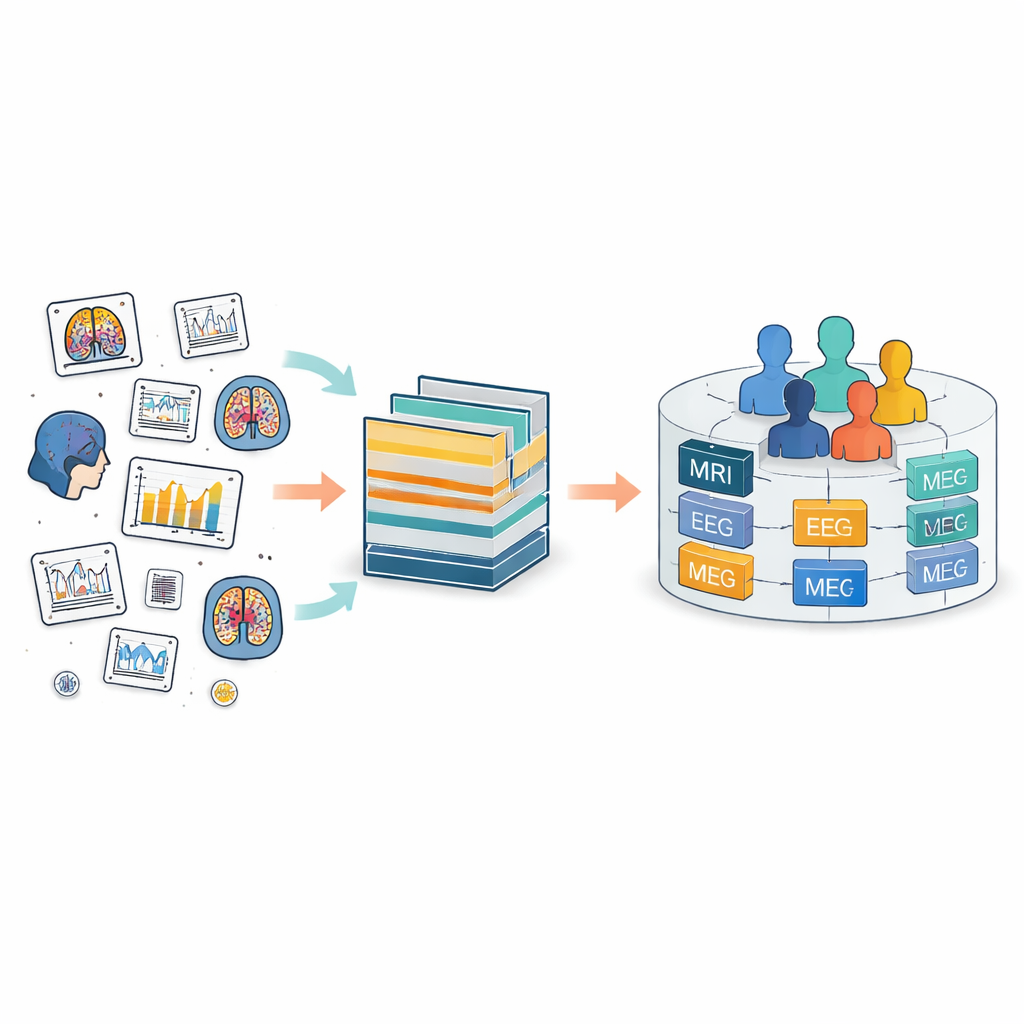
Problem rozproszonych zapisów o mózgu
Obecnie dane o mózgu zbierane są na całym świecie przy użyciu wielu narzędzi — od skanerów MRI, przez czepki EEG, po czujniki ruchu. Brain Imaging Data Structure (BIDS) powstał, by wprowadzić porządek w tym chaosie, definiując wspólne układy folderów i nazewnictwo plików. BIDS został rozszerzony o wiele rodzajów pomiarów, ale wciąż traktuje każde badanie jak osobną wyspę. W obrębie tych wysp ludzie i pliki otrzymują lokalne etykiety, które często nie pokrywają się między badaniami. Utrudnia to śledzenie tej samej osoby w czasie lub łączenie różnych rodzajów pomiarów tej osoby, na przykład dopasowanie skanu mózgu do zapisów aktywności elektrycznej i dokumentacji klinicznej.
