Clear Sky Science · nl
Genetische associatie en machine learning verbeteren de voorspelling van het risico op type 1-diabetes
Waarom genen ertoe doen bij type 1-diabetes
Type 1-diabetes wordt vaak gezien als iets dat uit het niets toeslaat, vooral bij kinderen en jongvolwassenen. Maar onder de oppervlakte bepalen erfelijke verschillen in DNA sterk wie het meeste risico loopt. Deze studie laat zien hoe het combineren van zeer grote genetische datasets met moderne machine learning onze mogelijkheid verscherpt om dat risico te schatten, type 1 te onderscheiden van andere vormen van diabetes en verborgen subtypen van de ziekte te ontdekken die mogelijk verschillend behandeld moeten worden.
Het genoom afzoeken naar risicopunten
De onderzoekers hebben eerst het DNA van meer dan 800.000 mensen van Europese afkomst gescand, waaronder meer dan 20.000 met type 1-diabetes en bijna 800.000 zonder de aandoening. Ze doorzochten het hele genoom naar kleine DNA-veranderingen die vaker voorkwamen bij mensen met de ziekte. Deze inspanning bevestigde 89 eerder bekende genetische regio’s die met type 1-diabetes geassocieerd zijn en bracht 8 nieuwe regio’s aan het licht. Veel van deze regio’s liggen dicht bij genen die betrokken zijn bij het immuunsysteem of de insuline-producerende cellen van de alvleesklier, wat nieuwe aanknopingspunten biedt om te begrijpen hoe de ziekte ontstaat.
Inzoomen op sleutelvarianten
Het vinden van een risicovolle regio in het genoom is slechts het begin, omdat elke regio veel nauw verwante varianten kan bevatten die samen meekomen. Het team gebruikte fine-mapping-methoden om de meest waarschijnlijke causale varianten te vernauwen in 97 regio’s buiten het belangrijkste immuungenencluster en in het krachtige Major Histocompatibility Complex (MHC) op chromosoom 6. In meer dan de helft van deze regio’s konden ze de kandidaten terugbrengen tot 15 of minder varianten, en soms tot één leidende verdachte. Ze ontdekten ook nieuwe risicosignalen binnen het MHC, waaronder niet-coderende varianten die kennelijk de genregulatie in specifieke immuuncellen beïnvloeden, wat wijst op gedetailleerde biologische routes naar de ziekte.
Een model leren genetisch risico te lezen
