Clear Sky Science · pl
Powiązania genetyczne i uczenie maszynowe poprawiają przewidywanie ryzyka cukrzycy typu 1
Dlaczego geny mają znaczenie w cukrzycy typu 1
Cukrzyca typu 1 często bywa postrzegana jako choroba pojawiająca się nagle, zwłaszcza u dzieci i młodych dorosłych. Jednak pod powierzchnią odziedziczone różnice w DNA silnie wpływają na to, kto jest najbardziej narażony. Badanie pokazuje, że połączenie bardzo dużych zestawów danych genetycznych z nowoczesnym uczeniem maszynowym może wyostrzyć naszą zdolność do oceny tego ryzyka, odróżnienia cukrzycy typu 1 od innych postaci cukrzycy oraz ujawnienia ukrytych podtypów choroby, które mogą wymagać innego podejścia terapeutycznego.
Przeszukiwanie genomu w poszukiwaniu śladów ryzyka
Naukowcy najpierw przeanalizowali DNA ponad 800 000 osób pochodzenia europejskiego, w tym ponad 20 000 z cukrzycą typu 1 i prawie 800 000 bez tej choroby. Przeszukiwali cały genom w poszukiwaniu drobnych zmian DNA częściej występujących u osób chorych. To przedsięwzięcie potwierdziło 89 wcześniej znanych regionów genetycznych związanych z cukrzycą typu 1 i wykryło 8 nowych. Wiele z tych regionów znajduje się w pobliżu genów zaangażowanych w układ odpornościowy lub komórki produkujące insulinę w trzustce, co daje nowe punkty wyjścia do zrozumienia mechanizmów rozwoju choroby.
Przybliżanie kluczowych wariantów ryzyka
Znalezisko ryzykownego regionu w genomie to dopiero początek, ponieważ każdy region może zawierać wiele blisko ze sobą sprzężonych wariantów. Zespół zastosował metody „fine-mappingu”, aby zawęzić najbardziej prawdopodobne warianty sprawcze w 97 regionach poza głównym skupiskiem genów odpornościowych oraz w potężnym kompleksie zgodności tkankowej MHC na chromosomie 6. W ponad połowie tych regionów udało się ograniczyć listę kandydatów do 15 lub mniej wariantów, a czasem do pojedynczego głównego podejrzanego. Odkryto też nowe sygnały ryzyka w obrębie MHC, w tym warianty niekodujące, które zdają się zmieniać regulację genów w określonych komórkach układu odpornościowego, sugerując szczegółowe biologiczne ścieżki prowadzące do choroby.
Nauczanie modelu rozumienia ryzyka genetycznego
