Clear Sky Science · it
L’associazione genetica e l’apprendimento automatico migliorano la previsione del rischio di diabete di tipo 1
Perché i geni contano nel diabete di tipo 1
Il diabete di tipo 1 è spesso percepito come un evento improvviso, specialmente nei bambini e nei giovani adulti. Ma sotto la superficie, differenze ereditarie nel DNA influenzano fortemente chi è più a rischio. Questo studio mostra come la combinazione di dataset genetici molto ampi con tecniche moderne di apprendimento automatico possa affinare la nostra capacità di stimare quel rischio, distinguere il tipo 1 da altre forme di diabete e rivelare sottotipi nascosti della malattia che potrebbero richiedere cure diverse.
Cercare indizi di rischio in tutto il genoma
I ricercatori hanno prima esaminato il DNA di oltre 800.000 persone di ascendenza europea, incluse più di 20.000 con diabete di tipo 1 e quasi 800.000 senza. Hanno cercato in tutto il genoma piccole variazioni del DNA più frequenti nelle persone affette dalla malattia. Questo sforzo ha confermato 89 regioni genetiche già note associate al diabete di tipo 1 e ne ha individuate 8 di nuove. Molte di queste regioni si trovano vicino a geni coinvolti nel sistema immunitario o nelle cellule pancreatiche produttrici di insulina, offrendo nuovi punti di partenza per comprendere come si sviluppi la malattia.
Focalizzarsi sulle varianti di rischio chiave
