Clear Sky Science · fr
Association génétique et apprentissage automatique améliorent la prédiction du risque de diabète de type 1
Pourquoi les gènes comptent pour le diabète de type 1
Le diabète de type 1 est souvent perçu comme survenant sans avertissement, surtout chez les enfants et les jeunes adultes. Mais sous la surface, des différences héréditaires dans l’ADN façonnent fortement qui est le plus exposé au risque. Cette étude montre comment la combinaison de très grands jeux de données génétiques et de l’apprentissage automatique moderne peut affiner notre capacité à estimer ce risque, à distinguer le type 1 d’autres formes de diabète et à dévoiler des sous-types cachés de la maladie qui pourraient nécessiter des soins différents.
Explorer le génome à la recherche d’indices de risque
Les chercheurs ont d’abord scanné l’ADN de plus de 800 000 personnes d’ascendance européenne, dont plus de 20 000 atteintes de diabète de type 1 et près de 800 000 pas concernées. Ils ont parcouru l’ensemble du génome à la recherche de petits changements d’ADN plus fréquents chez les personnes malades. Cet effort a confirmé 89 régions génétiques déjà connues liées au diabète de type 1 et en a révélé 8 nouvelles. Bon nombre de ces régions se situent près de gènes impliqués dans le système immunitaire ou dans les cellules productrices d’insuline du pancréas, offrant de nouveaux points de départ pour comprendre le développement de la maladie.
Se concentrer sur les variants de risque clés
Détecter une région à risque dans le génome n’est que le début, car chaque région peut contenir de nombreux variants étroitement liés qui se transmettent ensemble. L’équipe a utilisé des méthodes de « fine-mapping » pour restreindre les variants causaux les plus probables dans 97 régions en dehors du principal complexe de gènes immunitaires et au sein du puissant complexe majeur d’histocompatibilité, ou CMH, sur le chromosome 6. Dans plus de la moitié de ces régions, ils ont pu réduire les candidats à 15 variants ou moins, et parfois à un seul suspect principal. Ils ont également découvert de nouveaux signaux de risque au sein du CMH, y compris des variants non codants qui semblent modifier la régulation génique dans des cellules immunitaires spécifiques, suggérant des voies biologiques détaillées menant à la maladie.
Apprendre à un modèle à lire le risque génétique
