Clear Sky Science · en
Genetic association and machine learning improve the prediction of type 1 diabetes risk
Why genes matter for type 1 diabetes
Type 1 diabetes is often seen as striking out of the blue, especially in children and young adults. But beneath the surface, inherited differences in DNA strongly shape who is most at risk. This study shows how combining very large genetic datasets with modern machine learning can sharpen our ability to estimate that risk, separate type 1 from other forms of diabetes, and uncover hidden subtypes of the disease that may need different care.
Looking across the genome for risk clues
The researchers first scanned the DNA of more than 800,000 people of European ancestry, including over 20,000 with type 1 diabetes and nearly 800,000 without it. They searched the entire genome for tiny DNA changes that were more common in people with the disease. This effort confirmed 89 previously known genetic regions linked to type 1 diabetes and uncovered 8 new ones. Many of these regions sit near genes involved in the immune system or the insulin-producing cells of the pancreas, offering fresh starting points for understanding how the disease develops.
Zooming in on key risk variants
Finding a risky region in the genome is only the beginning, because each region can contain many closely linked variants that travel together. The team used fine-mapping methods to narrow down the most likely causal variants at 97 regions outside the main immune gene cluster and at the powerful Major Histocompatibility Complex, or MHC, on chromosome 6. At more than half of these regions they could reduce the candidates to 15 or fewer variants, and sometimes to a single leading suspect. They also discovered new risk signals within the MHC, including noncoding variants that seem to alter gene regulation in specific immune cells, hinting at detailed biological routes to disease.
Teaching a model to read genetic risk