Individuare una regione a rischio nel genoma è solo l’inizio, perché ogni regione può contenere molte varianti strettamente collegate che si ereditano insieme. Il team ha utilizzato metodi di mappatura fine per restringere le varianti più probabilmente causali in 97 regioni al di fuori del principale gruppo di geni immunitari e nel potente Complesso Maggiore di Istocompatibilità, o MHC, sul cromosoma 6. In più della metà di queste regioni sono riusciti a ridurre i candidati a 15 o meno varianti, e talvolta a un singolo sospetto principale. Hanno inoltre scoperto nuovi segnali di rischio all’interno dell’MHC, incluse varianti non codificanti che sembrano modificare la regolazione genica in specifiche cellule immunitarie, suggerendo percorsi biologici dettagliati verso la malattia.
Insegnare a un modello a leggere il rischio genetico
Con questa lista raffinata di varianti, gli scienziati hanno costruito un modello di apprendimento automatico chiamato T1GRS che considera il genoma di un individuo come input e restituisce un punteggio che riflette la probabilità di avere il diabete di tipo 1. 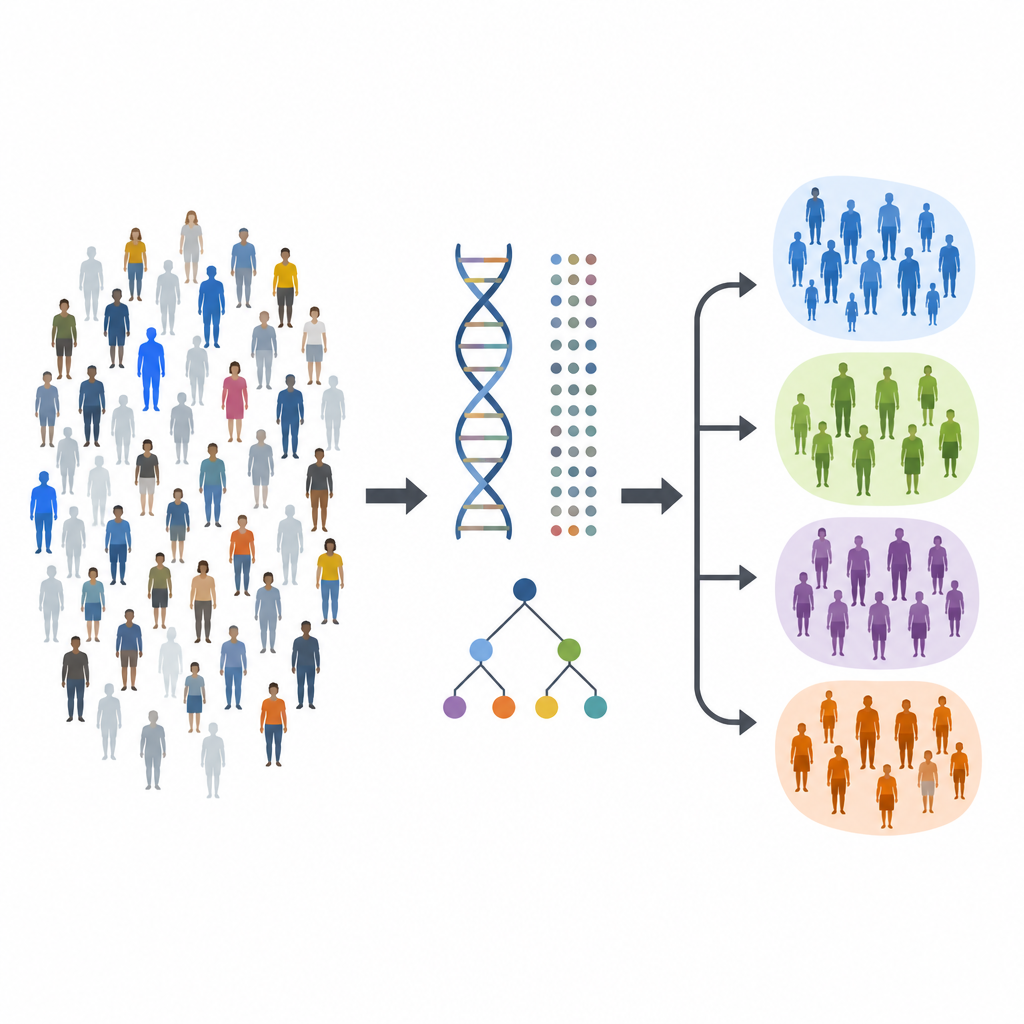
Interazioni nascoste e sottotipi genetici
A differenza dei semplici punteggi che sommano soltanto gli effetti, il modello di apprendimento automatico può catturare interazioni tra varianti. Gli autori hanno usato strumenti che spiegano il comportamento del modello per identificare 154 coppie di varianti il cui effetto combinato sul rischio era più forte o più complesso della semplice somma delle loro parti. 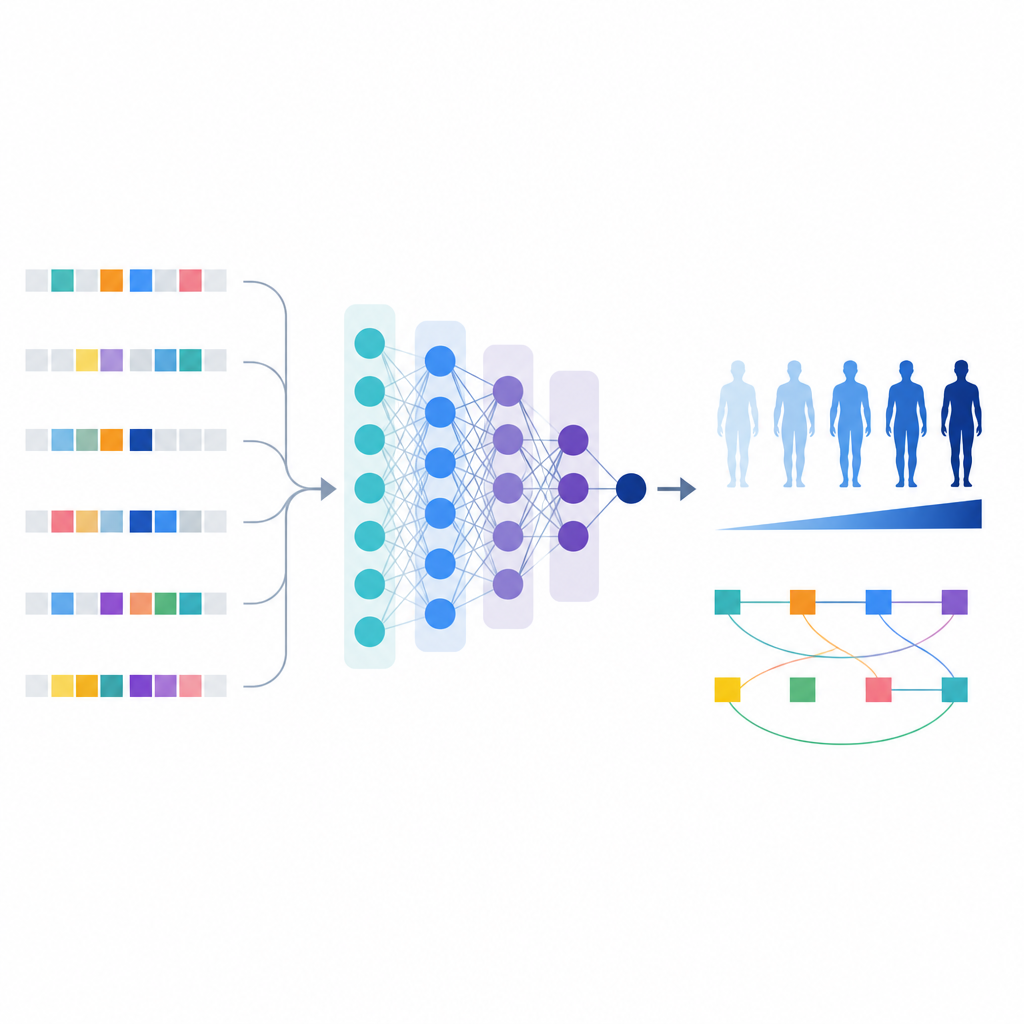
Cosa significano i modelli genetici per i pazienti
