Clear Sky Science · es
Asociación genética y aprendizaje automático mejoran la predicción del riesgo de diabetes tipo 1
Por qué los genes importan en la diabetes tipo 1
La diabetes tipo 1 a menudo se percibe como algo que aparece de forma inesperada, especialmente en niños y adultos jóvenes. Pero bajo la superficie, las diferencias hereditarias en el ADN influyen fuertemente en quién tiene mayor riesgo. Este estudio muestra cómo combinar conjuntos de datos genéticos muy grandes con aprendizaje automático moderno puede afinar nuestra capacidad para estimar ese riesgo, diferenciar la diabetes tipo 1 de otras formas de diabetes y descubrir subtipos ocultos de la enfermedad que pueden requerir un cuidado distinto.
Buscar pistas de riesgo en todo el genoma
Los investigadores escanearon primero el ADN de más de 800.000 personas de ascendencia europea, incluyendo más de 20.000 con diabetes tipo 1 y casi 800.000 sin ella. Buscaron en todo el genoma pequeños cambios en el ADN que fueran más comunes en las personas con la enfermedad. Este trabajo confirmó 89 regiones genéticas previamente conocidas vinculadas a la diabetes tipo 1 y descubrió 8 nuevas. Muchas de estas regiones se sitúan cerca de genes implicados en el sistema inmune o en las células productoras de insulina del páncreas, ofreciendo nuevos puntos de partida para entender cómo se desarrolla la enfermedad.
Acercándose a las variantes clave de riesgo
Encontrar una región de riesgo en el genoma es solo el comienzo, porque cada región puede contener muchas variantes estrechamente vinculadas que viajan juntas. El equipo utilizó métodos de mapeo fino para reducir las variantes causales más probables en 97 regiones fuera del principal clúster de genes inmunes y en el potente Complejo Mayor de Histocompatibilidad, o CMH, en el cromosoma 6. En más de la mitad de estas regiones pudieron reducir los candidatos a 15 o menos variantes, y a veces a un único sospechoso principal. También descubrieron nuevas señales de riesgo dentro del CMH, incluidas variantes no codificantes que parecen alterar la regulación génica en células inmunitarias específicas, lo que sugiere rutas biológicas detalladas hacia la enfermedad.
Enseñar a un modelo a leer el riesgo genético
Con esta lista refinada de variantes, los científicos construyeron un modelo de aprendizaje automático llamado T1GRS que trata el genoma de un individuo como entrada y devuelve una puntuación que refleja su probabilidad de tener diabetes tipo 1. 
