Clear Sky Science · tr
Kapalı döngü, birlikte uyum sağlayan sinir arayüzlerinde insan–makine etkileşimlerini tahmin ve şekillendirmek için hesaplamalı çerçeve
Makinelere Bizimle Birlikte Öğrenmeyi Öğretmek
Beyin–bilgisayar arayüzleri ve gelişmiş protez uzuvlar laboratuvardan günlük yaşama doğru ilerlerken ortaya çıkan temel bir soru şudur: cihazları, onları kullanmayı öğrenirken aynı zamanda bizimle birlikte nasıl öğrenebilecek şekilde tasarlayabiliriz? Bu çalışma, hem insan kullanıcının hem de çözücü algoritmanın birbirine sürekli uyum sağladığı—kontrolün zaman içinde daha akıcı, daha doğal ve daha güvenilir hissetmesini sağlayan—"birlikte uyumlu" sinir arayüzleri için matematiksel ve deneysel bir çerçeve kurarak bu zorluğu ele alıyor. 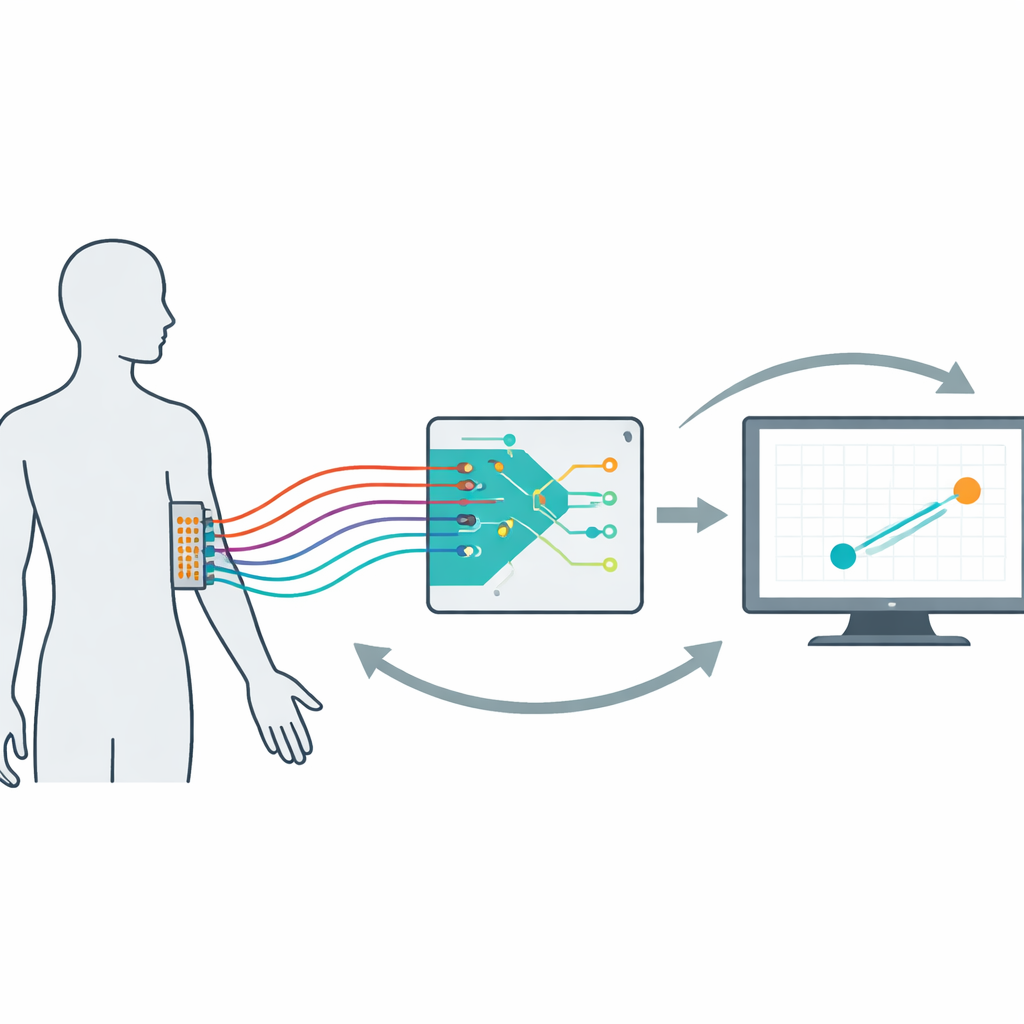
Yeni Bir İnsan–Makine Ortaklığı Türü
Birçok sinir arayüzü, kas veya beyin etkinliği gibi yüksek boyutlu biyolojik sinyalleri bir imleci veya robotik uzvu hareket ettirebilecek basit komutlara dönüştürerek çalışır. Geleneksel olarak tasarımcılar ya insan tarafını (kullanıcıyı sabit bir çözücüye uyum sağlaması için eğitmek) ya da makine tarafını (çoğunlukla sabit bir kullanıcı varsayarak çözücüyü güncellemek) optimize etmeye çalıştı. Gerçekte her iki taraf da sürekli öğreniyor. Bu iki öğrenenin bir arada bulunduğu yapı daha iyi performans ve kişiselleştirme sağlayabilir, ancak tasarımı daha zordur: eğer algoritma çok hızlı veya yanlış şekilde uyum sağlarsa kullanıcıyı yardımcı olmak yerine şaşırtabilir. Yazarlar, bu iç içe geçmiş öğrenme süreçlerini tanımlamak, tahmin etmek ve nihayetinde şekillendirmek için kontrol teorisi ve oyun teorisinden araçları bir araya getiriyor.
Birlikte Uyumlu Arayüzler için Güvenli Bir Deney Ortamı Kurmak
