Clear Sky Science · pt
Associação genética e aprendizado de máquina melhoram a predição do risco de diabetes tipo 1
Por que os genes importam para o diabetes tipo 1
O diabetes tipo 1 costuma ser visto como algo que surge de forma inesperada, especialmente em crianças e adultos jovens. Mas, por baixo da superfície, diferenças hereditárias no DNA moldam fortemente quem tem maior risco. Este estudo mostra como combinar conjuntos de dados genéticos muito grandes com aprendizado de máquina moderno pode afinar nossa capacidade de estimar esse risco, separar o diabetes tipo 1 de outras formas de diabetes e descobrir subtipos ocultos da doença que podem exigir cuidados diferentes.
Procurando pistas de risco ao longo do genoma
Os pesquisadores primeiro analisaram o DNA de mais de 800.000 pessoas de ascendência europeia, incluindo mais de 20.000 com diabetes tipo 1 e quase 800.000 sem a doença. Eles vasculharam o genoma inteiro em busca de pequenas mudanças no DNA que eram mais comuns em pessoas com a doença. Esse esforço confirmou 89 regiões genéticas previamente conhecidas associadas ao diabetes tipo 1 e revelou 8 novas. Muitas dessas regiões ficam próximas a genes envolvidos no sistema imunológico ou nas células produtoras de insulina do pâncreas, oferecendo novos pontos de partida para entender como a doença se desenvolve.
Aproximando-se dos variantes de risco-chave
Encontrar uma região de risco no genoma é apenas o começo, porque cada região pode conter muitas variantes estreitamente ligadas que se deslocam juntas. A equipe usou métodos de mapeamento fino para reduzir as variantes causais mais prováveis em 97 regiões fora do principal aglomerado de genes imunológicos e no potente Complexo Principal de Histocompatibilidade, ou MHC, no cromossomo 6. Em mais da metade dessas regiões eles conseguiram reduzir os candidatos para 15 ou menos variantes, e às vezes para um único suspeito principal. Também descobriram novos sinais de risco dentro do MHC, incluindo variantes não codificantes que parecem alterar a regulação gênica em células imunes específicas, sugerindo rotas biológicas detalhadas para a doença.
Ensinando um modelo a ler o risco genético
Com essa lista refinada de variantes, os cientistas construíram um modelo de aprendizado de máquina chamado T1GRS que trata o genoma de um indivíduo como entrada e produz um escore refletindo sua probabilidade de ter diabetes tipo 1. 
