Clear Sky Science · zh
在集成可重构光学张量处理器上进行深度神经网络推理
为什么更快的“思考”机器很重要
每次你用面部解锁手机、对语音助手说话或看到 AI 系统在视频中检测物体时,后台都会进行大量数值计算。随着这些人工智能模型变得更大、更强,它们对能量、硬件和时间的需求也随之增加。本文探讨了一类新的“光学大脑”,它用光而不仅仅是电来执行这些繁重的计算,旨在让未来的 AI 更快且更节能。
把光作为一种新的计算方式
现代 AI 由深度神经网络驱动,本质上是对称的数学运算在大型数字表格(张量)上重复应用。如今这些运算在诸如 GPU 的电子芯片上运行,但已接近速度和功耗的极限。作者转向光子学——在微小的片上结构中使用光——来执行这些相同的运算。由于光可以快速传播并同时在多个通道中并行传输,光学处理器原则上可以以极低的延迟并行完成大量计算,同时避免一些困扰传统电子学的能量损耗。
构建光驱动的数学引擎
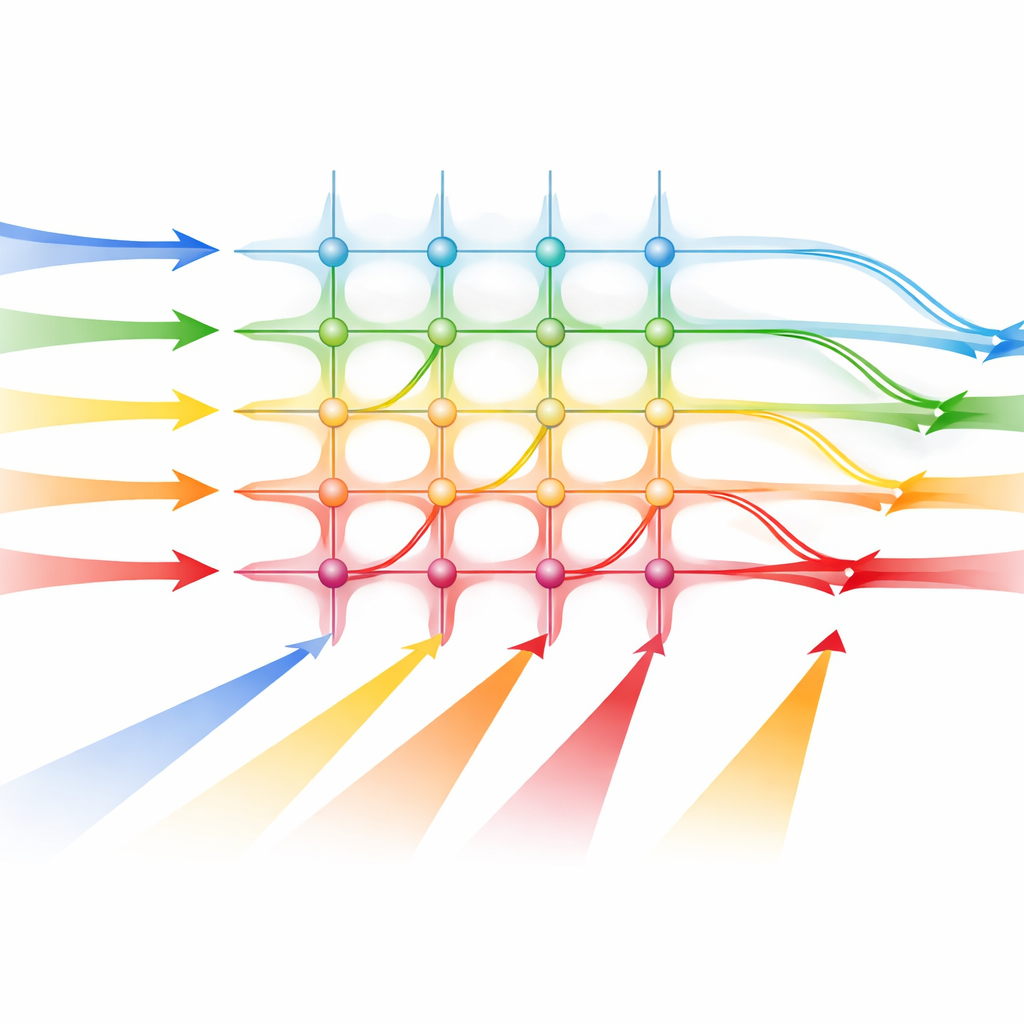
团队设计了一个可放入标准 19 英寸机架的光学张量处理器,使其看起来类似其他服务器硬件。其核心是使用工业制造工艺制成的硅光子芯片,这提高了此类设备未来批量生产的可能性。在这块芯片上,表示数据的入射电信号通过特殊调制器转换为光的模式。这些光信号随后通过一张由微小波导组成的网格传播,类似一张可调节的矩阵式连接,每个交叉点可以增强或衰减通过的光。在每列末端,内置光传感器将合并的光强转换回电信号,对应矩阵‑向量乘法的结果——这是许多神经网络层的核心操作。
保持光学稳定与数学精确
为给芯片供光,研究人员使用了一种称为微梳的先进光源,它同时产生许多均匀间隔的光色。每种颜色作为独立通道承载输入数据的一部分,使多重计算能够并行进行。然而,使用模拟光信号会引入噪声和不完美。作者通过精密校准来应对这一点:他们测量每个调制器和探测器的响应,然后调整控制电压和功率水平,使所需的数学权重对应到特定的光学设置。他们还补偿通道间的串扰以及光学封装引入的失真。在必要时通过对重复测量取平均,他们可以以牺牲少量时间为代价换取更高的精度。
用光运行真实的 AI 任务
为了证明他们的系统不仅仅是实验室玩具,团队将光学处理器直接连接到广泛使用的 AI 软件框架 PyTorch。他们在数字环境中训练了两个图像识别神经网络,然后在训练时模拟硬件可能引入的噪声进行微调。训练完成后,同样的网络无需为芯片重新设计就可以在光学处理器上运行。在简单的手写数字数据集 MNIST 上,光学系统在高精度模式下实现了约 98.1% 的准确率,在低延迟模式下为 91%,接近全数字基线。在更具挑战性的彩色图像数据集 CIFAR‑10 上,精度模式下达到 72% 的准确率——低于数字版本,但在更艰难的任务上仍展示了实用性能。
这对 AI 硬件的未来意味着什么
尽管当前原型在能效上不如最先进的电子加速器,但其大部分功耗花在了支持电子设备上,而非光学核心本身。结果表明,可编程、机架式的光学处理器可以完成真实神经网络中几乎所有繁重的线性代数运算,具有随时间稳定的性能以及在速度与精度间可调的权衡。随着技术扩展到更大的光学核心、更多波长和更好的转换器,这类基于光的张量处理器有望提供超快、低延迟的 AI 引擎,补充或在某些情况下分担传统芯片的工作,帮助未来系统更高效地应对不断增长的 AI 计算负载。
引用: Meyer, L., Dijkstra, J., Tebeck, S. et al. Deep neural network inference on an integrated, reconfigurable photonic tensor processor. Nat Commun 17, 3396 (2026). https://doi.org/10.1038/s41467-026-71599-2
关键词: 光子计算, 光学人工智能加速器, 深度神经网络, 硅光子学, 张量处理