Sprawiedliwe zasady dla danych, z których inni mogą korzystać
Jednocześnie wiele dziedzin dąży dziś do stosowania zasad FAIR: dane powinny być Findable (odnalezione), Accessible (dostępne), Interoperable (interoperacyjne) i Reusable (ponownie używalne). W badaniach nad mózgiem oznacza to możliwość przeszukiwania wielu kolekcji, pobierania dokładnie potrzebnych fragmentów, płynnego łączenia różnych typów danych i robienia tego wszystkiego z poszanowaniem prywatności. Klasyczny BIDS powstał zanim zasady FAIR zostały formalnie zdefiniowane, więc nie wspiera w pełni tych celów. Na przykład łatwo jest przeglądać pojedynczy zestaw danych, ale trudniej wyszukać w wielu zestawach wszystkie nagrania z konkretnej grupy wiekowej, rozpoznaniem czy typu skanu.
Nowy sposób oznaczania każdego pliku i każdej osoby
FAIR m-BIDS zachowuje znany wygląd i strukturę BIDS, ale dodaje warstwę inteligentnych identyfikatorów. Każdy plik danych otrzymuje swój Globalny Unikalny Klucz Pliku — file key, który jest stabilny w czasie i unikalny w całej platformie. Każdy uczestnik otrzymuje Globalny Unikalny Identyfikator Osoby — subject key, który pozostaje taki sam niezależnie od liczby badań, w których bierze udział. Każda kolekcja danych także otrzymuje globalny klucz dataset key. Za kulisami te klucze są tworzone za pomocą deterministycznych funkcji matematycznych, które ukrywają szczegóły osobowe, jednocześnie pozwalając zatwierdzonym systemom rozpoznać, kiedy różne pliki należą do tej samej anonimowej osoby. Tak drobiazgowe tagowanie pozwala badaczom wyszukiwać, filtrować i grupować pliki na podstawie bogatych opisów bez utknięcia w oryginalnej strukturze folderów.
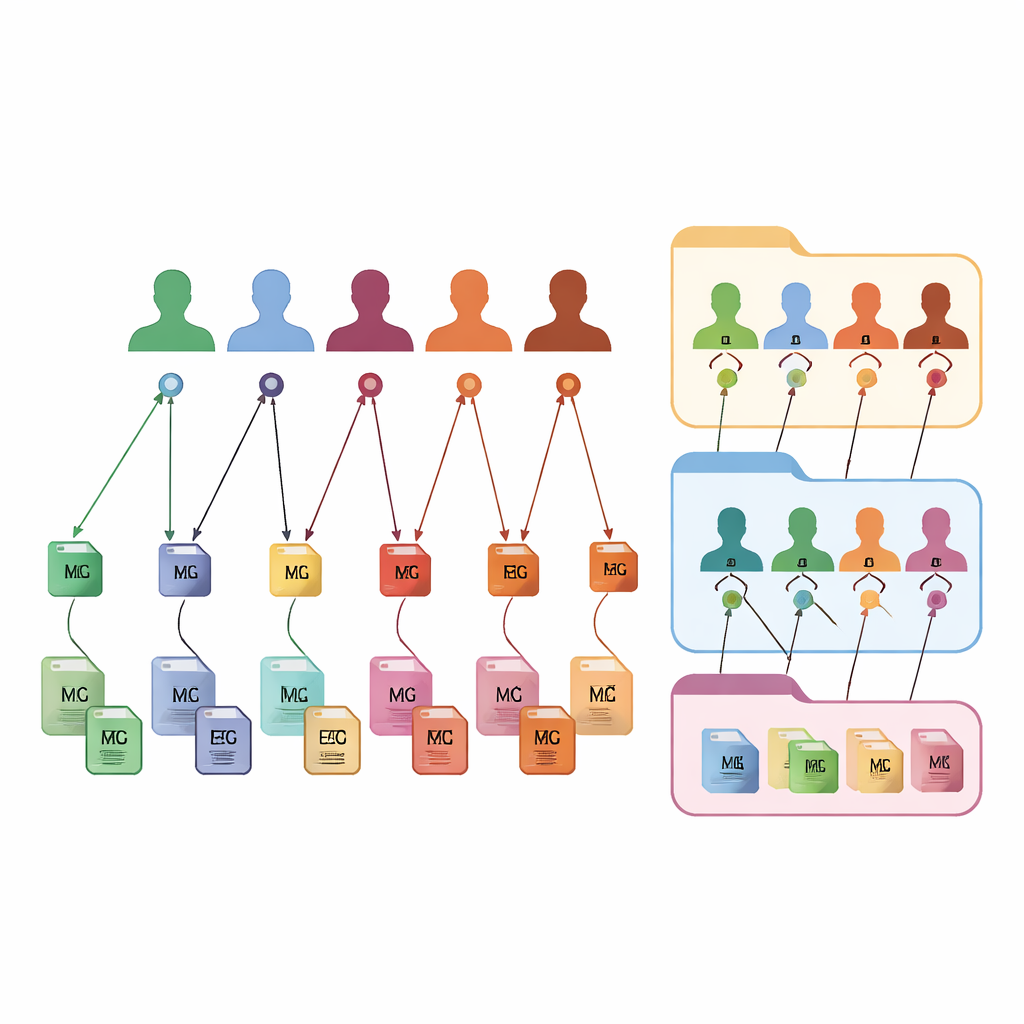
Tworzenie niestandardowych kolekcji na żądanie