With this refined list of variants, the scientists built a machine learning model called T1GRS that treats an individual’s genome as input and outputs a score reflecting their likelihood of having type 1 diabetes. 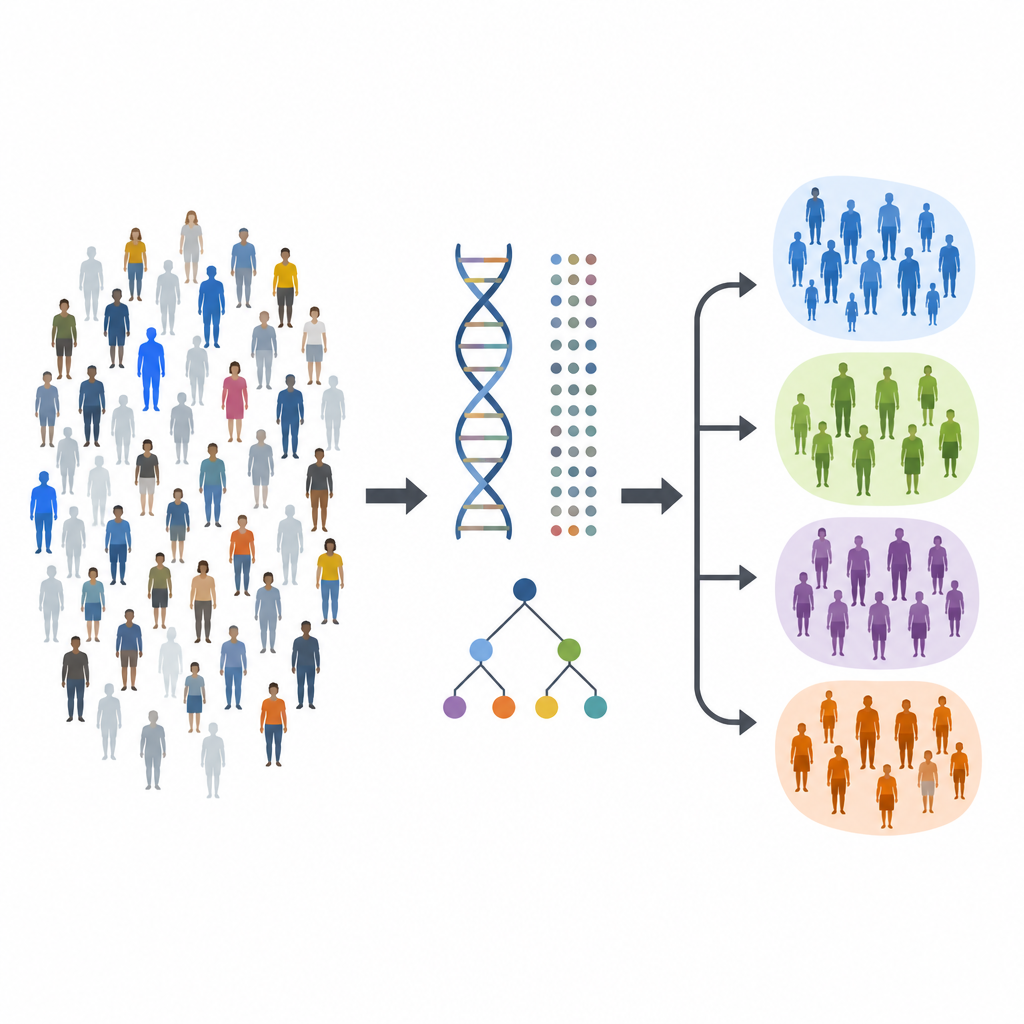
Hidden interactions and genetic subtypes
Unlike simple risk scores that just add up effects, the machine learning model can capture interactions between variants. The authors used tools that explain model behavior to identify 154 pairs of variants whose combined effect on risk was stronger or more complex than the sum of their parts. 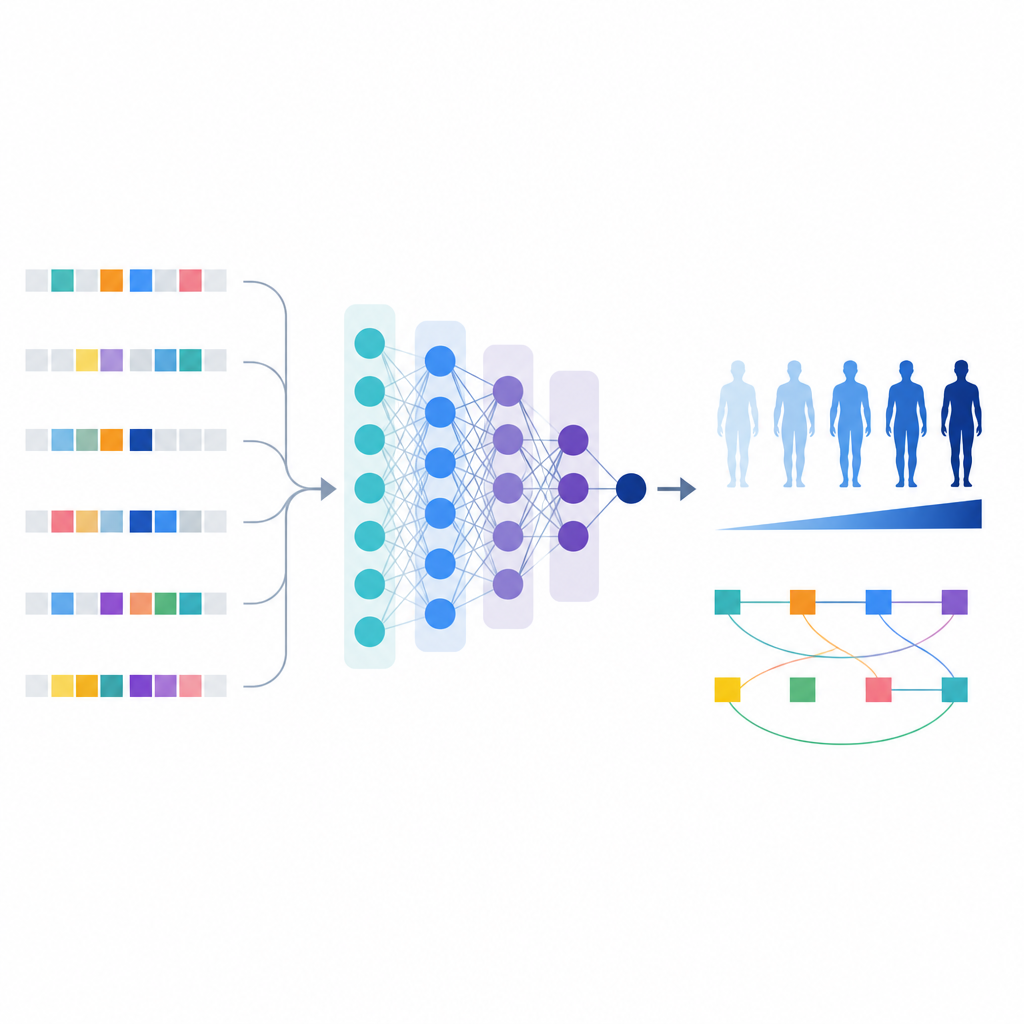
What the genetic patterns mean for patients
The genetic subclusters were linked to real-world differences in disease course. People in the MHC-driven clusters tended to develop type 1 diabetes at younger ages. Those in the pancreas-enriched cluster developed it later but had higher rates of complications such as kidney disease, nerve damage and cardiovascular problems, even though their average blood sugar control was not worse. Similar patterns appeared in an independent dataset, suggesting that genetics can help flag patients who might need closer monitoring for complications or who might respond differently to therapies.
Bringing genetics into everyday care
Overall, this work shows that a carefully built genetic risk model can do more than label someone as “high” or “low” risk. It improves diagnosis, especially in people with complex genetic backgrounds, highlights biological pathways worth targeting in new treatments, and points to distinct forms of type 1 diabetes that unfold differently over a lifetime. While genetics alone cannot predict who will develop the disease, tools like T1GRS move medicine closer to using a simple DNA test to guide prevention, diagnosis and long-term management.
Citation: McGrail, C., Sears, T.J., Griffin, E.N. et al. Genetic association and machine learning improve the prediction of type 1 diabetes risk. Nat Genet 58, 1062–1072 (2026). https://doi.org/10.1038/s41588-026-02578-y
Keywords: type 1 diabetes, genetic risk score, machine learning, autoimmune disease, precision medicine