Clear Sky Science · de
Genetische Assoziation und maschinelles Lernen verbessern die Vorhersage des Typ‑1‑Diabetesrisikos
Warum Gene für Typ‑1‑Diabetes wichtig sind
Typ‑1‑Diabetes wird oft als plötzlich auftretend wahrgenommen, besonders bei Kindern und jungen Erwachsenen. Unter der Oberfläche bestimmen jedoch vererbte Unterschiede in der DNA maßgeblich, wer das größte Risiko trägt. Diese Studie zeigt, wie die Kombination sehr großer genetischer Datensätze mit modernen Methoden des maschinellen Lernens unsere Fähigkeit verbessert, dieses Risiko einzuschätzen, Typ‑1‑Diabetes von anderen Diabetesformen zu unterscheiden und verborgene Subtypen der Erkrankung zu identifizieren, die möglicherweise unterschiedlicher Behandlung bedürfen.
Im gesamten Genom nach Risikohinweisen suchen
Die Forschenden untersuchten zunächst die DNA von mehr als 800.000 Personen europäischer Abstammung, darunter über 20.000 mit Typ‑1‑Diabetes und fast 800.000 ohne die Erkrankung. Sie durchsuchten das gesamte Genom nach winzigen DNA‑Veränderungen, die bei Erkrankten häufiger vorkamen. Dieser Aufwand bestätigte 89 zuvor bekannte genetische Regionen, die mit Typ‑1‑Diabetes in Verbindung stehen, und deckte 8 neue auf. Viele dieser Regionen liegen in der Nähe von Genen, die am Immunsystem oder an den insulinproduzierenden Zellen der Bauchspeicheldrüse beteiligt sind und bieten neue Ansatzpunkte, um zu verstehen, wie die Krankheit entsteht.
Aufschluss über wichtige Risiko‑Varianten
Eine riskante Region im Genom zu finden, ist nur der Anfang, denn jede Region kann viele eng gekoppelte Varianten enthalten, die gemeinsam auftreten. Das Team nutzte Fine‑Mapping‑Methoden, um die wahrscheinlichsten kausalen Varianten in 97 Regionen außerhalb des Hauptclusters der Immun‑Gene sowie im mächtigen Major‑Histokompatibilitätskomplex (MHC) auf Chromosom 6 einzugrenzen. In mehr als der Hälfte dieser Regionen konnten sie die Kandidaten auf 15 oder weniger Varianten reduzieren, manchmal sogar auf einen einzigen Hauptverdächtigen. Zudem entdeckten sie neue Risikosignale innerhalb des MHC, darunter nichtkodierende Varianten, die offenbar die Genregulation in spezifischen Immunzellen verändern und auf detaillierte biologische Wege zur Krankheitsentstehung hinweisen.
Dem Modell beibringen, genetisches Risiko zu lesen