Bu dinamikleri kontrollü bir şekilde incelemek için araştırmacılar invaziv olmayan bir miyoelektrik arayüz oluşturdular. Ondört gönüllü baskın önkoluna 64 elektrottan oluşan bir ızgara taktı. Kas etkinlikleri ekrandaki gezinmekte olan bir hedefi takip etmesi gereken bir bilgisayar imlecini yönlendirdi. Gizliden, bir çözücü kas sinyallerini imleç hızına dönüştürdü ve son performansa dayanarak her 20 saniyede bir kendini güncelledi. Kişi başına 16 beş dakikalık deneme boyunca ekip, çözücünün öğrenme hızını, büyük sinyal kazançlarını kullanması nedeniyle nasıl cezalandırıldığını ("çaba"), ve başlangıç ayarlarını sistematik olarak değiştirdi. Davranış ve kas desenlerini inceleyerek kullanıcıların algoritmanın iyileşmesini sadece beklemediğini; denemeler içinde ve arasında kas kullanım biçimlerini aktif olarak değiştirdiklerini ve gerçek bir birlikte uyumlu insan–makine döngüsü yarattıklarını doğruladılar.
Döngünün İçini Görmek İçin Kontrol Teorisi Kullanımı
Bir sonraki adım, bu karmaşık etkileşimi ölçülebilir ve test edilebilir bir modele dönüştürmekti. Kontrol teorisinden fikirler kullanarak yazarlar her kullanıcının stratejisinin kompakt bir matematiksel tanımını—hedef ve imleç bilgilerini kas etkinliği desenlerine eşleyen bir "kodlayıcı"—tahmin ettiler. Bu kodlayıcı tahmin edilebilir, ileri beslemeli bir kısım ile düzeltici, geri beslemeli bir kısma ayrılabiliyordu. Tahmin edilen kodlayıcıyı bilinen çözücüyle birleştirerek, ekip tüm sistemin doğru ve kararlı kontrol yönünde olup olmadığını değerlendirebildi. Zamanla, kombinasyon halindeki kullanıcı–çözücü çiftinin, ne kullanıcı ne de çözücü tamamen sabit kalsa bile iyi izleme ve kararlılık sağlayacağı öngörülen değerlere doğru eğilim gösterdiğini buldular. Kullanıcılar ayrıca daha uzun vadeli öğrenme belirtileri sergiledi; yetkinleştikçe denemeler arasında kas eşlemeleri daha az kaydı.