Dzięki powiązaniu każdego pliku, uczestnika i zestawu danych przez te klucze, FAIR m-BIDS przekształca statyczne archiwum w elastyczny biobank. Naukowcy mogą zadawać systemowi szczegółowe zapytania, na przykład: „podaj wszystkie skany mózgu i zapisy EEG u kobiet w wieku 50–60 lat z objawami utraty pamięci”, i otrzymać gotowy pakiet obejmujący wiele pierwotnych badań. System może zapisać wyniki takich zapytań jako nowe zestawy danych, każdy z własnym kluczem dataset key, ale wciąż powiązany z oryginalnymi źródłami. Ułatwia to prowadzenie dużych badań multimodalnych, śledzenie tych samych osób w czasie, porównywanie metod oraz powtarzanie i rozszerzanie wcześniejszych prac. Struktura została przetestowana na publicznych zestawach danych i jest wdrażana w krajowym biobanku mapowania mózgu w Iranie, gdzie zasili platformę online do eksploracji i analizy.
Utrzymywanie danych użytecznych, powiązanych i bezpiecznych
Mówiąc prosto, autorzy pokazują, jak dodanie inteligentnych, chroniących prywatność identyfikatorów na istniejących standardach może przekształcić rozproszone zapisy o mózgu w dobrze zorganizowaną, przeszukiwalną bibliotekę. FAIR m-BIDS ukrywa wrażliwe szczegóły, jednocześnie pozwalając zatwierdzonym narzędziom łączyć pliki, osoby i kolekcje między wieloma badaniami. To ułatwia odnajdywanie, łączenie i ponowne wykorzystywanie danych o mózgu, pomagając naukowcom budować pełniejsze obrazy zdrowia i chorób mózgu oraz torując drogę do bardziej wiarygodnej, współpracującej i opartej na danych neuronauki.
Cytowanie: Mirhosseini, S.M., Naseri, H., Siahlou, B. et al. FAIR m-BIDS: Advancing brain data utilization through multimodal and FAIR principles. Sci Data 13, 555 (2026). https://doi.org/10.1038/s41597-026-06790-7
Słowa kluczowe: dane o mózgu, neuroobrazowanie, standardy danych, zbiory multimodalne, zasady FAIR