Clear Sky Science · zh
遗传关联与机器学习提高1型糖尿病风险预测
为何基因对1型糖尿病重要
1型糖尿病常被认为是突然发作,尤其在儿童和青年中。但在表面之下,遗传DNA差异强烈影响谁更易患病。本研究展示了如何将超大规模的遗传数据与现代机器学习相结合,以提高我们评估风险的能力、区分1型糖尿病与其他类型的糖尿病,并发现可能需要不同治疗的隐性疾病亚型。
全基因组寻找风险线索
研究者首先扫描了超过80万名欧洲血统人的DNA,其中包括超过2万名1型糖尿病患者和近80万名无该病者。他们在全基因组中搜索在患者中更常见的微小DNA变异。这项工作证实了先前已知的89个与1型糖尿病相关的基因区,并发现了8个新的区域。这些区域中许多位于与免疫系统或胰腺产胰岛素细胞相关的基因附近,为理解疾病如何发生提供了新的切入点。
聚焦关键风险变体
在基因组中找到有风险的区只是开始,因为每个区域可能包含许多紧密连锁、共同出现的变体。团队使用精细定位方法,在主要免疫基因簇以外的97个区域以及位于第6号染色体的强大主要组织相容性复合体(MHC)处,缩小了最可能的致病变体范围。在超过一半的这些区域,他们将候选变体缩减到15个或更少,有时甚至缩减到单个最有可能的变体。他们还在MHC内部发现了新的风险信号,包括似乎在特定免疫细胞中改变基因调控的非编码变体,提示了更为具体的致病生物学路径。
教会模型“解读”遗传风险
基于这份精炼的变体清单,科学家构建了一种名为T1GRS的机器学习模型,将个体的基因组作为输入并输出反映其患1型糖尿病可能性的分数。 
隐藏的相互作用与遗传亚型
不同于简单地相加效应的风险评分,机器学习模型能够捕捉变体之间的相互作用。作者使用解释模型行为的工具,识别出154对变体,其组合对风险的影响强于或比单独效应更复杂。 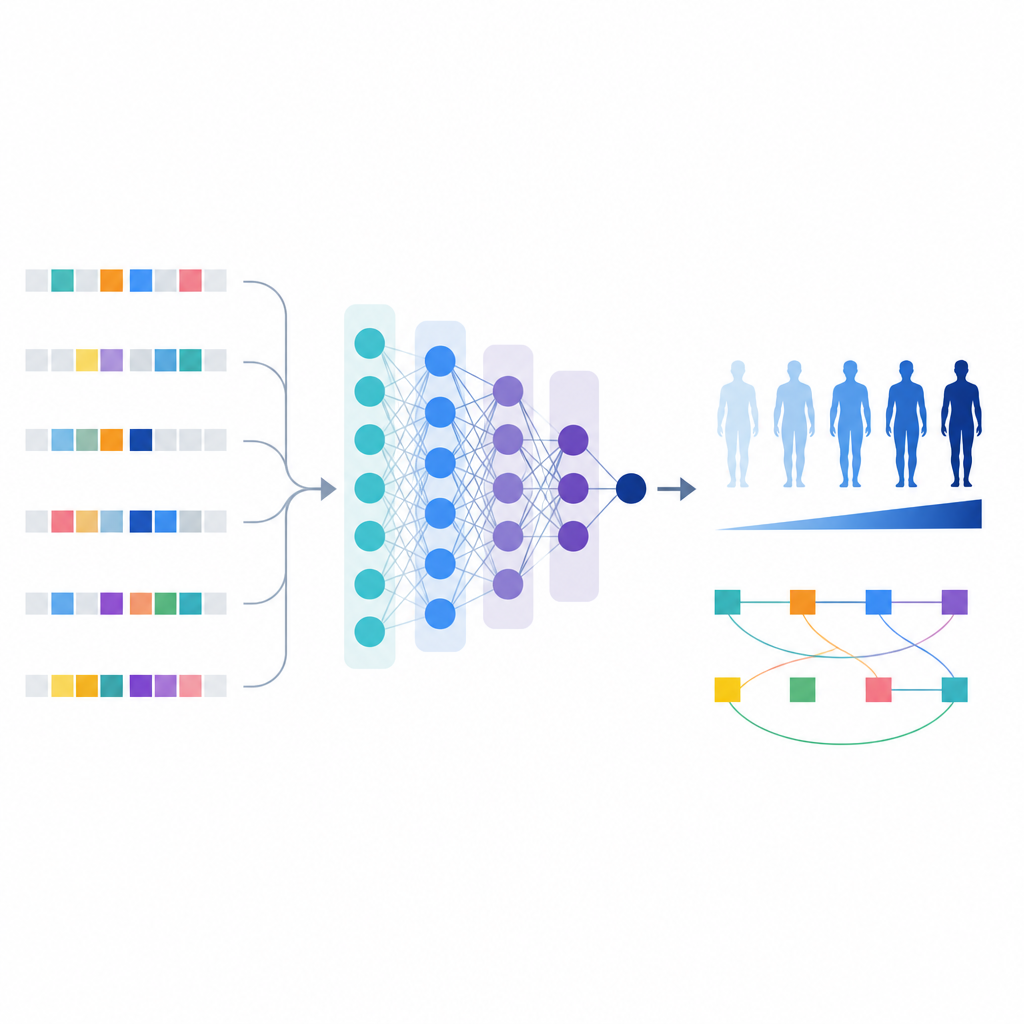
遗传模式对患者意味着什么
遗传亚簇与疾病进程的现实差异相关联。处于MHC驱动簇的人群倾向于更早发病。胰腺富集簇的人发病较晚,但并发症(如肾病、神经损伤和心血管问题)的发生率更高,尽管其平均血糖控制并不更差。独立数据集中也出现了类似模式,表明遗传信息可以帮助识别可能需要更密切并发症监测或对疗法反应不同的患者。
将遗传学引入日常医疗
总体而言,这项工作表明,经过精心构建的遗传风险模型可以不仅仅将人标为“高”或“低”风险。它改善了诊断,尤其对具有复杂遗传背景的人群有帮助,突出了值得在新疗法中针对的生物学通路,并指向在一生中表现不同的1型糖尿病不同形式。尽管单靠遗传学无法完全预测谁会发病,像T1GRS这样的工具让医学更接近使用简单的DNA检测来指导预防、诊断和长期管理。
引用: McGrail, C., Sears, T.J., Griffin, E.N. et al. Genetic association and machine learning improve the prediction of type 1 diabetes risk. Nat Genet 58, 1062–1072 (2026). https://doi.org/10.1038/s41588-026-02578-y
关键词: 1型糖尿病, 遗传风险评分, 机器学习, 自身免疫性疾病, 精准医学