Clear Sky Science · it
FAIR m-BIDS: avanzare l’utilizzo dei dati cerebrali tramite approcci multimodali e i principi FAIR
Perché organizzare i dati cerebrali è importante
La ricerca cerebrale moderna genera un flusso enorme di informazioni digitali: immagini cerebrali, registrazioni elettriche, dati genetici e perfino annotazioni dettagliate sul comportamento. Gran parte di queste informazioni però resta bloccata in formati difficili da cercare, combinare o riutilizzare. Questo articolo presenta FAIR m-BIDS, un nuovo modo di organizzare i dati cerebrali affinché i ricercatori di tutto il mondo possano trovare, collegare e riusare più facilmente e in modo sicuro le informazioni provenienti da molti tipi diversi di studi.
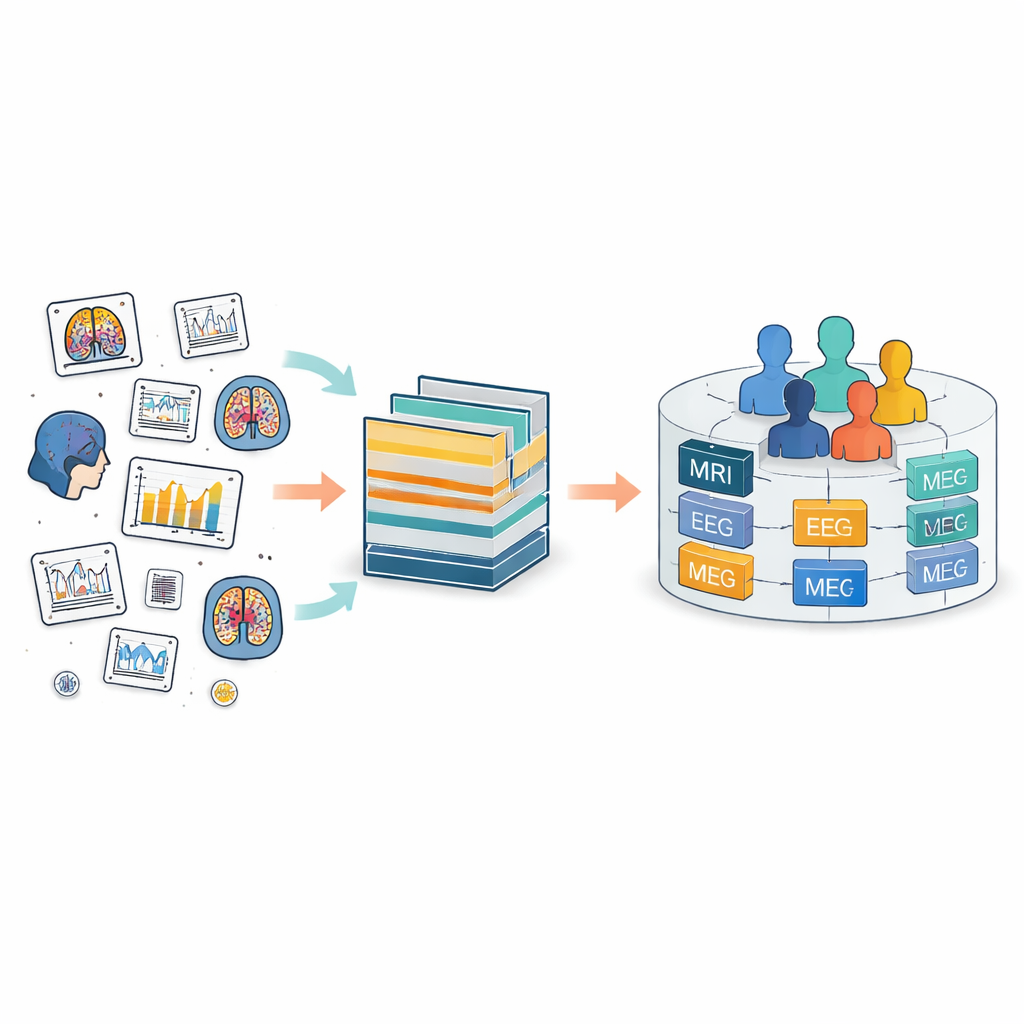
Il problema dei registri cerebrali sparsi
Oggi i dati cerebrali vengono raccolti in tutto il mondo con numerosi strumenti, dagli scanner MRI alle cuffie EEG fino ai sensori di movimento. Il Brain Imaging Data Structure (BIDS) è nato per mettere ordine in questo caos definendo disposizioni comuni di cartelle e convenzioni per i nomi dei file. BIDS è stato esteso a molte tipologie di misurazioni, ma continua a considerare ogni studio come un’isola separata. All’interno di ciascuna isola, persone e file ricevono etichette locali proprie, che spesso non corrispondono tra studi diversi. Questo rende difficile seguire la stessa persona nel tempo o combinare misurazioni diverse per quella persona, per esempio mettere in relazione la sua risonanza magnetica con l’attività elettrica e le cartelle cliniche.