Interações ocultas e subtipos genéticos
Diferente de escores simples de risco que apenas somam efeitos, o modelo de aprendizado de máquina pode capturar interações entre variantes. Os autores usaram ferramentas que explicam o comportamento do modelo para identificar 154 pares de variantes cujo efeito combinado sobre o risco era mais forte ou mais complexo do que a soma das partes. 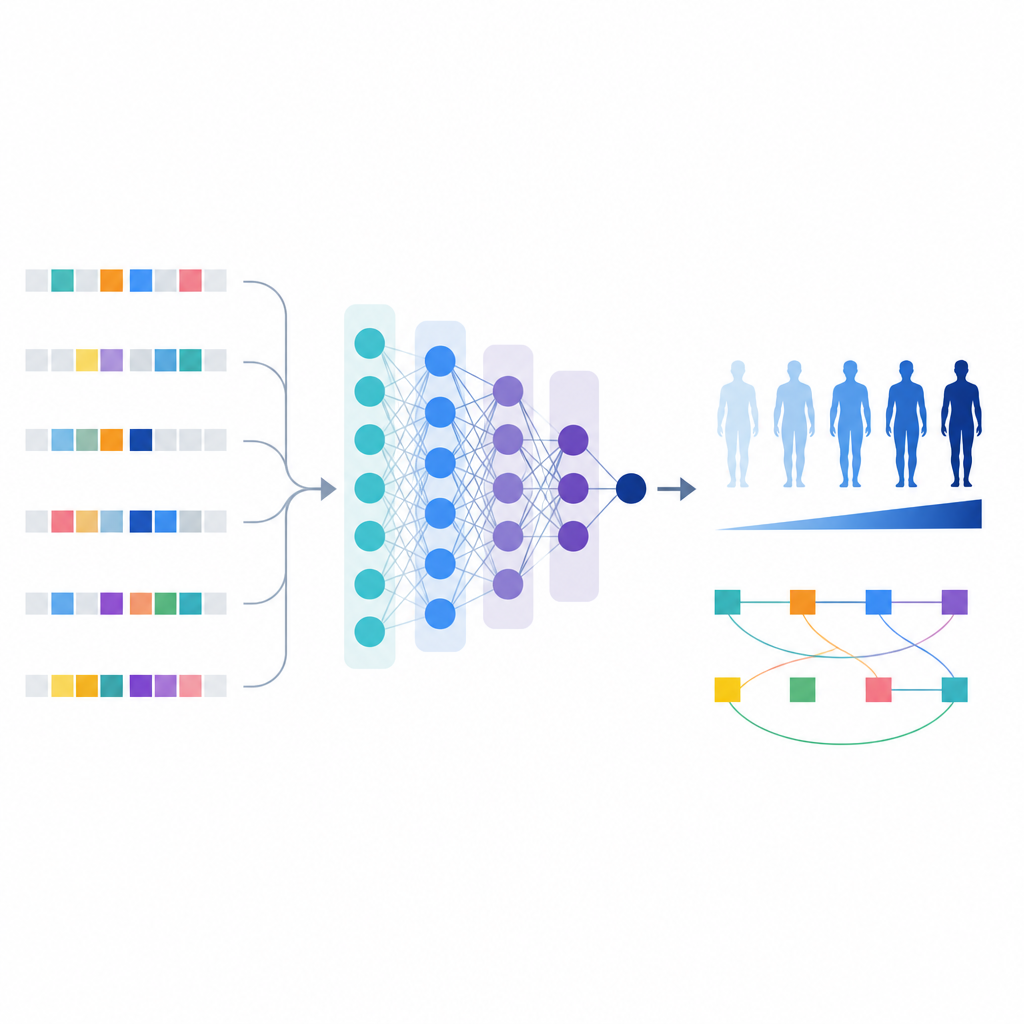
O que os padrões genéticos significam para os pacientes
Os subgrupos genéticos estiveram ligados a diferenças reais no curso da doença. Pessoas nos clusters dirigidos pelo MHC tenderam a desenvolver diabetes tipo 1 em idades mais jovens. Aqueles no cluster enriquecido para pâncreas desenvolveram a doença mais tarde, mas apresentaram taxas mais altas de complicações como doença renal, danos nervosos e problemas cardiovasculares, mesmo que seu controle médio da glicemia não fosse pior. Padrões semelhantes apareceram em um conjunto de dados independente, sugerindo que a genética pode ajudar a sinalizar pacientes que podem precisar de monitoramento mais próximo para complicações ou que podem responder de forma diferente a terapias.
Integrando a genética ao cuidado cotidiano
No geral, este trabalho mostra que um modelo de risco genético cuidadosamente construído pode fazer mais do que rotular alguém como "alto" ou "baixo" risco. Ele melhora o diagnóstico, especialmente em pessoas com antecedentes genéticos complexos, destaca vias biológicas que valem a pena serem alvo de novos tratamentos e aponta formas distintas de diabetes tipo 1 que se desenrolam de maneira diferente ao longo da vida. Embora a genética por si só não possa prever quem desenvolverá a doença, ferramentas como o T1GRS aproximam a medicina do uso de um simples teste de DNA para orientar prevenção, diagnóstico e manejo de longo prazo.
Citação: McGrail, C., Sears, T.J., Griffin, E.N. et al. Genetic association and machine learning improve the prediction of type 1 diabetes risk. Nat Genet 58, 1062–1072 (2026). https://doi.org/10.1038/s41588-026-02578-y
Palavras-chave: diabetes tipo 1, escore de risco genético, aprendizado de máquina, doença autoimune, medicina de precisão