Mit dieser verfeinerten Variantenauswahl bauten die Wissenschaftler ein Modell des maschinellen Lernens namens T1GRS, das das Genom einer Person als Eingabe nutzt und einen Score ausgibt, der ihre Wahrscheinlichkeit für Typ‑1‑Diabetes widerspiegelt. 
Verborgene Interaktionen und genetische Subtypen
Im Gegensatz zu einfachen Risikoscores, die Effekte nur addieren, kann das Modell des maschinellen Lernens Interaktionen zwischen Varianten erfassen. Die Autoren verwendeten Erklärungswerkzeuge, um das Modellverhalten zu interpretieren, und identifizierten 154 Variantepaare, deren kombinierter Einfluss auf das Risiko stärker oder komplexer war als die Summe ihrer Einzelwirkungen. 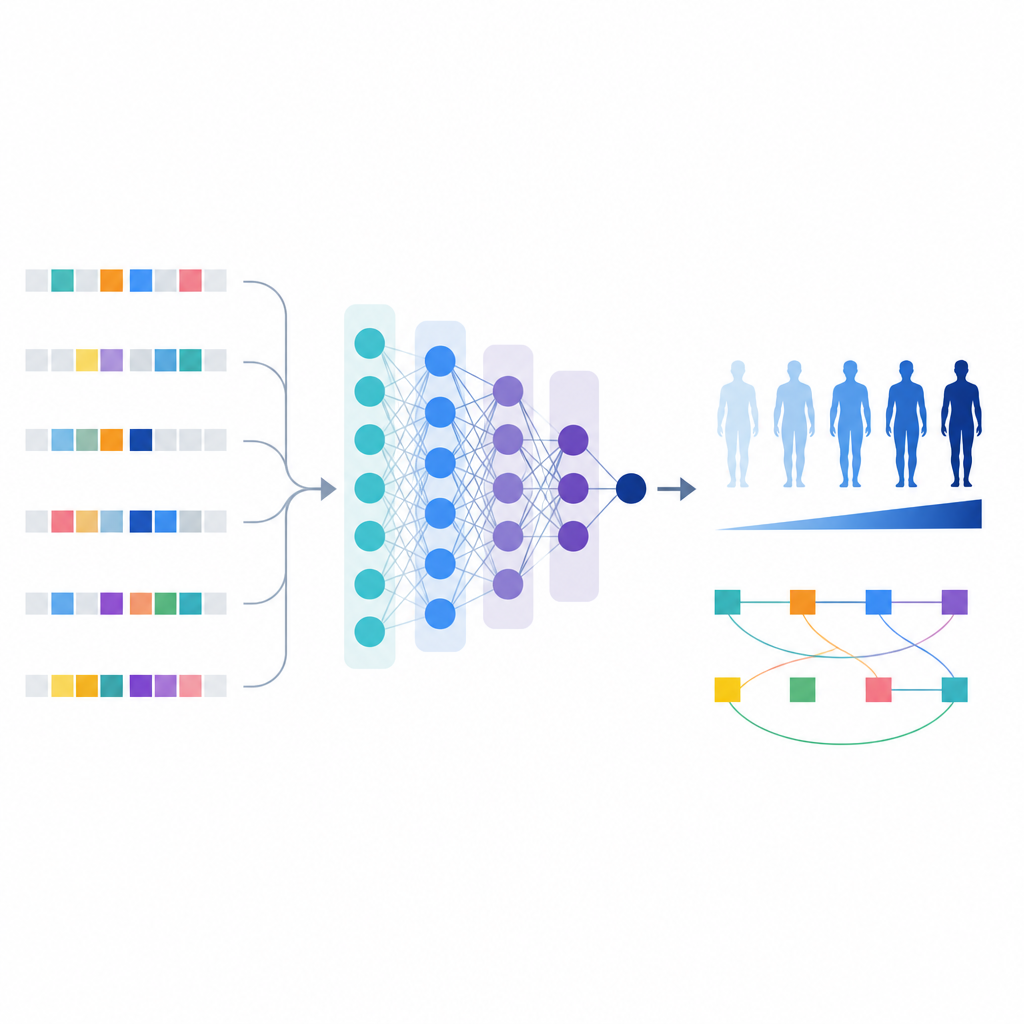
Was die genetischen Muster für Patientinnen und Patienten bedeuten
Die genetischen Subcluster standen in Verbindung mit realen Unterschieden im Krankheitsverlauf. Personen in den MHC‑getriebenen Clustern entwickelten den Typ‑1‑Diabetes tendenziell in jüngerem Alter. Diejenigen im pankreas‑angereicherten Cluster erkrankten später, hatten jedoch höhere Raten von Komplikationen wie Nierenleiden, Nervenschäden und kardiovaskulären Problemen, obwohl ihre durchschnittliche Blutzuckerkontrolle nicht schlechter war. Ähnliche Muster zeigten sich in einem unabhängigen Datensatz, was darauf hindeutet, dass Genetik helfen kann, Patientinnen und Patienten zu identifizieren, die engmaschiger überwacht werden sollten oder anders auf Therapien ansprechen könnten.
Genetik in die tägliche Versorgung bringen
Insgesamt zeigt diese Arbeit, dass ein sorgfältig entwickeltes genetisches Risikomodell mehr leisten kann als eine einfache Einordnung in „hoch“ oder „niedrig“. Es verbessert die Diagnose, insbesondere bei Menschen mit komplexer genetischer Ausstattung, hebt biologische Wege hervor, die sich für neue Therapien eignen, und weist auf unterschiedliche Formen des Typ‑1‑Diabetes hin, die sich im Laufe des Lebens verschieden entwickeln. Während Genetik allein nicht vorhersagen kann, wer die Erkrankung letztlich entwickelt, bringt T1GRS die Medizin näher an die Möglichkeit, mit einem einfachen DNA‑Test Prävention, Diagnose und Langzeitmanagement zu steuern.
Zitation: McGrail, C., Sears, T.J., Griffin, E.N. et al. Genetic association and machine learning improve the prediction of type 1 diabetes risk. Nat Genet 58, 1062–1072 (2026). https://doi.org/10.1038/s41588-026-02578-y
Schlüsselwörter: Typ‑1‑Diabetes, genetischer Risikoscore, maschinelles Lernen, Autoimmunerkrankung, präzisionsmedizin