Clear Sky Science · sv
Genetiska associationer och maskininlärning förbättrar förutsägelsen av risk för typ 1-diabetes
Varför gener spelar roll för typ 1-diabetes
Typ 1-diabetes uppfattas ofta som något som inträffar plötsligt, särskilt hos barn och unga vuxna. Men under ytan formar ärftliga skillnader i DNA starkt vem som löper störst risk. Denna studie visar hur kombinationen av mycket stora genetiska datamängder och modern maskininlärning kan skärpa vår förmåga att uppskatta den risken, skilja typ 1 från andra former av diabetes och upptäcka dolda undertyper av sjukdomen som kan behöva olika vård.
Söker över genomet efter riskledtrådar
Forskarna skannade först DNA från mer än 800 000 personer med europeiskt ursprung, inklusive över 20 000 med typ 1-diabetes och nästan 800 000 utan sjukdomen. De sökte i hela genomet efter små DNA-förändringar som var vanligare hos personer med sjukdomen. Denna insats bekräftade 89 tidigare kända genetiska regioner kopplade till typ 1-diabetes och upptäckte 8 nya. Många av dessa regioner ligger nära gener som är involverade i immunsystemet eller de insulinproducerande cellerna i bukspottkörteln, vilket ger nya utgångspunkter för att förstå hur sjukdomen utvecklas.
Zooma in på viktiga riskvarianter
Att hitta en riskregion i genomet är bara början, eftersom varje region kan innehålla många tätt länkade varianter som förs vidare tillsammans. Teamet använde finmappningsmetoder för att begränsa de mest sannolika kausala varianterna vid 97 regioner utanför den stora immunogenklustret och vid det kraftfulla major histocompatibility complex (MHC) på kromosom 6. I mer än hälften av dessa regioner kunde de reducera kandidaterna till 15 eller färre varianter, och ibland till en enda huvudmisstänkt. De upptäckte också nya risksignaler inom MHC, inklusive icke-kodande varianter som verkar förändra genreglering i specifika immunceller, vilket antyder detaljerade biologiska vägar till sjukdomen.
Träna en modell att läsa genetisk risk
Med denna förfinade lista av varianter byggde forskarna en maskininlärningsmodell kallad T1GRS som behandlar en individs genom som indata och ger ut en poäng som återspeglar sannolikheten för att ha typ 1-diabetes. 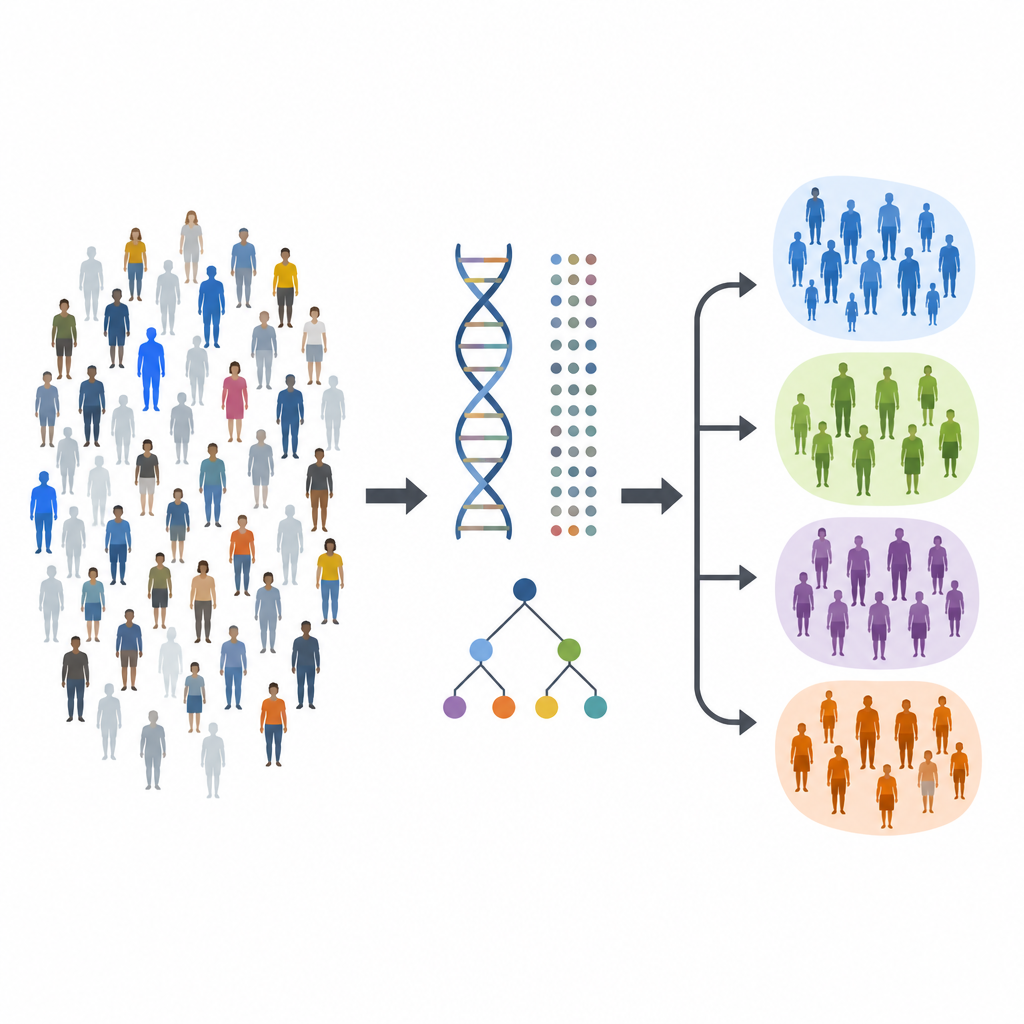