Regole FAIR per dati che altri possono usare
Contemporaneamente, molti campi puntano ora a seguire i principi FAIR: i dati devono essere Findable (trovabili), Accessible (accessibili), Interoperable (interoperabili) e Reusable (riutilizzabili). Per la ricerca cerebrale questo significa poter cercare attraverso molte collezioni, recuperare esattamente i frammenti necessari, combinare fluidamente diversi tipi di dati e fare tutto ciò rispettando la privacy. Il BIDS classico è stato pensato prima della definizione formale dei principi FAIR, quindi non supporta pienamente questi obiettivi. Per esempio, è semplice esplorare un singolo dataset, ma è difficile cercare attraverso numerosi dataset tutte le registrazioni di un particolare gruppo di età, diagnosi o tipo di scansione.
Un nuovo modo per etichettare ogni file e ogni persona
FAIR m-BIDS mantiene l’aspetto familiare di BIDS, ma aggiunge un nuovo livello di identificatori intelligenti. Ogni file di dati riceve un Global Unique Identifier Key, o file key, che rimane stabile nel tempo e unico su tutta la piattaforma. Ogni partecipante ottiene un Global Unique Subject Identifier, o subject key, che è lo stesso indipendentemente da quanti studi a cui partecipa. Anche ogni raccolta di dati ottiene una dataset key globale. Dietro le quinte queste chiavi sono create usando funzioni matematiche fisse che nascondono i dettagli personali consentendo comunque ai sistemi autorizzati di riconoscere quando file diversi appartengono alla stessa persona anonima. Questa etichettatura granulare permette ai ricercatori di cercare, filtrare e raggruppare file basandosi su descrizioni ricche senza restare intrappolati nella struttura di cartelle originale.
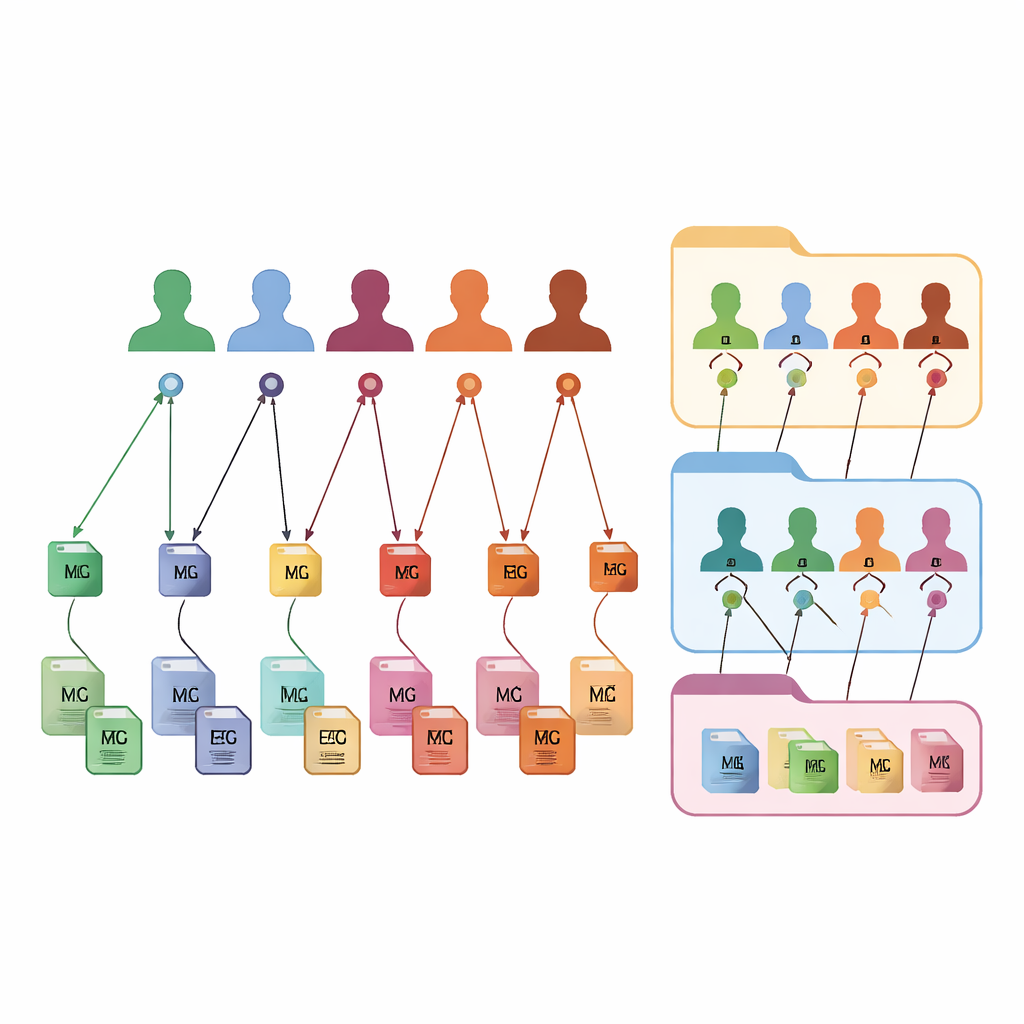
Costruire collezioni personalizzate su richiesta