Oyun Teorisi Öğrenme Kurallarının Davranışı Nasıl Şekillendirdiğini Ortaya Koyuyor
Açıklamanın ötesine geçip tasarım tercihleri birlikte uyuma nasıl etki eder tahmin etmek için yazarlar oyun teorisine başvurdular; bu disiplin, her karar vericinin kendi maliyetini minimize etmeye çalıştığı çoklu karar vericilerin etkileşimini inceler. Kullanıcıyı ve çözücüyü hem izleme hatasını azaltmaya önem veren hem de çaba için bir bedel ödeyen—kullanıcı için kas aktivasyonu, çözücü için büyük kazançlar—iki "oyuncu" olarak modellediler. Bu çerçevede ortak sistem, öğrenme hızlarına, çaba cezalarına ve başlangıç koşullarına bağlı olarak birkaç kararlı durumdan veya durağan noktadan birine yerleşebilir. Model somut öngörülerde bulundu: çözücünün öğrenme hızı sistemin ne kadar hızlı ve ne kadar iyi yakınsayacağını güçlü şekilde etkilemeli; çözücünün çaba cezasını ayarlamak kullanıcının yatırım yapması gereken çaba miktarını değiştirmeli ama doğrulukta mutlak bir değişiklik gerektirmeyebilir; ve çözücünün başlangıç ayarları kullanıcının nihai stratejisini hafifçe önyargılayabilir.
Algoritmaların İnsan Öğrenimini Nasıl Yönlendirdiğini Test Etmek
Deneyler büyük ölçüde bu öngörüleri doğruladı. Çözücü yavaş öğrendiğinde kullanıcılar bir deneme içinde daha fazla gelişti ve birleşik kodlayıcı–çözücü çifti doğru ve kararlı imleç kontrolü için teoride ideal rejime daha yakınlaştı. Çözücü çok hızlı adapte olduğunda performans kötüleşti ve kullanıcılar kas stratejilerini daha az değiştirdi; bu, makinenin insanların takip edebileceğinden daha hızlı hareket ettiğini gösteriyordu. Çözücünün çaba cezasını değiştirmek başka bir kontrol kolu sağladı: daha yüksek cezalar çözücüyü daha az çalışmaya zorladı ve bunun sonucunda birçok kullanıcı doğruluğu korumak için kendi kas çabalarını artırdı. İlginç bir şekilde katılımcılar çaba ile imleç hızı arasındaki dengeyi farklı biçimlerde kurdu—bazıları imleci hızlı tutmak için daha çok çalışmayı seçerken, diğerleri çabayı azaltmak için daha yavaş harekete razı oldu—bu da gelecekteki arayüzlerin bireysel tercihlere göre kişiselleştirilebileceğine işaret ediyor.
Geleceğin Sinir Arayüzleri İçin Anlamı
Basitçe söylemek gerekirse, bu çalışma sinir arayüzü algoritmalarına yerleştirilen eğitim kurallarının yalnızca gürültülü sinyalleri temizlemekten daha fazlasını yaptığını; insanların cihazı nasıl öğrenip kullandığını aktif olarak şekillendirdiğini gösteriyor. Titiz modelleme ile insan deneylerini birleştirerek yazarlar, çözücü öğrenme hızlarını, çaba cezalarını ve başlangıç ayarlarını rastgele denemeyle değil ilkeli bir şekilde seçmek için bir araç seti sağlıyor. Önerdikleri çerçeve, sadece doğru değil; aynı zamanda kararlı, konforlu ve her kullanıcının öğrenme tarzına göre uyarlanmış bir sonraki nesil protezler, rehabilitasyon araçları ve beyin–bilgisayar arayüzleri tasarımına rehberlik edebilir.
Atıf: Madduri, M.M., Yamagami, M., Li, S.J. et al. Computational framework to predict and shape human–machine interactions in closed-loop, co-adaptive neural interfaces. Nat Mach Intell 8, 372–387 (2026). https://doi.org/10.1038/s42256-026-01194-z
Anahtar kelimeler: sinir arayüzleri, insan makine etkileşimi, birlikte uyumlu kontrol, miyoelektrik imleç kontrolü, beyin-bilgisayar arayüzü tasarımı