Z tą uszczegółowioną listą wariantów naukowcy zbudowali model uczenia maszynowego nazwany T1GRS, który traktuje genom danej osoby jako dane wejściowe i zwraca wynik odzwierciedlający prawdopodobieństwo wystąpienia cukrzycy typu 1. 
Ukryte interakcje i genetyczne podtypy
W przeciwieństwie do prostych wyników ryzyka, które jedynie sumują efekty, model uczenia maszynowego potrafi wychwycić interakcje między wariantami. Autorzy użyli narzędzi wyjaśniających zachowanie modelu, aby zidentyfikować 154 pary wariantów, których łączny wpływ na ryzyko był silniejszy lub bardziej złożony niż suma ich pojedynczych efektów. 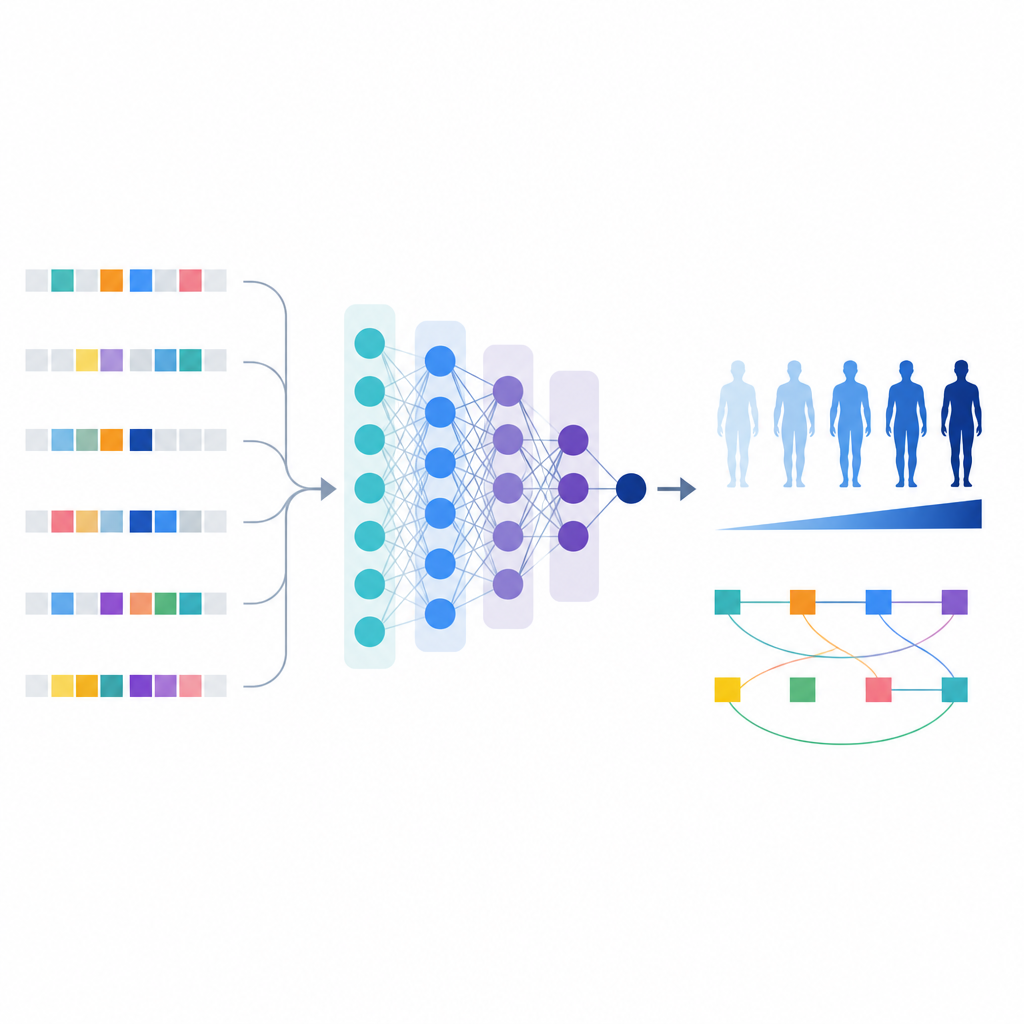
Co wzorce genetyczne znaczą dla pacjentów
Genetyczne podklastry wiązały się z rzeczywistymi różnicami w przebiegu choroby. Osoby w klastrach napędzanych przez MHC częściej rozwijały cukrzycę typu 1 w młodszym wieku. Ci z klastra wzbogaconego o geny trzustkowe rozwijali chorobę później, ale mieli wyższe wskaźniki powikłań, takich jak choroba nerek, uszkodzenia nerwów i problemy układu sercowo-naczyniowego, mimo że ich średnia kontrola glikemii nie była gorsza. Podobne wzorce pojawiły się w niezależnym zbiorze danych, co sugeruje, że genetyka może pomóc wskazać pacjentów wymagających bliższego monitorowania pod kątem powikłań lub takich, którzy mogą różnie odpowiadać na terapie.
Wprowadzanie genetyki do codziennej opieki
Podsumowując, praca ta pokazuje, że starannie zbudowany model ryzyka genetycznego może zrobić więcej niż tylko oznaczyć kogoś jako „wysokie” lub „niskie” ryzyko. Poprawia diagnostykę, zwłaszcza u osób o złożonym tle genetycznym, wskazuje ścieżki biologiczne warte celu dla nowych terapii i wytycza odrębne formy cukrzycy typu 1, które rozwijają się inaczej w ciągu życia. Chociaż sama genetyka nie potrafi przewidzieć, kto na pewno zachoruje, narzędzia takie jak T1GRS przybliżają medycynę do wykorzystania prostego testu DNA do kierowania prewencją, diagnozą i długoterminowym leczeniem.
Cytowanie: McGrail, C., Sears, T.J., Griffin, E.N. et al. Genetic association and machine learning improve the prediction of type 1 diabetes risk. Nat Genet 58, 1062–1072 (2026). https://doi.org/10.1038/s41588-026-02578-y
Słowa kluczowe: cukrzyca typu 1, genetyczny wynik ryzyka, uczenie maszynowe, choroba autoimmunologiczna, medycyna precyzyjna