Met deze verfijnde lijst van varianten bouwden de wetenschappers een machine learning-model genaamd T1GRS dat iemands genoom als invoer gebruikt en een score oplevert die hun waarschijnlijkheid om type 1-diabetes te hebben weerspiegelt. 
Verborgen interacties en genetische subtypes
In tegenstelling tot eenvoudige riskscores die effecten gewoon optellen, kan het machine learning-model interacties tussen varianten vastleggen. De auteurs gebruikten hulpmiddelen die modelgedrag verklaren om 154 paren van varianten te identificeren waarvan het gecombineerde effect op risico sterker of complexer was dan de som van de afzonderlijke effecten. 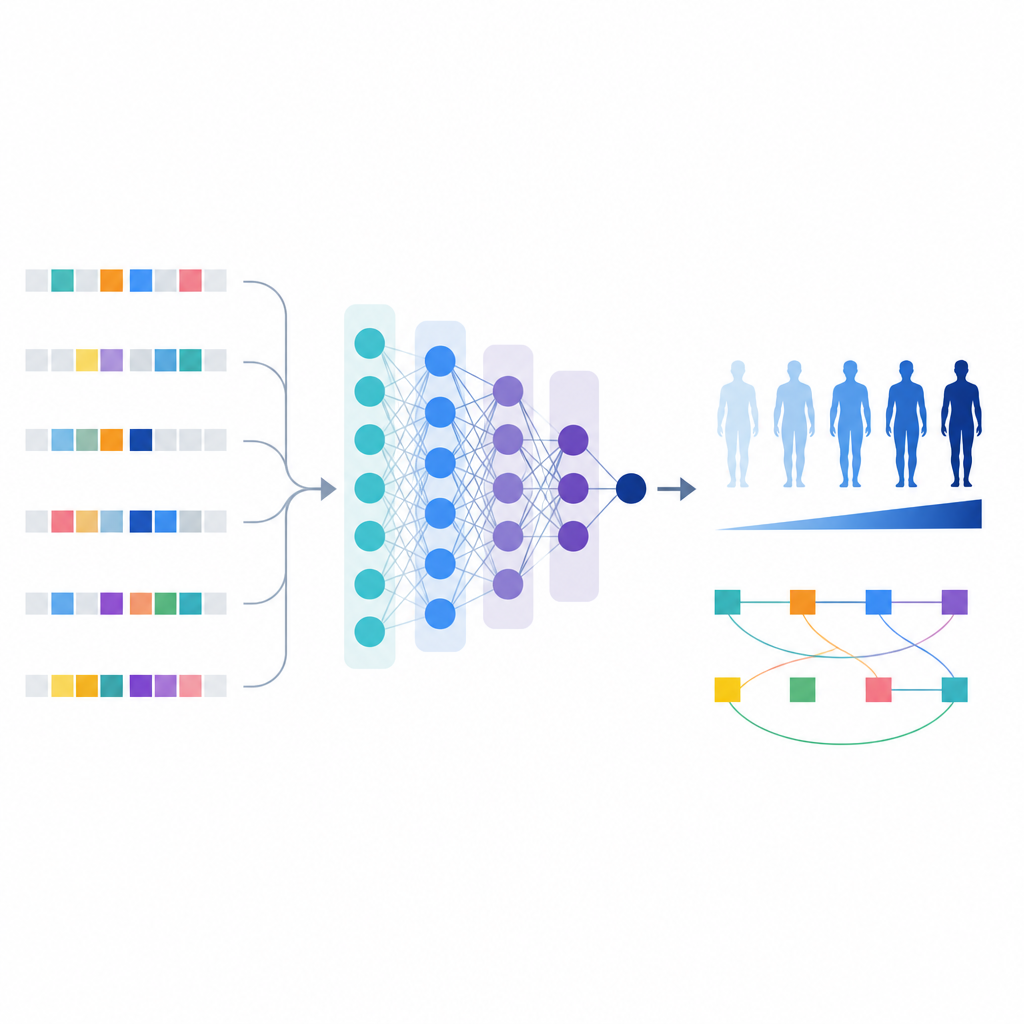
Wat de genetische patronen voor patiënten betekenen
De genetische subclusters waren gekoppeld aan reële verschillen in ziekteverloop. Mensen in de MHC-gedreven clusters ontwikkelden doorgaans op jongere leeftijd type 1-diabetes. Degenen in de pancreas-verrijkte cluster ontwikkelden de ziekte later maar hadden hogere percentages complicaties zoals nierziekte, zenuwschade en hart- en vaatproblemen, ook al was hun gemiddelde bloedglucosecontrole niet slechter. Vergelijkbare patronen verschenen in een onafhankelijk dataset, wat suggereert dat genetica kan helpen patiënten te signaleren die mogelijk intensiever gevolgd moeten worden op complicaties of die anders op behandelingen reageren.
Genetica naar de dagelijkse zorg brengen
Alles bij elkaar laat dit werk zien dat een zorgvuldig opgebouwd genetisch risicomodel meer kan doen dan iemand enkel als “hoog” of “laag” risico te labelen. Het verbetert de diagnose, vooral bij mensen met complexe genetische achtergronden, belicht biologische routes die het waard zijn om op te richten bij nieuwe behandelingen en wijst op verschillende vormen van type 1-diabetes die zich anders ontwikkelen gedurende het leven. Hoewel genetica op zichzelf niet kan voorspellen wie de ziekte zal krijgen, brengt gereedschap als T1GRS de geneeskunde dichter bij het gebruik van een eenvoudige DNA-test om preventie, diagnose en langetermijnbeheer te sturen.
Bronvermelding: McGrail, C., Sears, T.J., Griffin, E.N. et al. Genetic association and machine learning improve the prediction of type 1 diabetes risk. Nat Genet 58, 1062–1072 (2026). https://doi.org/10.1038/s41588-026-02578-y
Trefwoorden: type 1 diabetes, genetische risicoscore, machine learning, auto-immuunziekte, precisiemedicine