Poiché ogni file, soggetto e dataset è collegato tramite queste chiavi, FAIR m-BIDS trasforma un archivio statico in una biobanca flessibile. I ricercatori possono porre al sistema domande dettagliate: per esempio, “dammi tutte le risonanze cerebrali e le registrazioni EEG di donne tra i 50 e i 60 anni con segni di perdita di memoria” e ricevere un pacchetto pronto all’uso che copre più studi originali. Il sistema può salvare i risultati di queste query come nuovi dataset, ognuno con la propria dataset key ma sempre riconducibile alle sorgenti originali. Questo facilita l’esecuzione di ampi studi multimodali, il monitoraggio delle stesse persone nel tempo, il confronto di metodi e la ripetizione o l’estensione di lavori precedenti. La struttura è stata testata su dataset pubblici ed è in fase di implementazione in una biobanca nazionale di mappatura cerebrale in Iran, dove alimenterà una piattaforma online per esplorazione e analisi.
Mantenere i dati utili, collegati e sicuri
In termini semplici, gli autori mostrano come aggiungere ID intelligenti che preservano la privacy sopra gli standard esistenti possa trasformare registri cerebrali sparsi in una biblioteca ben organizzata e ricercabile. FAIR m-BIDS mantiene nascosti i dettagli sensibili permettendo però agli strumenti autorizzati di collegare file, persone e collezioni attraverso molti studi. Questo rende i dati cerebrali più facili da trovare, combinare e riusare, aiutando i ricercatori a costruire quadro più ricchi sulla salute e le malattie del cervello e aprendo la strada a una neuroscienza più affidabile, collaborativa e guidata dai dati.
Citazione: Mirhosseini, S.M., Naseri, H., Siahlou, B. et al. FAIR m-BIDS: Advancing brain data utilization through multimodal and FAIR principles. Sci Data 13, 555 (2026). https://doi.org/10.1038/s41597-026-06790-7
Parole chiave: dati cerebrali, neuroimaging, standard per i dati, dataset multimodali, principi FAIR