Dolda interaktioner och genetiska undertyper
Till skillnad från enkla riskscorer som bara adderar effekter kan maskininlärningsmodellen fånga interaktioner mellan varianter. Författarna använde verktyg som förklarar modellbeteende för att identifiera 154 par av varianter vars kombinerade effekt på risken var starkare eller mer komplex än summan av deras enskilda effekter. 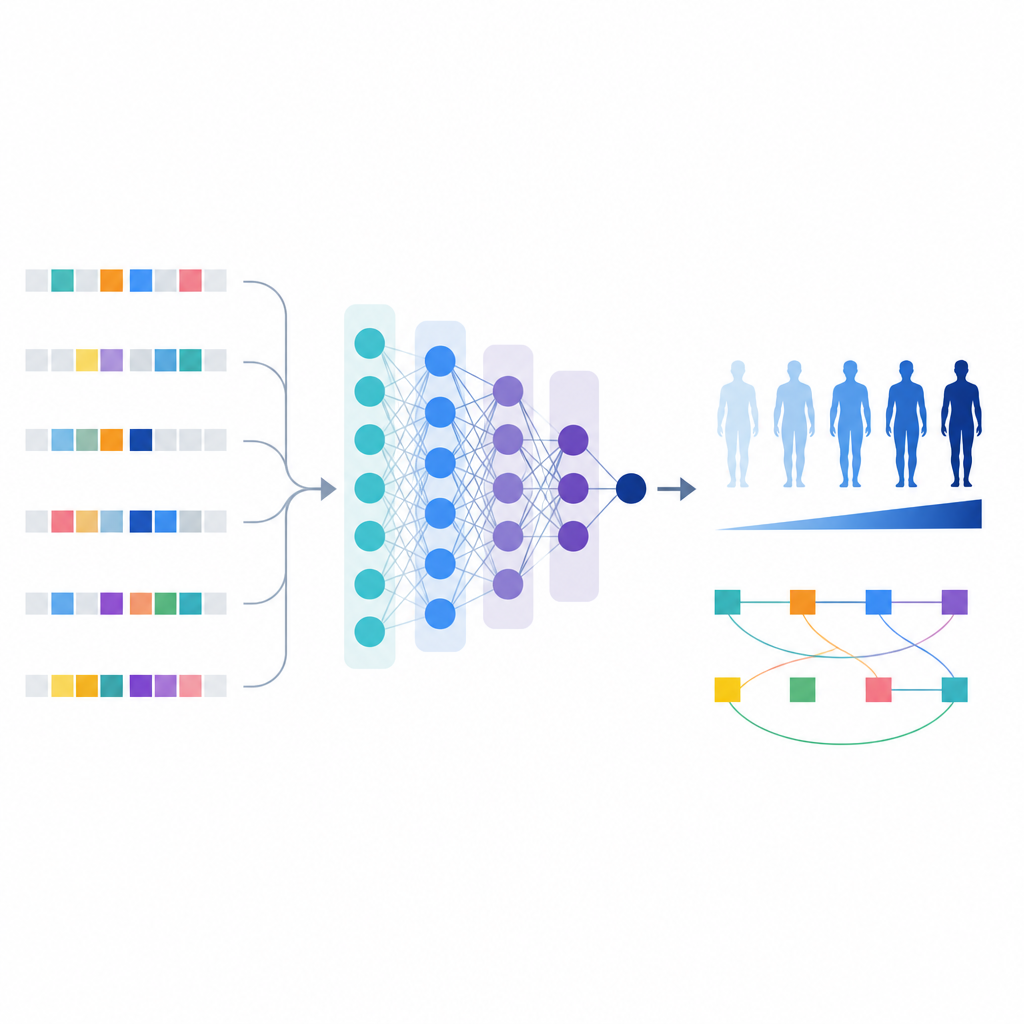
Vad de genetiska mönstren betyder för patienter
De genetiska underklustren kopplades till verkliga skillnader i sjukdomsförlopp. Personer i de MHC-drivna klustren tenderade att utveckla typ 1-diabetes i yngre ålder. De som tillhörde det pankreas-rika klustret fick sjukdomen senare men hade högre förekomst av komplikationer som njursjukdom, nervskador och hjärt-kärlproblem, trots att deras genomsnittliga blodsockerkontroll inte var sämre. Liknande mönster framträdde i en oberoende datamängd, vilket tyder på att genetiken kan hjälpa till att flagga patienter som kan behöva tätare uppföljning för komplikationer eller som kan svara olika på behandlingar.
Att föra in genetiken i vardaglig vård
Sammanfattningsvis visar detta arbete att en omsorgsfullt byggd genetisk riskmodell kan göra mer än att märka någon som "hög" eller "låg" risk. Den förbättrar diagnosen, särskilt hos personer med komplexa genetiska bakgrunder, belyser biologiska vägar värda att rikta in sig på i nya behandlingar och pekar på distinkta former av typ 1-diabetes som utvecklas olika över livet. Även om genetiken ensam inte kan förutsäga vem som kommer att utveckla sjukdomen förflyttar verktyg som T1GRS medicinen närmare användningen av ett enkelt DNA-test för att vägleda förebyggande, diagnostik och långsiktig hantering.
Citering: McGrail, C., Sears, T.J., Griffin, E.N. et al. Genetic association and machine learning improve the prediction of type 1 diabetes risk. Nat Genet 58, 1062–1072 (2026). https://doi.org/10.1038/s41588-026-02578-y
Nyckelord: typ 1-diabetes, genetisk riskscore, maskininlärning, autoimmun sjukdom, precisionmedicin