Interacciones ocultas y subtipos genéticos
A diferencia de las puntuaciones simples que solo suman efectos, el modelo de aprendizaje automático puede capturar interacciones entre variantes. Los autores usaron herramientas que explican el comportamiento del modelo para identificar 154 pares de variantes cuyo efecto combinado sobre el riesgo era más fuerte o más complejo que la suma de sus partes. 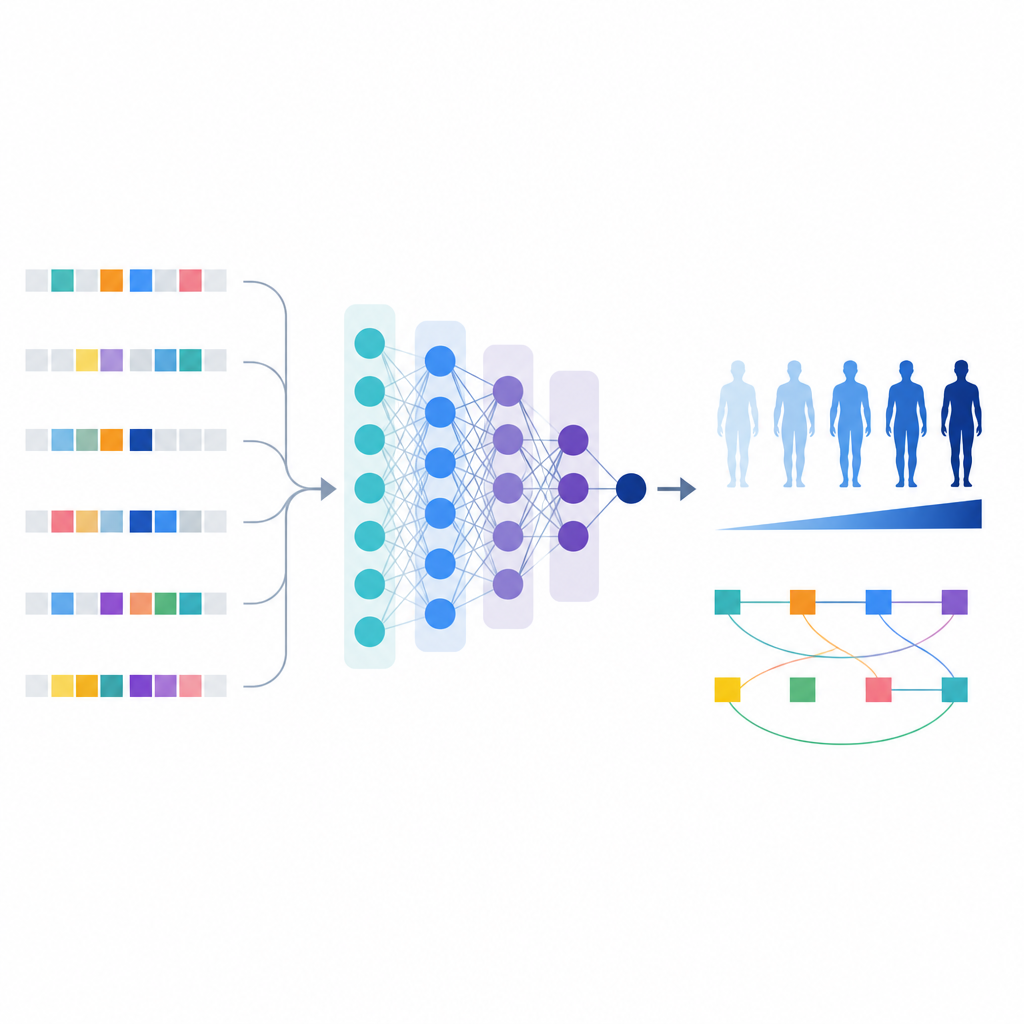
Qué significan los patrones genéticos para los pacientes
Los subgrupos genéticos se asociaron con diferencias reales en la evolución de la enfermedad. Las personas en los clústeres impulsados por el CMH tendían a desarrollar la diabetes tipo 1 a edades más tempranas. Las del clúster enriquecido en páncreas la desarrollaron más tarde pero presentaron tasas mayores de complicaciones como enfermedad renal, daño nervioso y problemas cardiovasculares, pese a que su control medio de glucemia no era peor. Patrones similares aparecieron en un conjunto de datos independiente, lo que sugiere que la genética puede ayudar a identificar pacientes que podrían necesitar un seguimiento más estrecho por complicaciones o que podrían responder de manera diferente a las terapias.
Incorporar la genética en la atención cotidiana
En conjunto, este trabajo muestra que un modelo de riesgo genético bien diseñado puede hacer más que etiquetar a alguien como de “alto” o “bajo” riesgo. Mejora el diagnóstico, especialmente en personas con antecedentes genéticos complejos, destaca vías biológicas que merecen ser objetivo de nuevos tratamientos y apunta a formas distintas de diabetes tipo 1 que se desarrollan de manera diferente a lo largo de la vida. Si bien la genética por sí sola no puede predecir quién desarrollará la enfermedad, herramientas como T1GRS acercan la medicina al uso de una simple prueba de ADN para guiar la prevención, el diagnóstico y el manejo a largo plazo.
Cita: McGrail, C., Sears, T.J., Griffin, E.N. et al. Genetic association and machine learning improve the prediction of type 1 diabetes risk. Nat Genet 58, 1062–1072 (2026). https://doi.org/10.1038/s41588-026-02578-y
Palabras clave: diabetes tipo 1, puntuación de riesgo genético, aprendizaje automático, enfermedad autoinmune, medicina de precisión