Avec cette liste affinée de variants, les scientifiques ont construit un modèle d’apprentissage automatique appelé T1GRS qui traite le génome d’un individu en entrée et renvoie un score reflétant sa probabilité d’avoir un diabète de type 1. 
Interactions cachées et sous-types génétiques
Contrairement aux scores de risque simples qui se contentent d’additionner les effets, le modèle d’apprentissage automatique peut capturer des interactions entre variants. Les auteurs ont utilisé des outils expliquant le comportement du modèle pour identifier 154 paires de variants dont l’effet combiné sur le risque était plus fort ou plus complexe que la somme de leurs effets individuels. 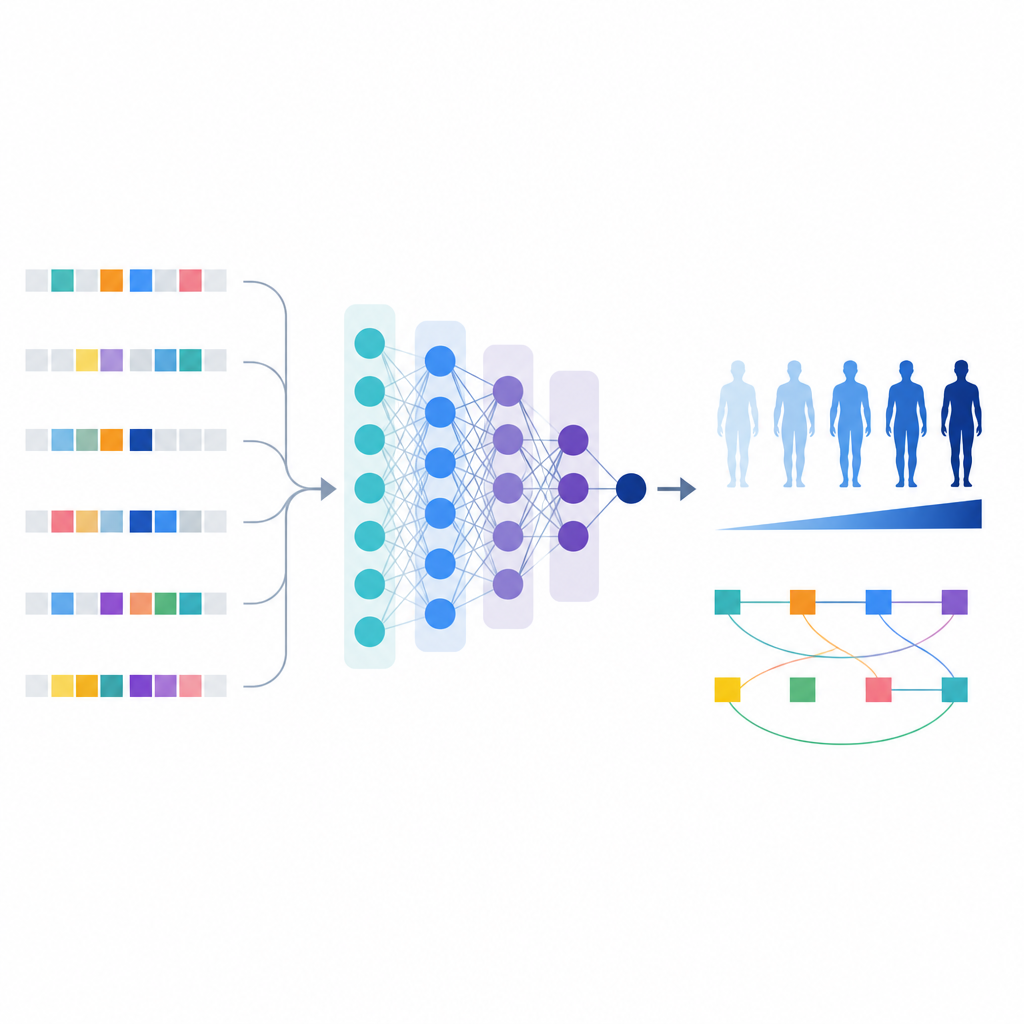
Ce que les schémas génétiques impliquent pour les patients
Les sous-amas génétiques étaient liés à des différences concrètes dans l’évolution de la maladie. Les personnes des groupes dominés par le CMH avaient tendance à développer le diabète de type 1 à des âges plus jeunes. Celles du groupe enrichi pour des gènes pancréatiques le développaient plus tard mais présentaient des taux plus élevés de complications telles que maladie rénale, neuropathie et problèmes cardiovasculaires, même si leur contrôle glycémique moyen n’était pas pire. Des schémas similaires sont apparus dans un jeu de données indépendant, suggérant que la génétique peut aider à repérer des patients qui pourraient nécessiter une surveillance plus étroite des complications ou qui pourraient répondre différemment aux thérapies.
Intégrer la génétique dans les soins quotidiens
Dans l’ensemble, ce travail montre qu’un modèle de risque génétique soigneusement construit peut faire plus que classer quelqu’un comme « à haut » ou « à faible » risque. Il améliore le diagnostic, notamment chez les personnes ayant des antécédents génétiques complexes, met en lumière des voies biologiques dignes d’être ciblées par de nouveaux traitements et indique des formes distinctes de diabète de type 1 qui évoluent différemment au fil de la vie. Si la génétique seule ne peut pas prédire qui développera la maladie, des outils comme T1GRS rapprochent la médecine d’un test ADN simple pour orienter la prévention, le diagnostic et la prise en charge à long terme.
Citation: McGrail, C., Sears, T.J., Griffin, E.N. et al. Genetic association and machine learning improve the prediction of type 1 diabetes risk. Nat Genet 58, 1062–1072 (2026). https://doi.org/10.1038/s41588-026-02578-y
Mots-clés: diabète de type 1, score de risque génétique, apprentissage automatique, maladie auto-immune, médecine de précision