I sottocluster genetici erano collegati a differenze reali nel decorso della malattia. Le persone nei gruppi guidati dall’MHC tendevano a sviluppare il diabete di tipo 1 a età più giovani. Coloro nel cluster arricchito per geni pancreatici lo sviluppavano più tardi ma presentavano tassi più elevati di complicanze come malattia renale, danno nervoso e problemi cardiovascolari, nonostante il controllo glicemico medio non fosse peggiore. Schemi simili sono apparsi in un dataset indipendente, suggerendo che la genetica può aiutare a individuare pazienti che potrebbero necessitare di monitoraggio più attento per le complicanze o che potrebbero rispondere in modo diverso alle terapie.
Integrare la genetica nella cura quotidiana
In generale, questo lavoro mostra che un modello di rischio genetico costruito con cura può fare più che etichettare qualcuno come “alto” o “basso” rischio. Migliora la diagnosi, specialmente in persone con background genetici complessi, mette in evidenza percorsi biologici meritevoli di intervento per nuovi trattamenti e indica forme distinte di diabete di tipo 1 che si sviluppano in modo diverso nel corso della vita. Pur non potendo la sola genetica prevedere chi svilupperà la malattia, strumenti come T1GRS avvicinano la medicina all’uso di un semplice test del DNA per guidare prevenzione, diagnosi e gestione a lungo termine.
Citazione: McGrail, C., Sears, T.J., Griffin, E.N. et al. Genetic association and machine learning improve the prediction of type 1 diabetes risk. Nat Genet 58, 1062–1072 (2026). https://doi.org/10.1038/s41588-026-02578-y
Parole chiave: diabete di tipo 1, punteggio di rischio genetico, apprendimento automatico, malattia autoimmune, medicina di precisione